来自香港理工大学、OPPO、字节跳动的研究人员推出图像超分辨率技术SeeSR,它利用语义提示来增强预训练的文本到图像(T2I)扩散模型在处理现实世界图像超分辨率问题时的性能。这种方法特别关注于在图像质量严重受损时,如何保持生成的高分辨率(HR)图像的语义准确性。
相似技术:图像超分辨率技术StableSR
举例说明:假设我们有一张低分辨率的照片,上面有一只鸟在空中飞翔。如果使用传统的超分辨率技术,放大后鸟的翅膀可能会变得模糊不清,甚至看起来像是一朵云。但使用SeeSR方法,模型会识别出这是一只鸟,并且在放大翅膀时,会根据鸟的解剖结构和飞行姿态来恢复翅膀的细节,而不是简单地增加像素,这样放大后的图像就会更加真实和准确。
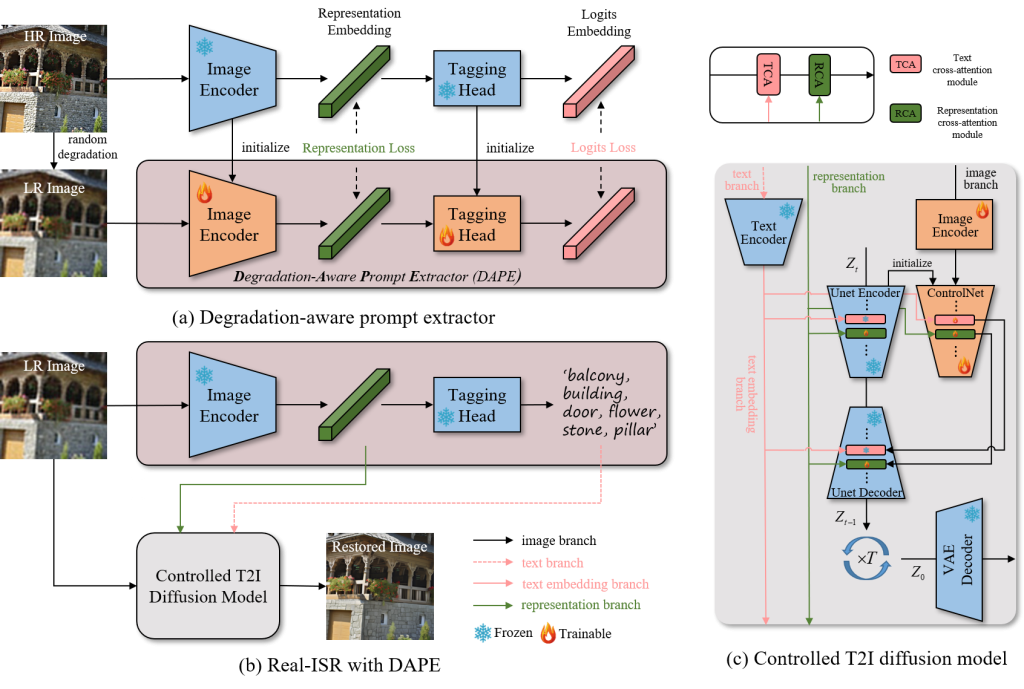
SeeSR的特别之处在于,它不仅提高了图像的清晰度,还确保图像的内容是准确的。它通过分析图像的语义信息,也就是图像中物体和场景的含义,来帮助模型更好地理解它正在处理的图像。这样做的好处是,模型在放大图像时,能够更智能地填充细节,而不是随意地添加像素,从而避免了产生不自然的或者错误的内容。
主要特点:
- 语义提示:SeeSR使用两种类型的语义提示(硬提示和软提示)来指导图像生成过程。硬提示是图像的标签,帮助模型理解图像的局部区域;软提示是图像的特征表示,提供额外的信息。
- 退化感知:SeeSR训练了一个退化感知的提示提取器(DAPE),即使在图像严重退化的情况下也能提取准确的语义信息。
- LR嵌入:在推理过程中,SeeSR将低分辨率(LR)图像嵌入到初始采样噪声中,以减少模型生成过多随机细节的倾向。

工作原理:
SeeSR的工作分为两个阶段:
在第一阶段,训练一个退化感知的提示提取器(DAPE),它能够从LR图像中提取软提示(特征表示)和硬提示(标签)。
在第二阶段,这些提示与LR图像结合,用来控制预训练的T2I模型,生成细节丰富且语义正确的HR图像。
在推理过程中,SeeSR还采用了LR嵌入策略,将LR图像的潜在表示直接嵌入到扩散过程的起点,以减少训练和推理之间的不一致性。
应用场景:
SeeSR可以应用于多种需要提高图像分辨率的场景,如老照片修复、监控视频增强、医学影像处理等。它特别适用于那些图像质量受到严重退化(如模糊、噪声等)的情况,能够生成更加真实和语义准确的高分辨率图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











