
来自博世人工智能中心、曼海姆大学、马克斯·普朗克信息学研究所和图宾根大学的研究团队推出VSTAR,这是一种用于生成动态视频的文本到视频(T2V)合成技术。VSTAR的目标是解决现有开源T2V模型难以生成内容动态变化和较长视频的问题。这些模型往往只能生成静态或变化不大的视频,而VSTAR旨在改变这一现状。
为了应对这一挑战,团队引入了生成性时间护理(GTN)的概念,旨在在推理过程中实时调整生成过程,以更好地控制时间动态并生成更长的视频。研究团队提出了一种名为VSTAR的GTN方法,它包含两个关键要素:1)视频概要提示(VSP)——利用大语言模型(LLMs)根据原始单个提示自动生成视频概要,为更长视频的不同视觉状态提供准确的文本指导;2)时间注意力正则化(TAR)——一种正则化技术,用于优化预训练T2V扩散模型的时间注意力单元,从而实现对视频动态的控制。

通过实验展示了所提方法在生成比现有开源T2V模型更长、更具视觉吸引力的视频方面的优越性。此外,研究团队还分析了使用和不使用VSTAR的时间注意力图,证明了应用我们的方法对于缓解随时间变化的所需视觉变化被忽视的重要性。
主要功能:
- 生成动态视频: VSTAR能够根据文本提示生成包含动态变化的更长视频。
- 视频概要提示(VSP): 自动根据原始文本提示生成视频概要,为视频的不同视觉状态提供准确的文本指导。
- 时间注意力正则化(TAR): 通过调整预训练T2V模型的时间注意力单元来控制视频动态。
主要特点:
- 无需重新训练: VSTAR可以直接应用于预训练的T2V模型,无需重新训练,也不会增加计算开销。
- 单次传递生成: 使用单次传递生成视频,避免了多次传递带来的高开销。
- 改善视频动态: 通过分析和调整时间注意力机制,VSTAR能够改善视频的动态表现。
工作原理:VSTAR包含两个关键策略:视频概要提示(VSP)和时间注意力正则化(TAR)。
- 视频概要提示(VSP): 利用大型语言模型(如ChatGPT)将单一文本提示分解为描述视频主要事件的多个阶段,为每一帧提供更准确的视觉指导。
- 时间注意力正则化(TAR): 通过设计一个对称的Toeplitz矩阵并沿对角线方向应用高斯分布的值,来增强时间注意力层,从而鼓励视频中相邻帧之间的视觉变化。
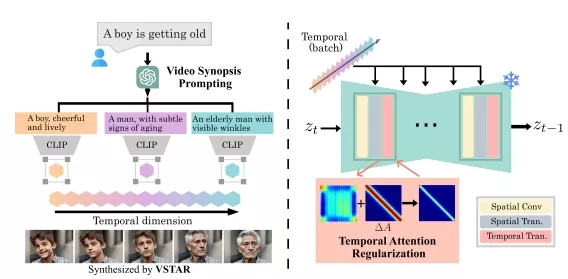
VSTAR是一个创新的视频生成方法,它通过改进现有的T2V模型,使得生成的视频内容更加丰富和动态,同时保持了生成过程的高效性和简洁性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











