厦门大学的研究人员推出新型多模态大语言模型INF-LLaVA,它专门设计用于处理高分辨率图像,以提高模型对视觉和语言信息的理解能力。在人工智能领域,处理高分辨率图像一直是一个挑战,因为这些图像包含的细节信息非常丰富,传统的模型可能无法捕捉到所有重要信息。INF-LLaVA通过创新的方法解决了这个问题,使得模型能够更有效地处理高分辨率图像。
- GitHub:https://github.com/WeihuangLin/INF-LLaVA
- 模型:https://huggingface.co/collections/WeihuangLin/inf-llava-669be442004e418e71fea201
例如,你是一名社交媒体内容创作者,你发布了一张高分辨率的旅行照片。使用INF-LLaVA模型,你可以请求模型为你的图片生成一个详细的描述,比如“一个穿着红色连衣裙的女孩在海边沙滩上奔跑,背后是蔚蓝的大海和金色的日落”。这个描述不仅捕捉到了图片中的主要对象(女孩、大海、日落),还包含了场景的氛围和情感,使得观众能够更好地理解和感受图片内容。此外,如果有人对图片提出问题,比如“女孩在哪里?”或者“图片中是什么时间?”INF-LLaVA也能够准确地回答这些问题。
主要功能
- 高分辨率图像处理:模型能够处理高分辨率图像,捕捉更多的细节信息。
- 双视角感知:通过局部和全局视角的结合,模型能够同时理解图像的细微之处和整体上下文。
主要特点
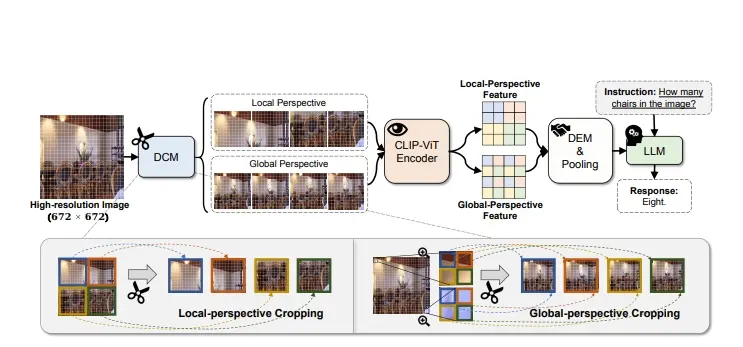
- 双视角裁剪模块(DCM):该模块将高分辨率图像从局部和全局两个视角分割成多个子图像,确保每个子图像既包含连续的局部细节,也包含全局信息。
- 双视角增强模块(DEM):该模块允许全局和局部特征之间的相互增强,通过资源高效的策略提高模型对细节和全局上下文的理解能力。
工作原理
- 图像分割:使用DCM将高分辨率图像分割成多个子图像,每个子图像从局部和全局视角捕捉不同的信息。
- 特征提取:将分割后的子图像通过预训练的视觉编码器提取视觉特征。
- 特征重组:根据二维位置先验信息,将局部和全局视角的子图像特征重新组合,形成高分辨率图像特征。
- 特征增强:通过DEM模块,将局部和全局特征进行交互和增强,生成双增强特征。
- 信息融合:将增强后的局部和全局特征融合,形成综合特征,这些特征既包含细节信息也包含全局上下文。
具体应用场景
- 图像描述生成:根据图像内容生成描述性文本,例如在社交媒体上自动生成图片描述。
- 视觉问答:回答有关图像内容的问题,如“图片中有多少人?”或“图片中的物体是什么颜色?”
- 图像内容分析:在安全监控、医学成像分析等领域,对图像内容进行深入分析和理解。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











