来自香港大学、香港中文大学、香港科技大学的研究团队推出LaVi-Bridge,它能够将不同的语言模型和生成视觉模型结合起来,用于文本到图像的生成任务。通过利用LoRA和适配器技术,LaVi-Bridge提供了一种灵活且即插即用的方法,无需对原始的语言和视觉模型权重进行修改。
简单来说,LaVi-Bridge就像是一个桥梁,它可以让计算机根据用户输入的文字描述生成相应的图片。
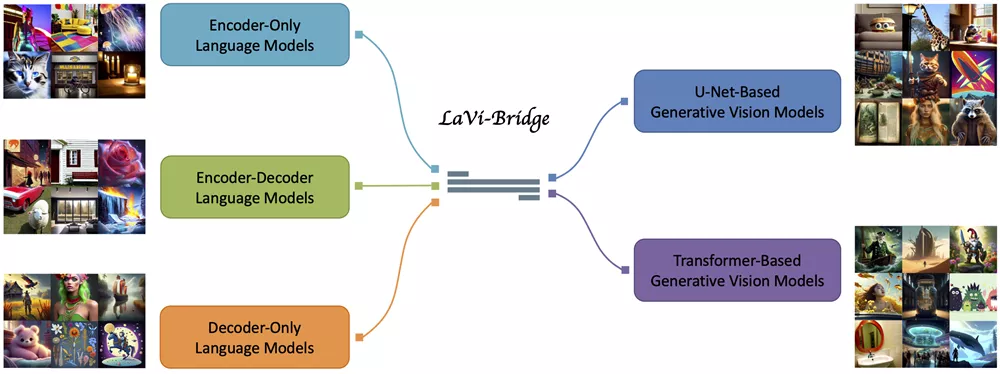
主要功能和特点:
- 灵活性:LaVi-Bridge能够与多种预训练的语言模型和生成视觉模型兼容,不需要修改这些模型原有的权重。
- 即插即用:通过使用LoRA(低秩适应)和适配器,LaVi-Bridge可以轻松地将不同的模型组件结合起来,而不需要复杂的设置或训练过程。
- 提升性能:结合更先进的语言模型或视觉模型可以显著提高生成图像的质量以及文本与图像的对齐程度。
工作原理:
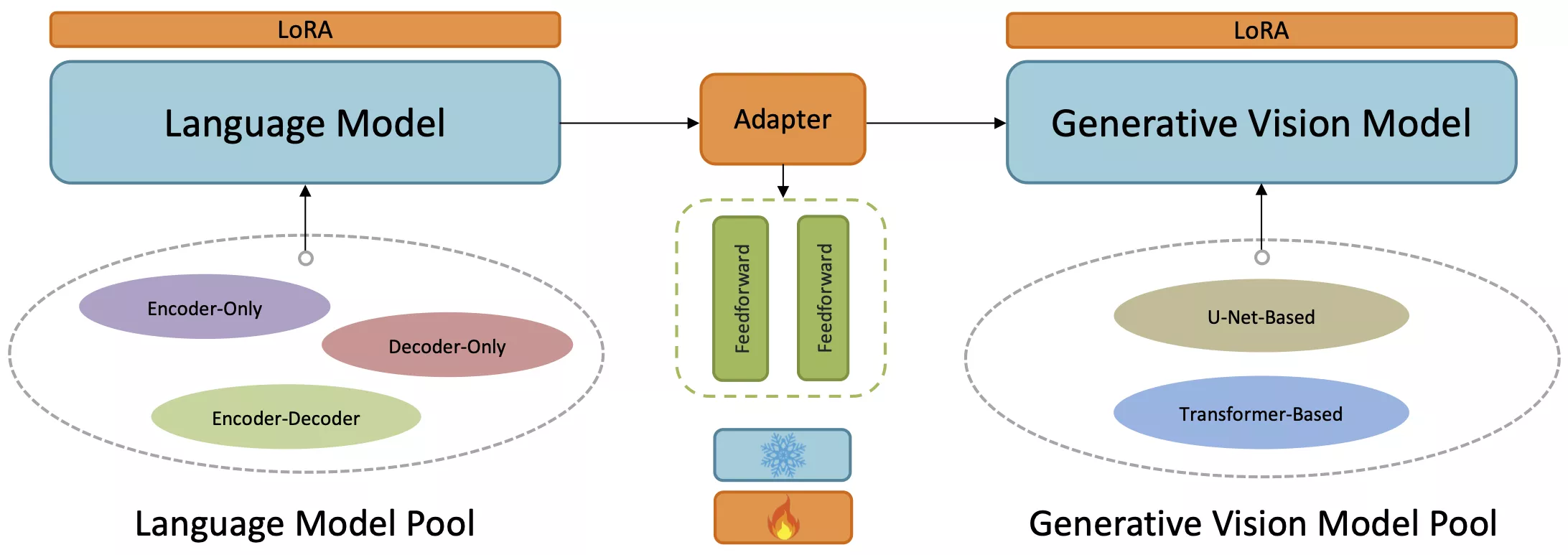
LaVi-Bridge的工作原理分为几个步骤:
- 模型选择:首先选择一个语言模型和一个视觉模型,这两个模型可以是任意预训练的模型。
- 注入LoRA:在语言模型和视觉模型中注入LoRA,增加可训练的参数。
- 使用适配器:通过一个适配器(由堆叠的前馈层组成)来桥接语言模型和视觉模型,解决它们之间维度不匹配的问题。
- 训练:在一个小规模的数据集上训练注入的LoRA参数和适配器,而不需要重新训练整个模型。
- 生成图像:训练完成后,用户可以输入文本描述,模型将生成与文本描述相匹配的图像。
具体应用场景:
- 内容创作:艺术家和设计师可以使用LaVi-Bridge根据描述生成图像,用于插画、广告设计等。
- 个性化推荐:根据用户的描述生成个性化的图片,如定制化的礼品或服装设计。
- 社交媒体:用户可以在社交媒体平台上输入描述,生成独特的图像内容。

LaVi-Bridge的提出,为文本到图像的生成任务提供了一个灵活且高效的方法,使得结合最新的语言理解和图像生成技术变得更加容易。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...