
最近,OpenAI对GPT-4o 模型进行了升级,因其强大的图片生成与编辑能力引发了广泛关注,尤其是其将各种图片转换为吉卜力风格的功能,让这一风格转换功能在社交网络上迅速走红。

无论是特朗普的肖像、流行文化梗图,还是影视剧截图,这些图像都被转换成了充满梦幻色彩的吉卜力风格图像,吸引了大量用户的关注。(相关:OpenAI新GPT-4o模型掀起吉卜力风格AI图像热潮,此功能延迟对免费用户开放)

然而,由于版权等问题,ChatGPT 已经开始限制涉及版权的图片生成。不过,我们依然可以通过开源模型,在本地实现类似的图片风格转换,尽管操作的方便程度可能不如 GPT-4o。
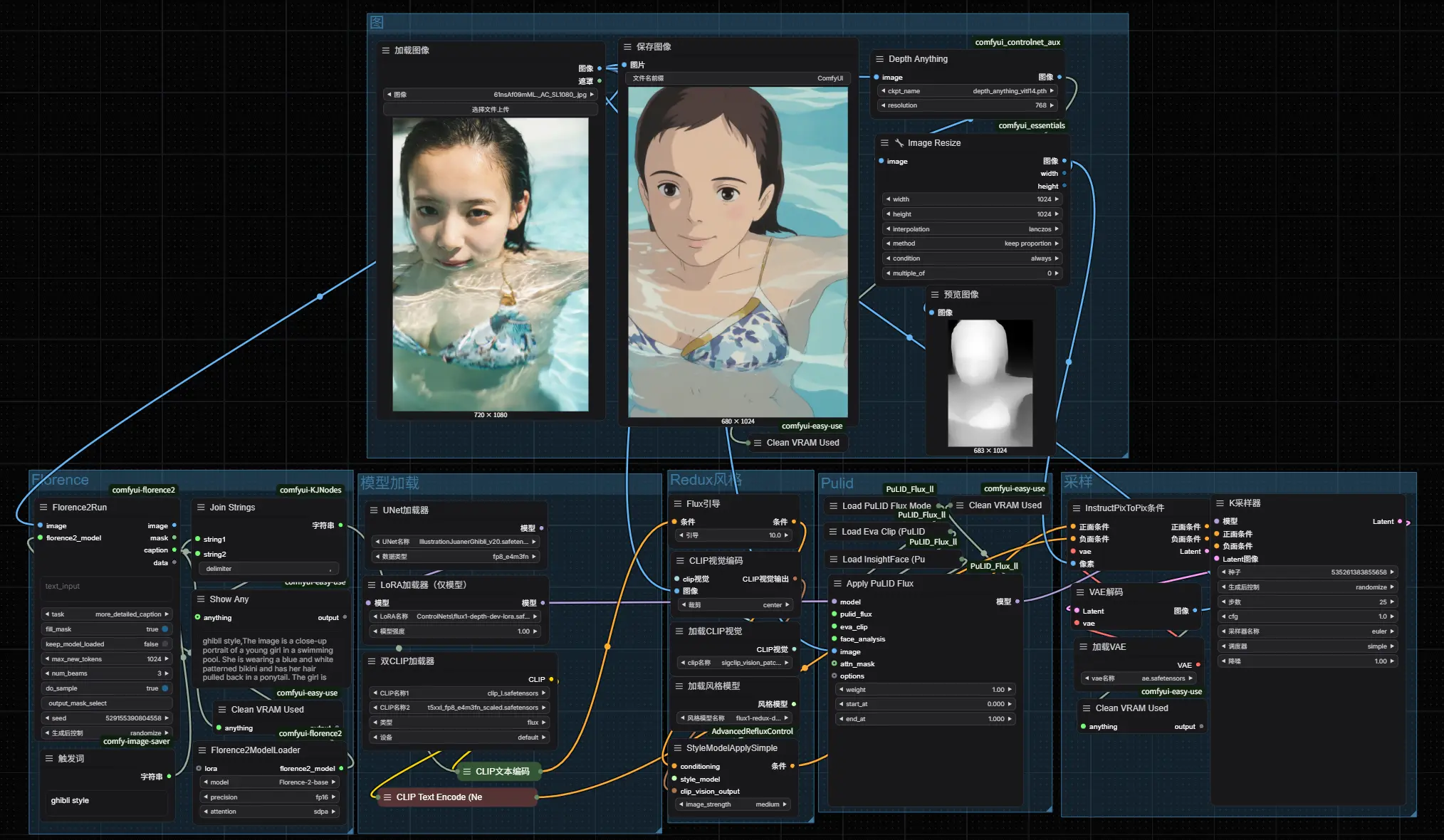


前提条件
要实现吉卜力风格转换工作流,需要满足以下条件:
1、 安装 ComfyUI:ComfyUI 是一个强大的开源工具,用于构建和运行复杂的 AI 图像生成工作流。国内用户推荐使用 B 站 UP 主秋叶的一键安装包,该安装包使用了国内代理或镜像,更适合国内网络环境。

2、 硬件要求:需要配备至少 12G 显存的英伟达显卡,以确保工作流的顺利运行。
3、 节点与模型:工作流主要使用 Florence2Run、ComfyUI_PuLID_Flux_ll 等节点。其他所需节点可通过 ComfyUI Manager 进行安装。
4、 模型选择:目前开源社区中有许多吉卜力风格的 Flux Lora 模型,但效果参差不齐。目前效果最好的是一款微调的 Flux 大模型,虽然模型较大,但已经上传到国内网盘,方便用户下载。
- 模型及工作流下载:https://www.123865.com/s/hyQyTd-8LhDv 提取码:hez3
| 模型 | 存放点 |
| IllustrationJuanerGhibli_v20.safetensors | ComfyUI\models\unet |
| flux1-depth-dev-lora.safetensors | ComfyUI\models\loras\ControlNets |
| pulid_flux_v0.9.1.safetensors | ComfyUI\models\pulid |
| flux1-redux-dev.safetensors | ComfyUI\models\style_models |
| sigclip_vision_patch14_384.safetensors | ComfyUI\models\clip_vision |
| clip_l.safetensors | ComfyUI\models\clip |
| depth_anything_vitl14.pth | custom_nodes\comfyui_controlnet_aux\ckpts\LiheYoung\Depth-Anything\checkpoints |
| ae.safetensors | ComfyUI\models\vae |
如何使用
下载与安装
1、 下载工作流:将工作流文件下载到本地。
2、 安装节点和模型:将工作流拖入 ComfyUI,系统会自动检测并提示安装缺失的节点和模型。通过 ComfyUI Manager 进行安装节点,缺失的模型可在网盘里寻找。
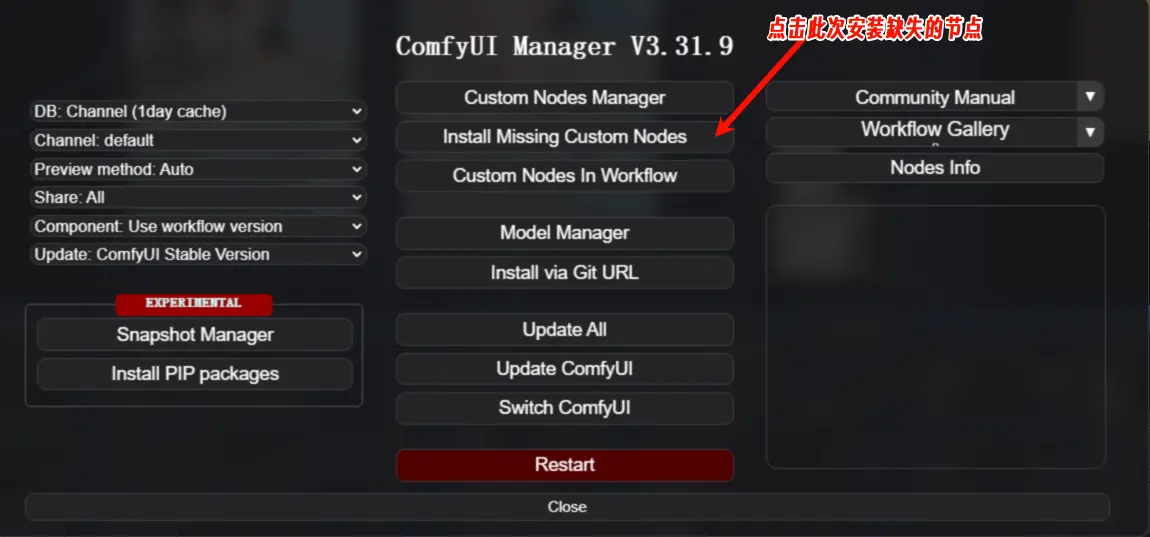
3、 上传图片:将需要转换的图片上传到工作流中。
4、 运行工作流:点击运行按钮,开始生成吉卜力风格的图片。

工作流流程说明
以本人的RTX 4070显卡为例,生成一张图片大约需要2分30秒。整个过程包括图片上传、使用Controlnet模型生成深度图、借助Florence2完成图片描述与提示词合并、通过Redux模型执行风格迁移以及PuLID模型负责面部迁移,最终生成图像。
图片上传:将原始图片输入到工作流中。 深度图生成:使用 Controlnet 模型生成图片的深度图。
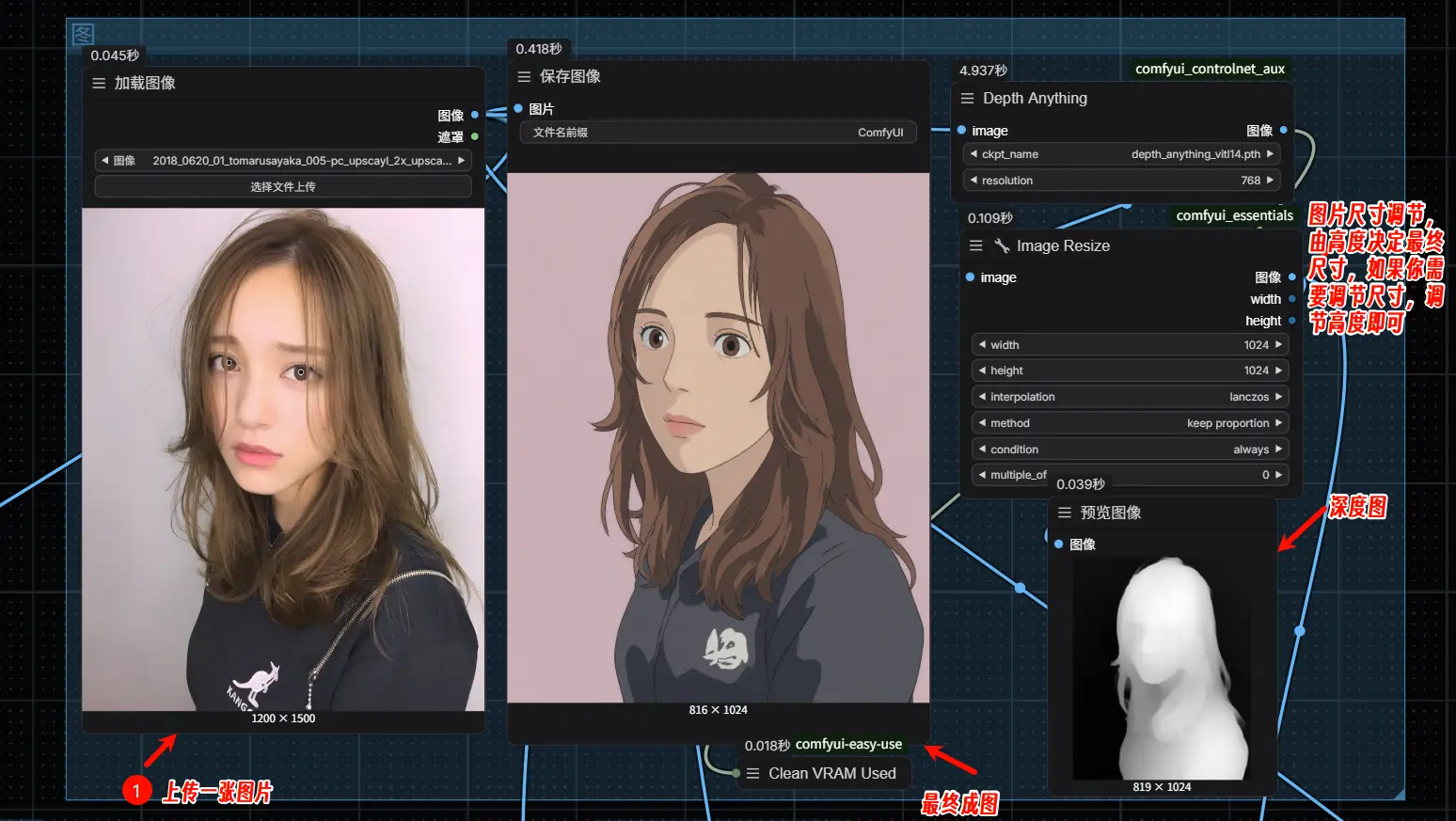
图片描述生成及提示词合并:通过 Florence2 模型生成图片描述并合并提示词。

风格迁移:使用 Redux 模型将图片转换为吉卜力风格。
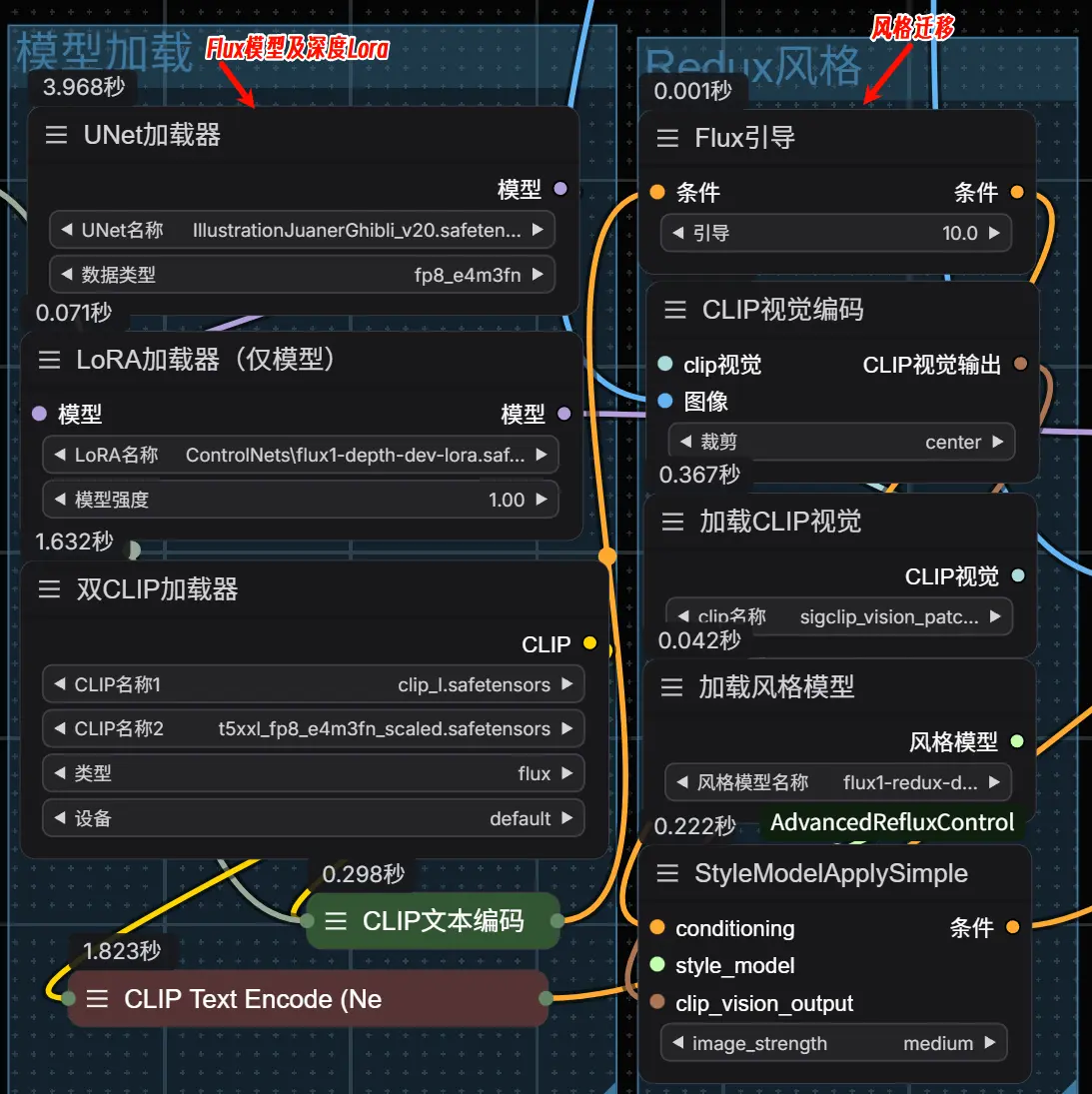
面部迁移:通过 PuLID 模型对人物面部进行风格化处理。 图像生成:最终生成吉卜力风格的图片。

工作流小问题及解决方法
显存占用问题:此工作流对显存要求较高,至少需要 12G 显存。如果显存不足,可以通过释放节点和模型占用的显存来解决。 生成速度优化:可以通过添加 WaveSpeed、TeaCache 等节点来加速生成速度。 爆显存问题:多次生成时可能会遇到爆显存或最后一步无法生成的问题。解决方法是释放节点和模型占用的显存,然后重新运行。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章














想问一下为什么用宽度大于高度的图片能正常出图,高度大于宽度的细长的图片就会报错,请问怎么调整才能不报错呢
尺寸调整是以高度为准的,你在Image Resize调整尺寸那里做相应调整就行
我找到原因了,原始图像长宽不是8的倍数就会报错,在加载图像后面加一个image resize的节点,multiple_of设置成8就可以了