
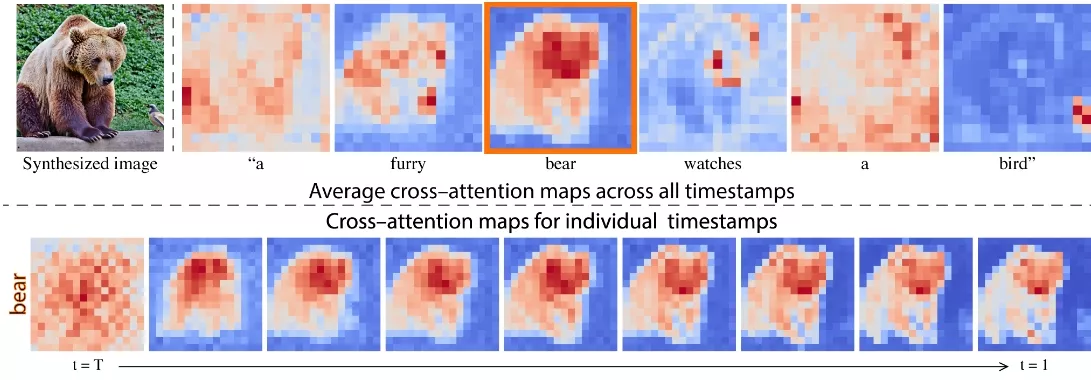
来自谷歌和特拉维夫大学的团队推出图像编辑技术Prompt-to-Prompt,这是一种直观的从提示到提示的编辑框架,其中编辑操作仅通过文本进行控制。此团队深入分析了文本条件模型,并观察到交叉注意力层在控制图像空间布局与提示中每个单词之间关系方面发挥着关键作用。
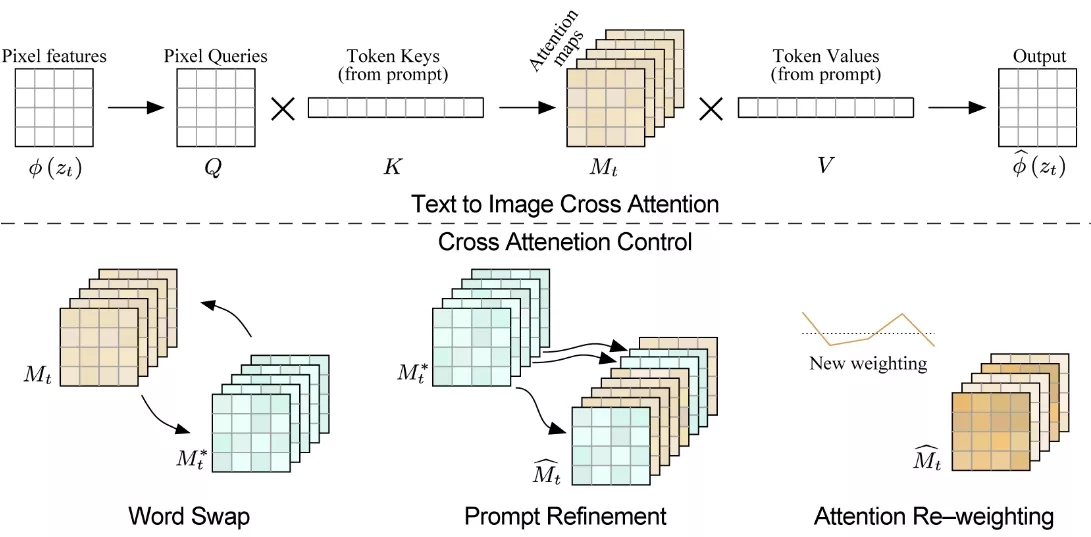
基于这一发现,他们提出了在扩散过程中注入原始图像的注意力图,以此来控制编辑图像的注意力分布。这一方法使此框架能够仅通过编辑文本提示来监控合成过程,从而为基于标题的编辑应用开辟了新的道路,例如通过替换单词进行局部编辑,通过添加说明进行全局编辑,甚至控制单词在图像中的反映程度。

这项技术通过简化图像编辑的过程,使得非专业人士也能够轻松地创建和修改复杂的图像内容。比如,你有一张由AI生成的图片,比如一幅画着城堡的风景画,而你想要改变城堡的风格或者添加一些细节,比如让城堡看起来更古老或者在画面中加入一只飞翔的鹰。传统的图像编辑方法可能需要你手动用鼠标和画笔来修改,而这项技术允许你仅仅通过改变描述图片的文字提示来实现这些改动。
主要功能和特点:
- 文本驱动的编辑: 用户不需要使用复杂的图像编辑工具,只需输入或修改文本提示,比如将“城堡”改为“古老的城堡”,AI就会根据新的文本提示来调整图像。
- 保持原有结构: 在编辑过程中,图像的原有结构和内容会被保留,只有指定的部分会根据文本提示进行修改。
- 直观的操作界面: 用户通过简单的文本输入来控制图像的编辑,无需进行复杂的图形选择或遮罩操作。
- 高质量合成: 该方法能够生成高质量的图像,并且与编辑后的文本提示保持高度一致。
工作原理:
这项技术基于深度学习模型,特别是文本条件扩散模型。模型通过分析文本提示中的每个词与图像中每个像素之间的关系(这种关系在论文中称为“交叉注意力”),来理解如何根据文本描述生成或修改图像。在编辑过程中,模型会参考原始图像的交叉注意力图,这些图谱显示了图像中的哪些部分与文本提示中的哪些词相关联。通过在生成过程中注入这些注意力图,模型可以在保持原始图像结构的同时,对指定的文本提示进行修改。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











