StableSR是来自南洋理工大学S实验室的研究人员开发的图像超分辨率技术,它可以将低分辨率的图像转换为高分辨率的图像。简单来说,这项技术可以让你看到的图片变得更加清晰和详细。
我们可以用一个生活中的例子来类比:想象一下你有一张打印出来的照片,但是这张照片很模糊,你看不清楚上面的细节。StableSR就像是一个神奇的工具,它能够分析这张模糊的照片,然后“猜测”出上面应该是什么细节,最后生成一张新的、更清晰的照片给你。
它利用预训练的文本到图像扩散模型中的先验知识,来实现盲超分辨率(SR),即在不知道图像如何被降低分辨率的情况下恢复高分辨率图像。
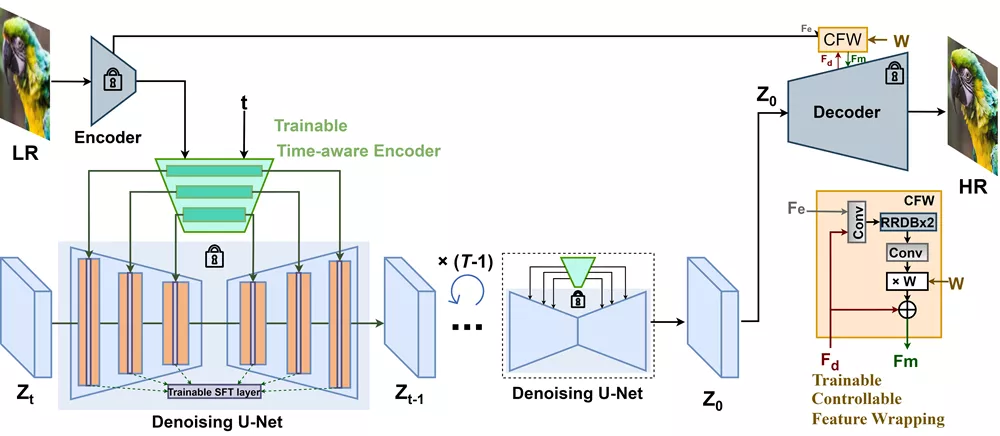
这种方法的核心在于,它不需要从头开始训练模型,而是通过微调一个轻量级的时间感知编码器和一些特征调制层,来适应超分辨率任务。这样做既保留了生成先验,又降低了训练成本。
主要特点:
- 时间感知编码器:通过时间嵌入层,编码器能够根据输入图像的特征动态调整条件强度,从而在生成过程中提供更精确的指导。
- 可控特征包装模块:允许用户通过调整一个标量值,在质量和保真度之间进行平衡,以适应不同的图像恢复需求。
- 渐进式聚合采样策略:通过将图像分割成重叠的小块,并在扩散迭代过程中逐步融合这些小块,解决了预训练扩散模型固定尺寸限制的问题,使得模型能够适应任意分辨率的图像。
工作原理:
StableSR首先使用时间感知编码器从低分辨率(LR)图像中提取多尺度特征,然后通过空间特征变换(SFT)层将这些特征与扩散模型的中间特征图相结合。在生成过程中,通过调整可控特征包装模块的系数,可以在生成逼真图像的同时保持高保真度。此外,为了处理大尺寸图像,StableSR采用了渐进式聚合采样策略,通过在扩散过程中逐步合并小块图像,生成连贯的高分辨率(HR)图像。
应用场景:
StableSR可以应用于多种场景,如图像编辑、视频增强、老照片修复等,特别是在处理真实世界图像时,它能够有效去除图像中的伪影并生成更真实的细节。此外,由于其灵活性,StableSR还可以用于特定的图像类型,如人脸图像的超分辨率,以及在需要高分辨率图像的任何应用中。
如何使用?
目前在Stable Diffusion WebUI和ComfyUI都有插件支持StableSR运行,不过小编不推荐大家在Stable Diffusion WebUI上尝试,该插件已长时间不更新,运行设置复杂,且经常爆显存,推荐大家在ComfyUI上运行StableSR。
可查看详细教程:Comfyui-StableSR:低分辨率图片无损放大与颜色修正
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











