
Snap Research、多伦多大学和向量研究所的研究人员推出多事件视频生成框架MinT(Mind the Time),它能够根据一系列文本提示和特定的时间戳生成具有精确时间控制的视频序列。MinT的核心特点是能够将每个事件绑定到视频中的特定时间段,从而使模型可以一次专注于一个事件,生成具有连贯性和细节丰富的视频内容。
例如,给定一系列文本提示:“一只猫在桌子上” → “跳到地板上” → “跳到沙发上” → “再次走回桌子” → “坐下四处张望”,MinT能够根据这些提示生成一个视频,其中每个动作都按照指定的顺序和时间发生。
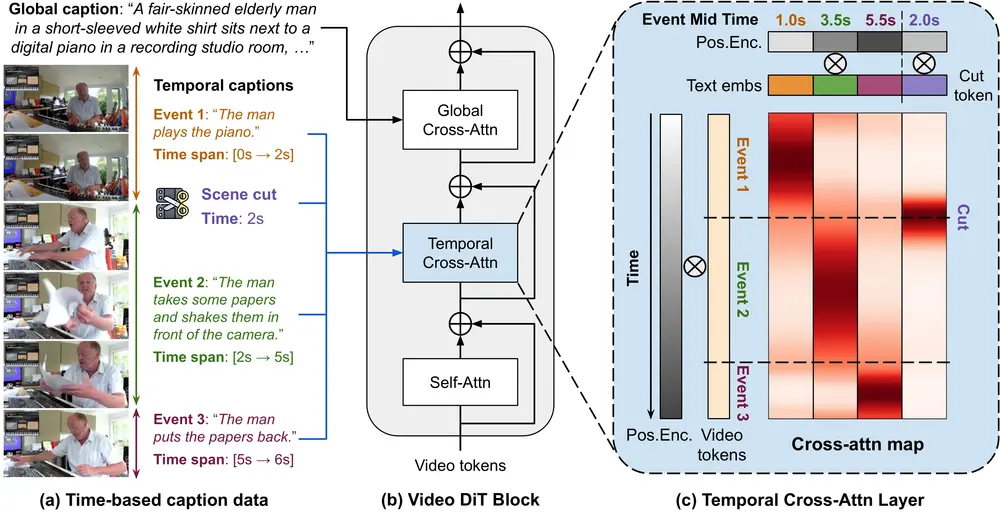
主要功能和特点
- 时间控制的多事件生成:MinT能够根据文本提示中的时间戳生成视频,精确控制每个事件的发生时间。
- 连贯性:视频事件之间能够平滑过渡,保持主题和背景的一致性。
- 细粒度控制:用户可以精细控制视频中每个事件的持续时间和顺序。
- 基于Transformer的架构:MinT基于预训练的视频扩散Transformer(DiT),利用Transformer架构的优势进行视频生成。
工作原理
MinT的工作原理包括以下几个关键步骤:
- 时间感知的交叉注意力:MinT设计了一种时间基的位置编码方法(ReRoPE),用于指导事件描述与视频令牌之间的交叉注意力操作,确保事件在视频中的正确时间范围内得到关注。
- 事件时间范围的绑定:每个文本提示都与一个特定的时间范围绑定,模型根据这些时间戳来生成视频内容。
- 迭代生成和修正:MinT通过迭代循环在生成(GENERATION)和重设计(REDESIGN)阶段之间交替执行,逐步验证和细化生成的视频。
- 场景切割条件:MinT能够学习场景切割的时间戳,从而在生成视频中控制镜头转换。
具体应用场景
MinT的应用场景包括但不限于:
- 电影和视频制作:用于生成电影预览、特效场景或故事板动画。
- 新闻和报道:快速生成新闻故事的视觉内容。
- 教育和培训:创建教育视频,模拟复杂的过程或历史事件。
- 娱乐和游戏:生成游戏内的动态场景或用于虚拟现实体验的动态背景。
- 广告和营销:根据产品特点或营销活动生成吸引人的视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











