
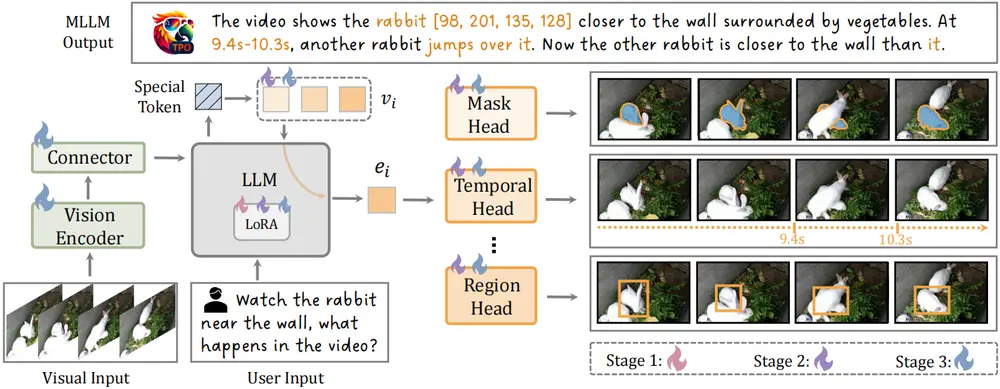
上海人工智能实验室、浙江大学、中国科学技术大学、上海交通大学、中国科学院深圳先进技术研究院和南京大学的研究人员推出一种名为任务偏好优化(Task Preference Optimization, TPO)的方法,它旨在通过视觉任务对齐来提升多模态大语言模型(MLLMs)的性能。TPO通过引入可学习的特定任务标记(task tokens),在不同的视觉任务头(task-specific heads)和MLLM之间建立联系,从而显著增强MLLM在多模态能力和特定任务性能方面的表现。

主要功能
TPO的主要功能包括:
- 增强视觉感知能力:通过不同视觉任务的优化,提升MLLM在图像和视频理解上的性能。
- 多任务协同训练:通过TPO,模型能够在多种视觉任务上进行协同训练,实现性能的相互提升。
- 零样本能力:TPO使得MLLM在各种任务上展现出强大的零样本性能,与监督模型相媲美。
主要特点
- 可学习的特定任务标记:TPO引入了可学习的任务标记,这些标记作为MLLM与特定任务头之间的桥梁。
- 多任务协同训练:TPO通过多任务训练,使得模型在不同视觉任务上的表现相互促进,提升了整体性能。
- 零样本性能:TPO优化后的MLLM在多种视觉任务上展现出与专家模型相当的性能。
工作原理
TPO的工作原理基于以下几个步骤:
- 任务识别:MLLM首先根据用户指令识别出所需的视觉任务。
- 任务头激活:识别出任务后,相应的任务头被激活,进行特定的视觉预测。
- 联合优化:MLLM和任务头一起训练,以提升模型对视觉任务的理解能力。
- 多任务训练:通过在多任务数据上的联合训练,TPO进一步提升模型的多模态性能和特定视觉任务的性能。
具体应用场景
TPO的应用场景包括但不限于:
- 个人助理:在个人助理应用中,TPO可以帮助模型更好地理解和执行与视觉相关的任务,如图像搜索、图像识别等。
- 视频内容分析:在视频内容分析领域,TPO可以用于提升视频理解能力,进行视频摘要、视频问答等。
- 科学发现:在科学研究中,TPO可以帮助模型分析实验视频,识别关键事件和模式。
- 交互式系统:在交互式系统中,TPO可以提升系统对用户视觉指令的响应能力,如导航、游戏等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











