来自新加坡国立大学、纽约大学和字节跳动的研究人员推出用于视频密集字幕生成的先进模型PLLaVA(Pooling LLaVA),此模型的主要功能是能够理解视频中的内容,包括动作、场景、人物穿着等,并能够生成详细描述这些内容的字幕。
- 项目主页:https://pllava.github.io
- GitHub:https://github.com/magic-research/PLLaVA
- 模型:https://huggingface.co/ermu2001/pllava-34b
- Demo:https://25656e6b153232cb72.gradio.live
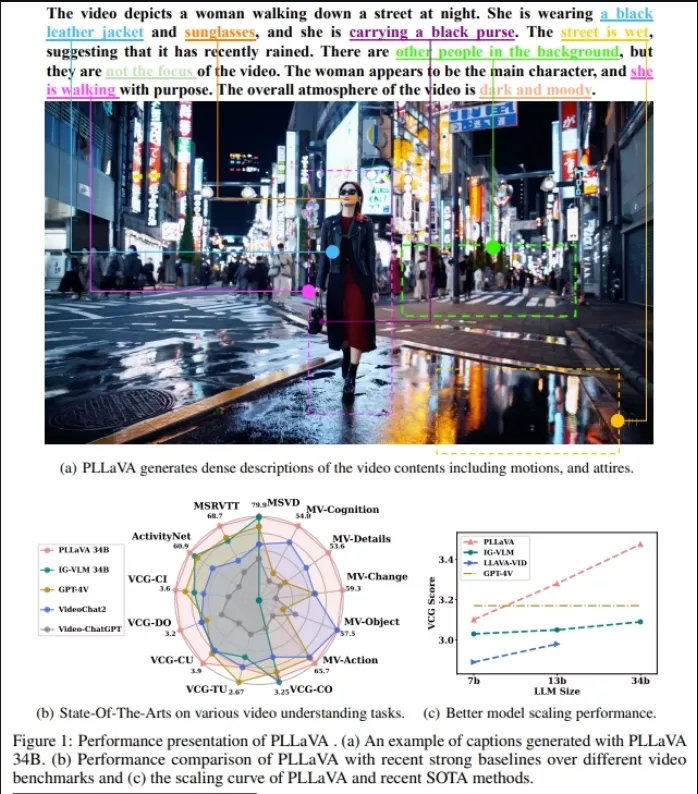
例如,你上传了一个夜晚街道上行走的女性的视频到PLLaVA模型。模型会分析视频中的视觉信息,比如女性穿着黑色皮夹克、戴着太阳镜、携带黑色手提包,以及街道是湿的,表明最近下过雨。然后,PLLaVA会生成一段描述性文字,比如:“视频描绘了一位女士在夜晚的街道上行走,她穿着黑色皮夹克和太阳镜,手里拿着一个黑色手提包。街道湿漉漉的,暗示着不久前下过雨。背景中还有其他人,但他们并不是视频的焦点。女士似乎是主角,她有目的地走着。视频的整体氛围是黑暗和忧郁的。”
主要功能:
- 视频内容理解:PLLaVA能够解析视频中的视觉信息,比如识别出视频中的人物、物体以及它们的动作。
- 密集字幕生成:模型能够生成与视频内容紧密相关的字幕,这些字幕不仅描述了发生了什么,还能捕捉到视频中的细节和动态变化。
主要特点:
- 无需额外参数:与其他需要大量计算资源和数据的视频语言模型不同,PLLaVA采用了一种资源消耗较少的方法。
- 高效的池化策略:通过在时间维度上进行池化(pooling),模型能够平滑特征分布,减少极端特征的影响,从而提高性能。
- 优异的性能:在多个视频理解基准测试中,PLLaVA都取得了新的最佳性能,尤其是在视频字幕生成任务上。
工作原理:
PLLaVA模型的工作原理可以概括为以下几个步骤:
- 视频帧编码:首先,模型使用预训练的视觉编码器(如CLIP-ViT)将视频帧编码成特征序列。
- 自适应池化:然后,模型通过一个无需参数的自适应池化模块来降低特征的时空维度,这样做有助于减少计算量并保持重要信息。
- 特征融合:池化后的特征与文本输入嵌入拼接,一起输入到大型语言模型(LLM)中。
- 生成响应:LLM根据输入的文本和视觉特征生成对视频内容的描述。
具体应用场景:
- 视频字幕生成:为社交媒体上分享的视频自动生成描述性字幕。
- 视频内容分析:在安全监控领域,分析视频内容以识别重要事件或异常行为。
- 教育和培训:为教育视频生成详细的字幕,帮助学习者更好地理解视频内容。
- 娱乐和媒体:在电影和电视节目的制作中,自动生成剧本或旁白。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











