新在 ComfyUI 中解锁无限可能:Qwen3.5 去拒斥模型(FP8/NVFP4)实战指南还在为 AI 助手频繁拒绝生成提示词而烦恼?想要一个能直接在 ComfyUI 工作流中理解图像、编写复杂 Prompt 且不受审查限制的本地大脑? 开发者 Winnougan 最新发布了基于 Qwen...工作流# ComfyUI# Qwen3.511小时前050
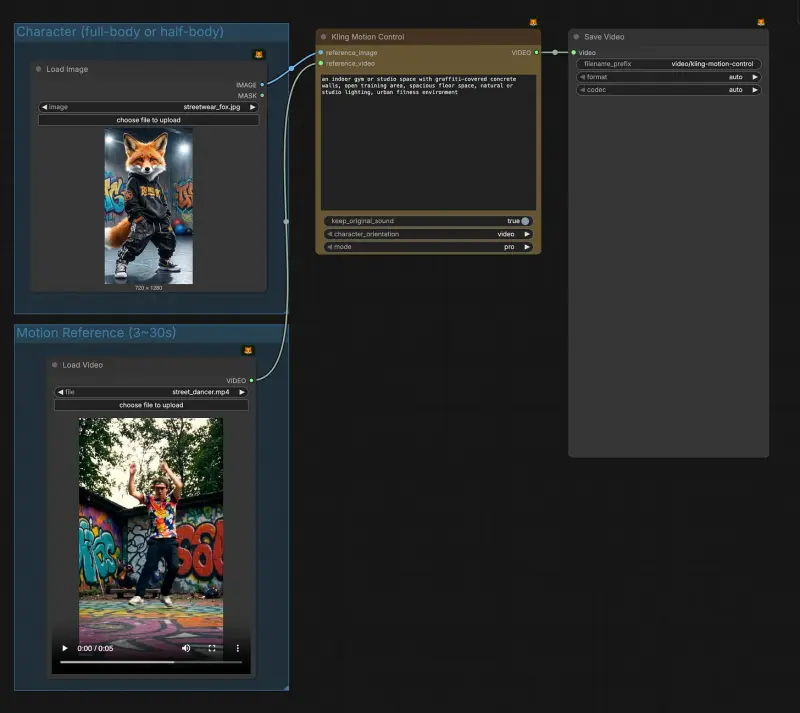
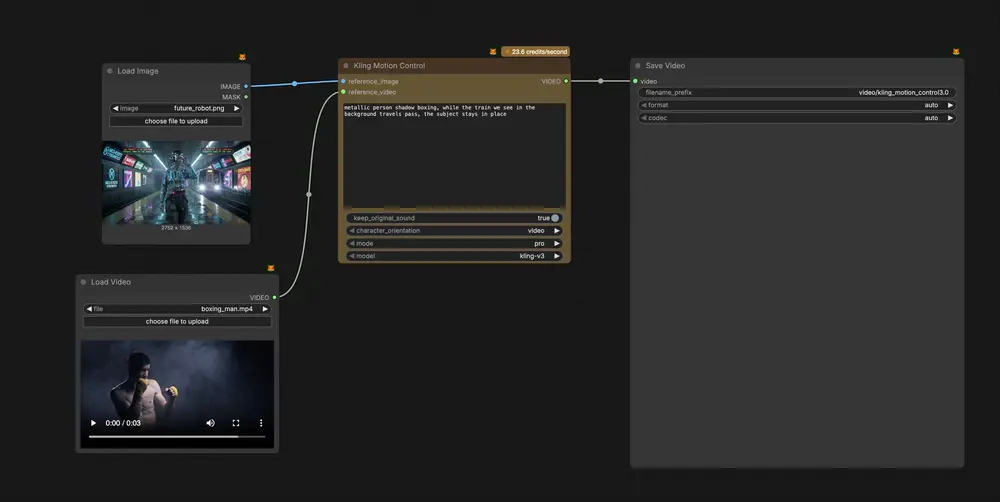
Kling 3.0 运动控制登陆 ComfyUI:告别“换脸”灾难,角色一致性迎来终极解决方案ComfyUI 官方正式宣布:Kling 运动控制 3.0 (Kling Motion Control 3.0) 现已通过合作伙伴节点全面接入 ComfyUI!此次更新基于备受赞誉的 2.6 版本,此...工作流# ComfyUI# Kling 3.0# 运动控制4周前01050
ComfyUI 原生支持 LTX-2.3:开源音视频生成的画质新标杆ComfyUI 官方正式宣布:Lightricks 最新开源模型 LTX-2.3 现已获得原生支持! 这意味着全球数百万 ComfyUI 用户现在可以直接在工作流中调用这一经过全面进化的音视频生成引擎...工作流# ComfyUI# LTX-2.3# 视频模型4周前02220
ComfyUI 官方图像与视频放大指南:10 大场景、20 种工作流全解析在 AI 图像与视频创作中,超分放大已经成为仅次于内容生成的核心刚需。无论是商业交付、印刷出版、影视后期、电商展示还是游戏素材,最终输出都离不开高质量、高分辨率的精细化处理。 ComfyUI 凭借本地...工作流# ComfyUI# 放大2个月前01260
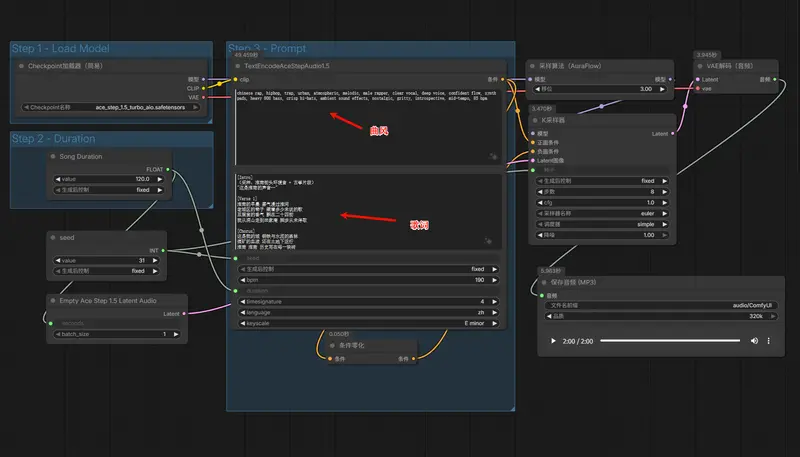
ACE-Step 1.5正式登陆ComfyUI:4GB显存跑商用级音乐生成,消费级硬件10秒出完整歌曲ComfyUI已全面适配ACE-Step 1.5!这款兼具商用级质量、极速生成、低硬件门槛的开源音乐基础模型,落地可视化工作流后进一步降低使用门槛,让普通用户在消费级硬件上,就能轻松实现10秒生成完整...工作流# ACE-Step 1.5# ComfyUI2个月前04030
Grok Imagine 正式登陆 ComfyUI:支持图像与视频生成的 xAI 模型现已可用来自 xAI 的电影感、氛围感图像与视频生成模型,正式以官方合作节点形式入驻 ComfyUI。 ComfyUI 官方宣布,xAI 旗下的 grok-imagine-image 与 grok-imagi...工作流# grok imagine2个月前01490
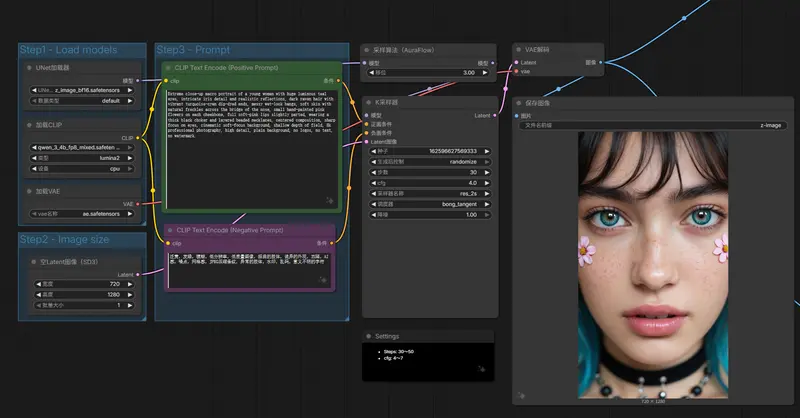
Z-Image 已获ComfyUI 原生支持:非蒸馏基础版,灵活可微调,直出体验一般ComfyUI 官方宣布,Z-Image(阿里通义 MAX 项目组发布的图像生成基础模型)现已获得 原生支持,用户可通过模板库直接调用。 Hugging Face:https://huggingfac...工作流# Z-Image# 文生图2个月前01030
FIBO Edit 上线 ComfyUI:基于授权数据的 JSON 原生图像编辑,商业使用安全ComfyUI 官方宣布,Bria AI 的 FIBO Edit 模型现已通过合作伙伴节点集成至 ComfyUI。这是一款专为生产环境设计的图像编辑模型,其最大亮点在于:完全基于 100% 授权数据训...工作流# BRIA AI# FIBO Edit# 图像编辑2个月前0810
ComfyUI已支持 FLUX.2 [klein]:4B 模型实现 1.2 秒本地图像生成与编辑ComfyUI 已在第一时间支持黑森林实验室(Black Forest Labs)最新发布的 FLUX.2 [klein] 模型系列。该系列将文生图、图生图与多参考图像编辑统一于单一紧凑架构中,在消费...工作流# ComfyUI# FLUX.2 [klein]3个月前06940
可灵2.6 运动控制登陆 ComfyUI:用视频精准驱动角色动作与表情ComfyUI 官方近日正式上线 Kling 2.6 运动控制(Motion Control) 功能。该能力允许用户通过一段参考视频,将其中的人物动作与表情精确迁移到自定义角色图像上,实现高度一致且自...工作流# 可灵2.6# 运动控制3个月前0730
LTX-2 首日集成 ComfyUI,支持同步音视频生成与多模态控制开源音视频生成模型 LTX-2 已于发布当日集成至 ComfyUI 核心,成为首个在 ComfyUI 中获得原生支持的同步音视频基础模型。用户无需安装额外插件,即可直接调用其音画协同生成能力。 LTX...工作流# ComfyUI# LTX-2# 视频生成3个月前0550
Qwen 图像编辑双模型登陆 ComfyUI:支持指令编辑与图层分解ComfyUI 官方现已集成两款来自通义千问(Qwen)系列的图像生成模型:Qwen Image Edit 2511 与 Qwen Image Layered。二者分别面向精准图像编辑与结构化图像合成...工作流# Qwen-Image-Edit-2511# Qwen-Image-Layered3个月前01840



![ComfyUI已支持 FLUX.2 [klein]:4B 模型实现 1.2 秒本地图像生成与编辑](https://pic.sd114.wiki/wp-content/uploads/2026/01/1768500082-1768500082-FLUX.2-klein-4.webp~tplv-o4t1hxlaqv-image.image)