来自香港中文大学、Avolution AI、上海人工智能实验室和商汤科技研究院的研究团队推出视频扩画方法MOTIA(Mastering Video Outpainting Through Input-Specific Adaptation),视频扩画是指在视频原有画面的基础上,生成并添加新的视频内容,使得视频能够适应不同的播放环境,例如不同的屏幕尺寸或长宽比。这个过程不仅要求生成的内容与原视频风格一致,还要保持画面的连贯性和时间上的一致性。
主要功能:
- 视频内容扩展: MOTIA能够在视频的可视区域之外生成新的内容,比如将一个窄屏视频转换成宽屏视频。
- 保持视频连贯性: 在扩展视频的同时,MOTIA能够保持视频帧之间的连贯性,以及每一帧内部的空间一致性。

主要特点:
- 适应性强: MOTIA能够处理不同类型、分辨率和长度的视频,具有很好的灵活性。
- 无需特定调整: 与其他需要大量特定数据集训练的方法不同,MOTIA不需要针对特定任务进行大量的调整。
- 结合数据特定模式和生成先验: MOTIA利用源视频的内在数据特定模式和图像/视频生成模型的先验知识,共同实现高质量的视频扩画。
工作原理:
MOTIA的工作流程分为两个阶段:输入特定适应和模式感知扩画。
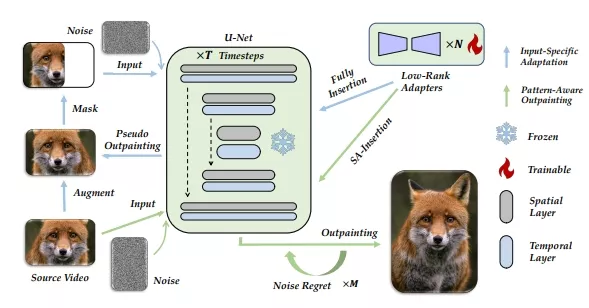
- 输入特定适应: 在这个阶段,MOTIA通过在源视频上进行伪扩画学习,有效地识别和学习源视频中的模式,同时缩小了标准生成过程与扩画之间的差距。
- 模式感知扩画: 在这个阶段,MOTIA结合从源视频中学到的模式和扩散模型的生成先验,进行有效的扩画。此外,MOTIA还提出了空间感知插入和噪声旅行等策略,以更好地利用扩散模型的生成先验和从源视频中获取的视频模式。
具体应用场景:
- 视频内容适配: 在电影院或网站上观看视频时,MOTIA可以将标准格式的视频调整为适应不同屏幕尺寸的视频,避免黑边的出现。
- 视频编辑和创作: 对于视频编辑者和创作者来说,MOTIA可以用来创造新的视频内容,或者在现有视频的基础上增加视觉效果。
- 视频数据增强: 在机器学习和数据分析中,MOTIA可以用来生成新的视频数据,用于训练和测试视频处理模型。
MOTIA是一个强大的视频扩画工具,它能够根据视频内容自动学习并生成新的内容,适用于多种视频处理和创作的场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











