
WisdomAI
WisdomAI 提供 AI 驱动的数据分析,能够从结构化、非结构化和甚至“脏”数据(即未清理拼写错误或错误的数据)中回答业务问题。
Tavus 正式推出其 Conversational Video Interface(CVI)平台的下一个进化版本——一个完整的情感智能操作系统。该系统能够构建能够“看见、倾听、理解并参与”实时面对面交互的 AI 代理,由一系列新的 AI 模型提供支持:Phoenix-3、Raven-0 和 Sparrow-0。
自人类诞生以来,对话一直是改变世界的重要力量。Tavus 希望将人类对话的魅力和便捷性带入人机交互中。去年,Tavus 推出了全球最快的对话视频界面(CVI),让开发者能够构建实时对话视频体验。如今,Tavus 将这一技术推向新的高度,推出具备情感智能的 CVI 进化版。

CVI 的核心是三个新模型:Phoenix-3、Raven-0 和 Sparrow-0。它们协同工作,让 AI 视频对话栩栩如生。
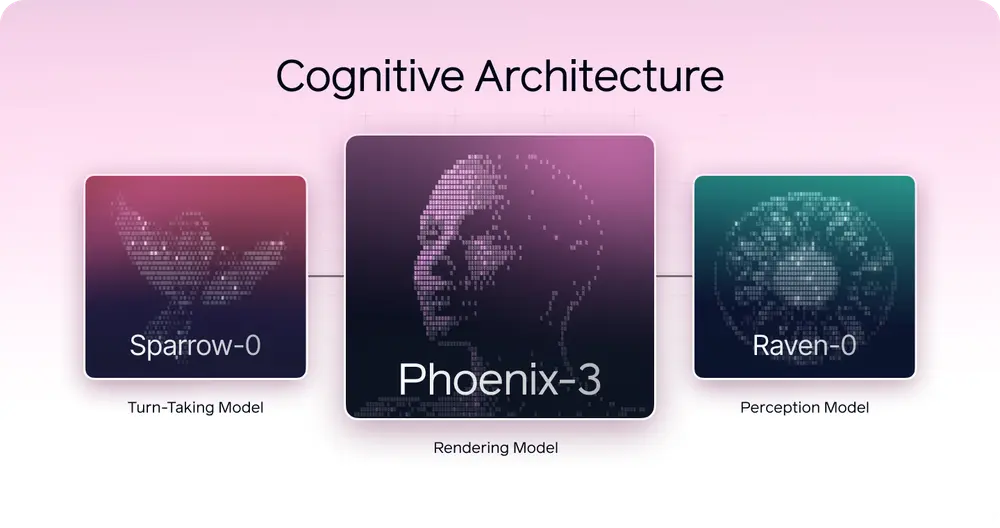
Phoenix-3 是一款突破性的高斯扩散渲染模型,能够为数字交互带来类人的表现力。它不仅关注嘴唇运动,还能动画化整个面部,包括眉毛、脸颊、眼睛和嘴巴,捕捉人类表情的全部范围。
Phoenix-3 通过专注于从中性到快乐等复杂细节,提供更加沉浸和真实的用户体验,使数字交互真正具有人性化。
Raven-0 是一种首创的感知系统,它不仅“看见”,还能“理解”。与传统视觉系统不同,Raven-0 能够处理连续的视觉输入,跟踪运动,并实时解读人类互动。
借助 Raven-0,AI 获得了真正的环境意识和情感智能,使交互更加流畅、响应迅速且类人。
Sparrow-0 基于 Transformer 的对话轮换引擎构建,能够理解节奏、意图和语速,确保无缝、类人的对话。
借助 Sparrow-0,AI 不再仅仅是反应——它会倾听、等待并在正确时刻响应,使每次交互都显得自然且毫不费力。
在 Tavus 的演示中,用户将遇见 Charlie——一个感觉不像聊天机器人,而更像新朋友的 AI 代理。Charlie 能够进行深思熟虑、栩栩如生的对话,理解上下文、意图和细微差别。
Charlie 的能力包括:
对于开发者来说,Charlie 的交互过程可以通过开发者模式记录,为扩展 Tavus 交互层提供蓝图,支持代理动作、函数调用以及超越对话的现实世界实用性。

通过简单的 API,开发者可以在几分钟内将实时、情感智能的 AI 助手嵌入他们的应用程序中。CVI 专为低延迟、实时视频构建,支持自然对话流程、情感适应性和开箱即用的全脸渲染。无论是用于 AI 驱动的辅导、客户支持,还是互动销售培训,Tavus CVI 都让构建类人 AI 变得轻而易举。













