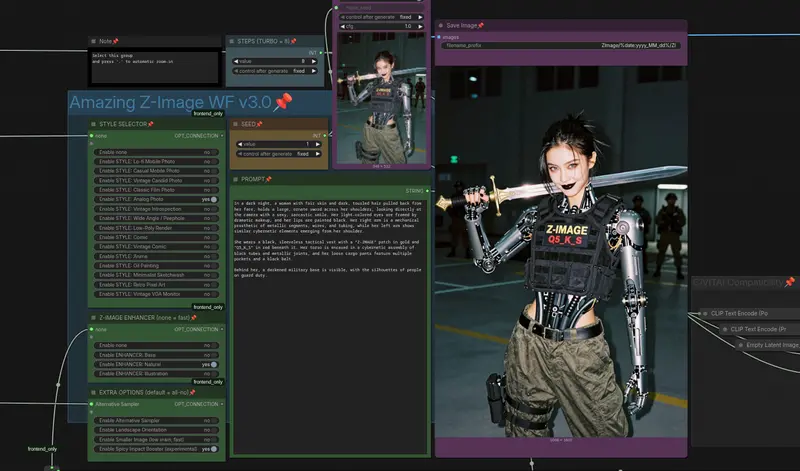
Amazing Z-Image Workflow v3.0:为 Z-Image-Turbo 优化的 ComfyUI 高质量图像生成工作流本项目基于 ComfyUI 原生工作流构建,专为 Z-Image-Turbo 模型设计,提供三种主题化工作流(通用、插画、摄影),并针对 GGUF 与 SafeTensors 两种模型格式提供预配置版...工作流# Amazing Z-Image Workflow# Z-Image-Turbo3个月前02600
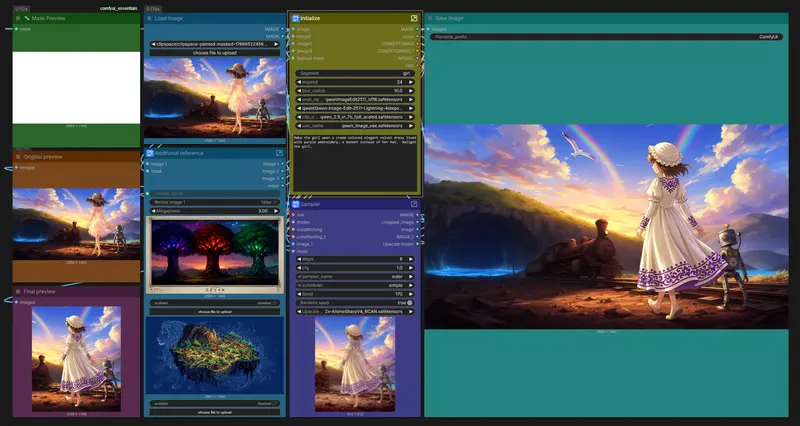
Qwen-Image-Edit-2511局部编辑工作流:20秒精准修改超大图中的单个角色处理 8192×4096 这类超大分辨率图像时,直接使用 AI 全图重绘往往耗时、显存爆炸、画质失控。 但如果你只需要修改画面中的一个角色——比如换装、修复面部、替换背景元素——有没有更高效的方式? ...工作流# Qwen-Image-Edit-25113个月前02540
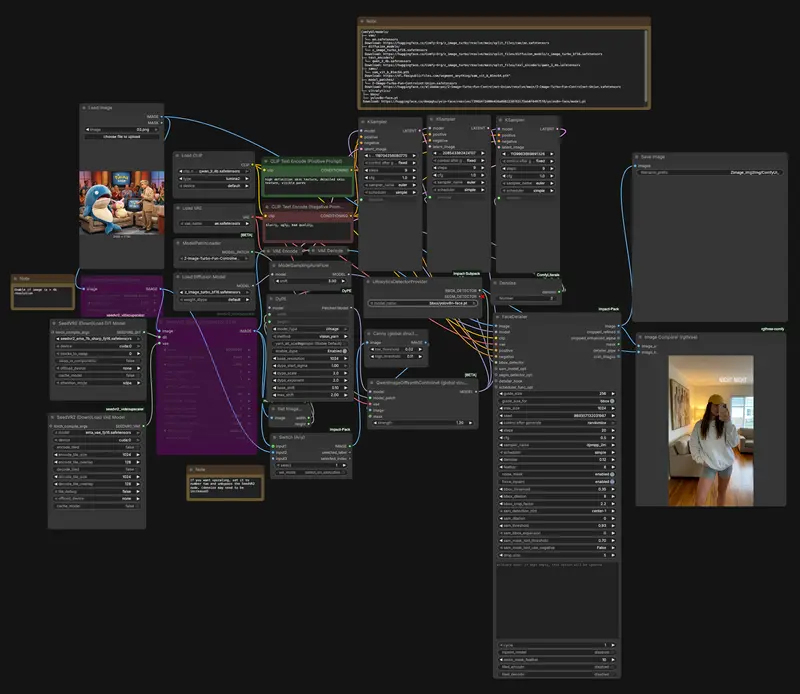
SynthID-Bypass:利用ComfyUI 工作流移除谷歌SynthID水印谷歌在 Nano Banana Pro 等模型中集成了 SynthID ——一种旨在检测 AI 生成图像的不可见数字水印技术。然而,任何安全机制的有效性,都需经受“红队测试”的检验。 由开发者00qu...工作流# ComfyUI 工作流# SynthID-Bypass3个月前01940
ComfyUI 已支持 Z-Image Turbo:轻量、高效、中文友好,本地部署指南来了在开源生图模型纷纷朝着 “大参数、高算力” 方向狂奔的当下,黑森林实验室的 FLUX.2 完整版甚至让顶级显卡 5090 都难以驾驭,这让普通创作者望而却步。而阿里通义团队推出的 Z-Image-Tu...工作流# ComfyUI# Z-Image-Turbo4个月前02,6000
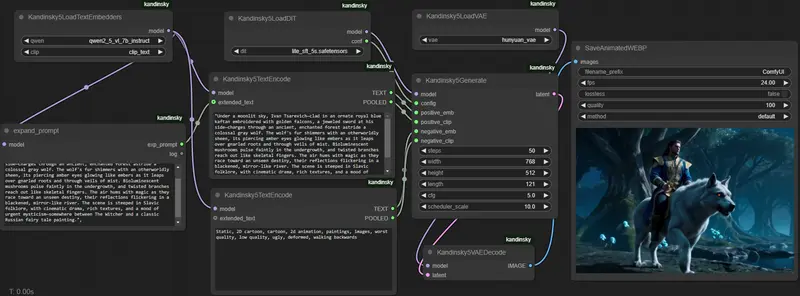
Kandinsky 5 视频生成落地 ComfyUI!T2V/I2V 工作流一键加载,12GB GPU 可运行Kandinsky 5 系列已正式适配 ComfyUI,官方提供完整的视频生成工作流,支持文本生视频(T2V)和图像生视频(I2V)双模式。无论是想快速体验 5-10 秒短视频生成,还是需要精细化调整...工作流# Kandinsky 54个月前02270
ComfyUI 首发支持 FLUX.2:本地/云端/合作节点三重方案,开箱即用黑森林实验室刚刚开源了 FLUX.2。ComfyUI 的首发日支持现已上线!FLUX.2 是下一代图像模型,可生成高达 400 万像素的照片级真实感输出,在光照、皮肤、织物和手部细节方面表现大幅提升...工作流# FLUX.24个月前0900
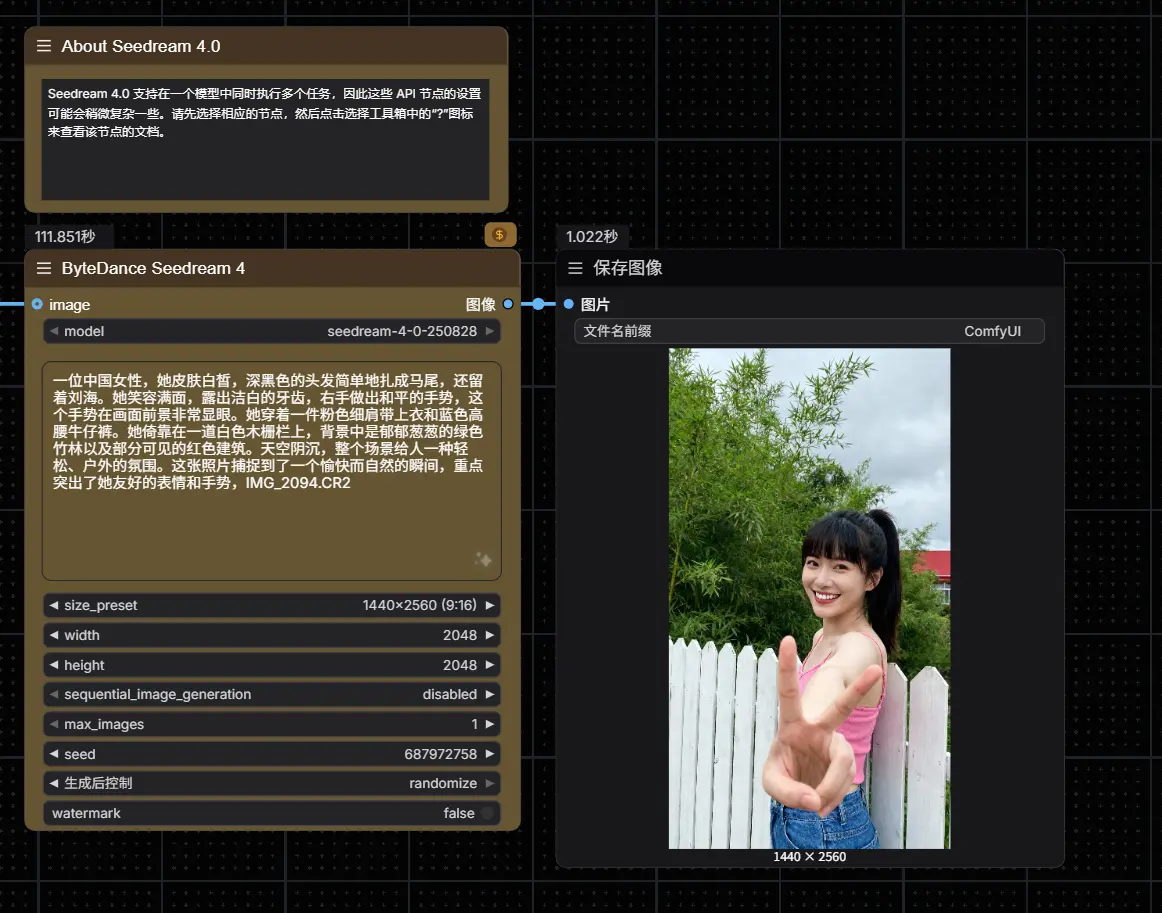
字节跳动Seedream 4.0 正式接入 ComfyUI:一模型打通生成与编辑全流程ComfyUI官方宣布字节跳动的Seedream 4.0 已集成至 ComfyUI,通过官方 API 节点即可直接调用,无需额外部署,开箱即用。 这一次更新不只是“多一个模型选项”,而是带来了一种全新...工作流# ComfyUI# Seedream 4.0# 字节跳动7个月前01,0560
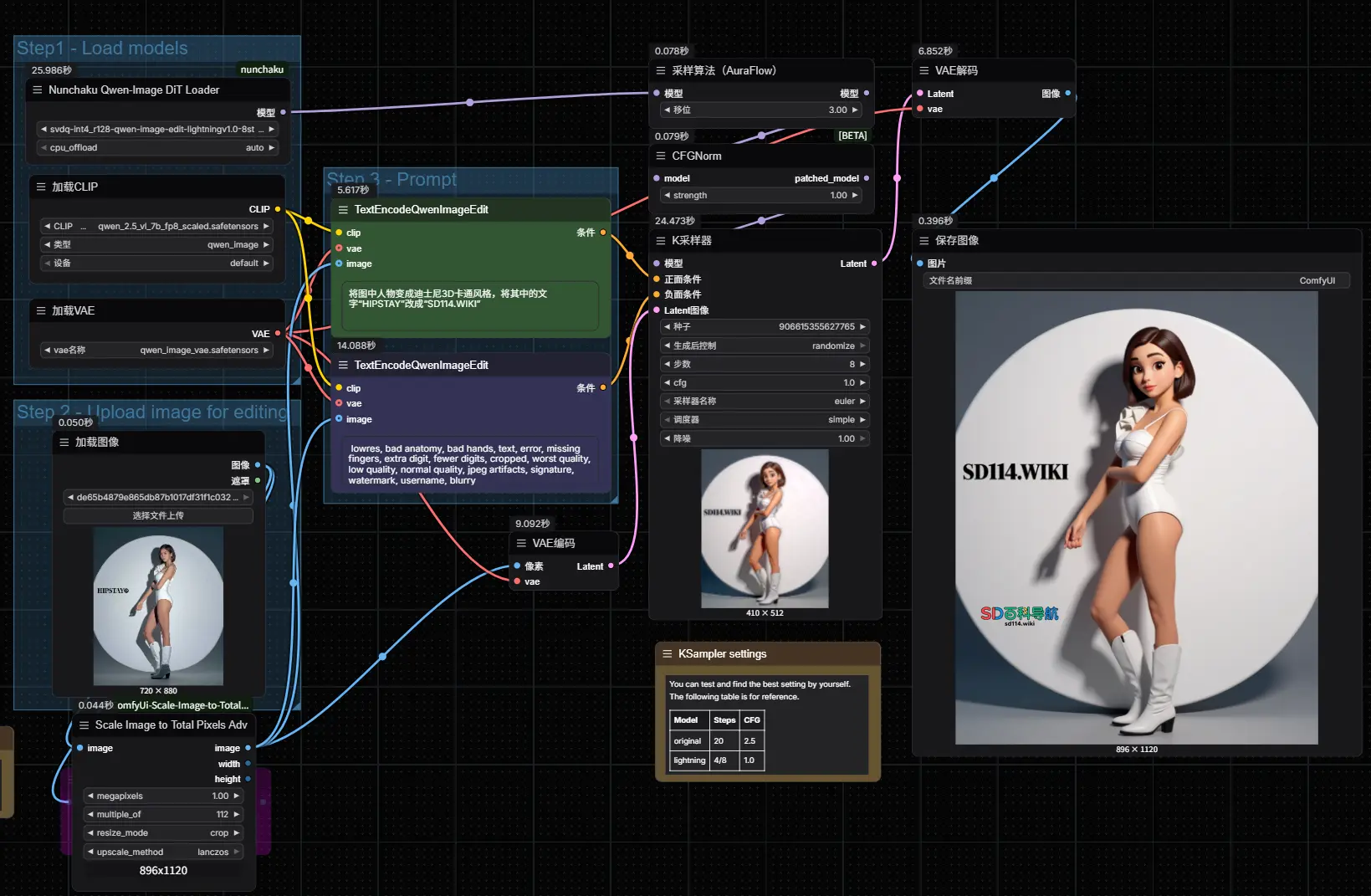
Nunchaku 正式发布 1.0:让 Qwen-Image 与 Qwen-Image-Edit 模型在低显存设备上跑起来9月4日,Nunchaku 团队正式发布 v1.0.0 版本,标志着这一面向 4 位量化神经网络(SVDQuant) 的高性能推理引擎进入稳定可用阶段。 GitHub:https://github.c...工作流# Nunchaku# Nunchaku v1.0.0# Qwen-Image7个月前01,7760
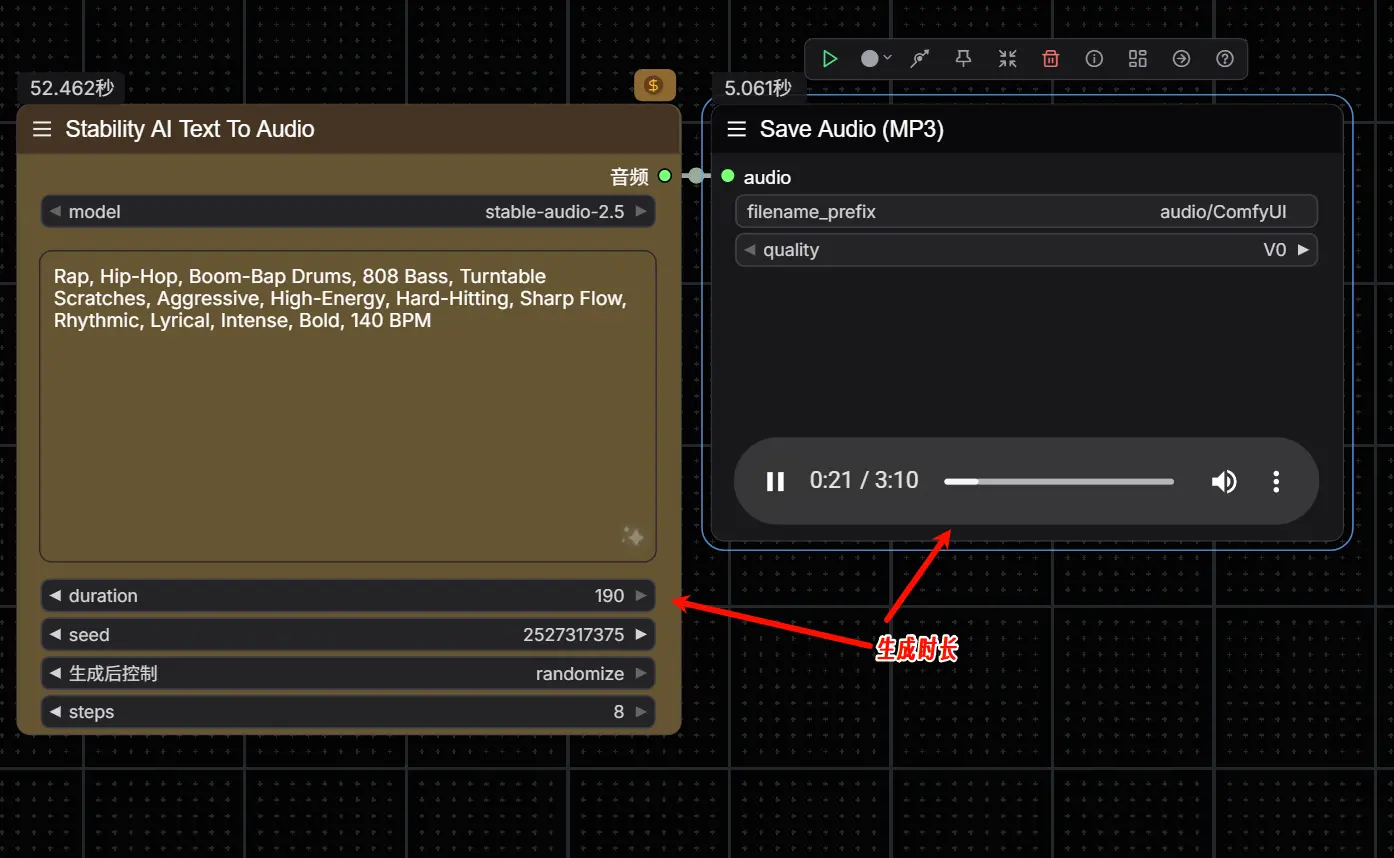
ComfyUI 中使用 Stable Audio 2.5 API:文本转音频、音频转换与修复完整指南随着 Stability AI 发布 Stable Audio 2.5 ——首个专为大规模企业级音效制作设计的 AI 音频模型,其官方 API 已正式集成至 ComfyUI,支持开发者和创意团队通过可...工作流# ComfyUI# Stable Audio 2.57个月前04920
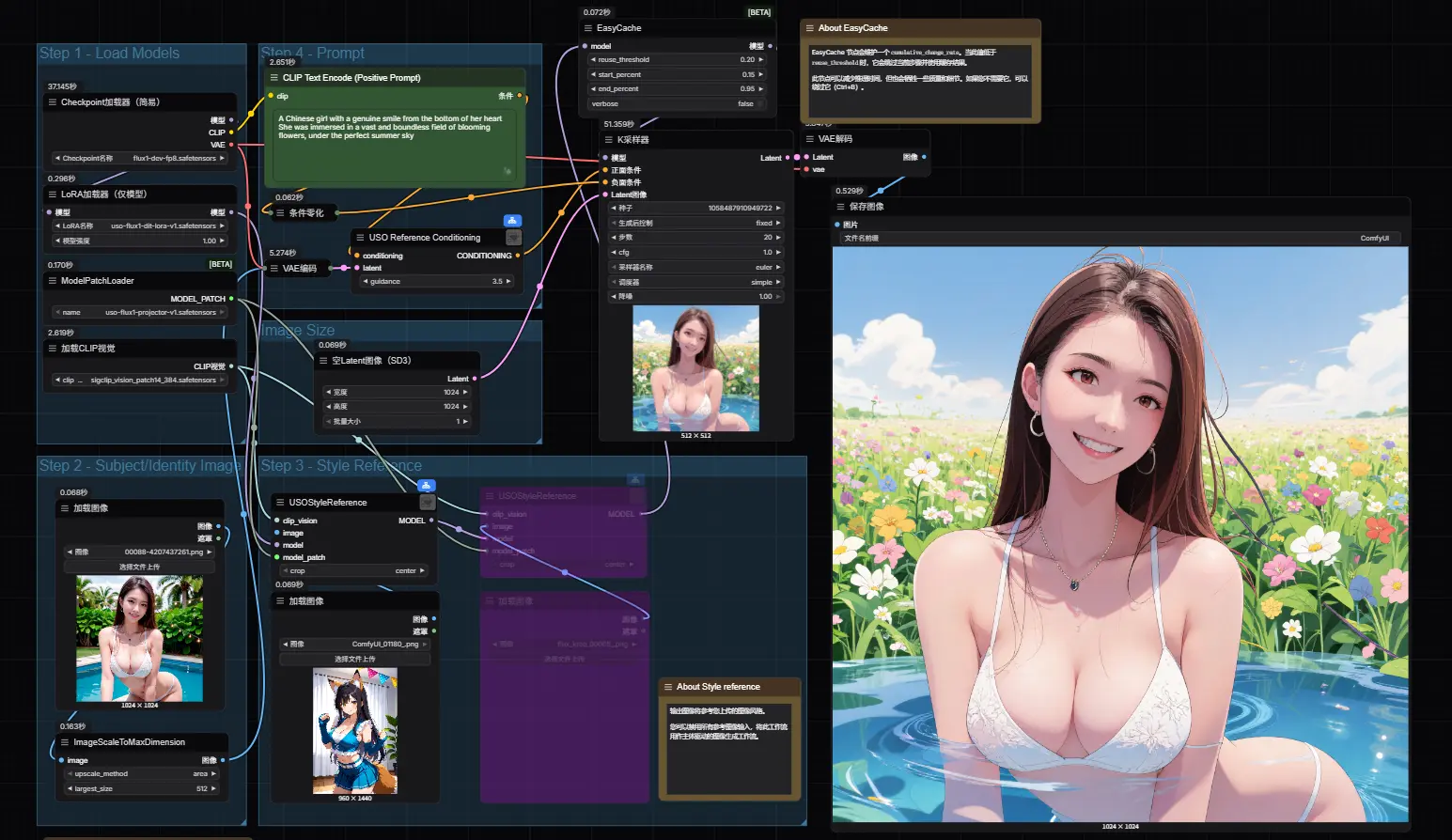
字节跳动 USO 模型 ComfyUI 原生工作流指南:实现风格与主体统一的 AI 生成在 AI 图像生成中,两个核心挑战长期并存: 主体一致性:如何让同一个角色在不同场景中保持身份不变? 风格迁移:如何将参考图的艺术风格准确迁移到新内容上? 传统方案往往需要多个模型、复杂调参,或依赖 ...工作流# USO 模型# 字节跳动7个月前01,0560
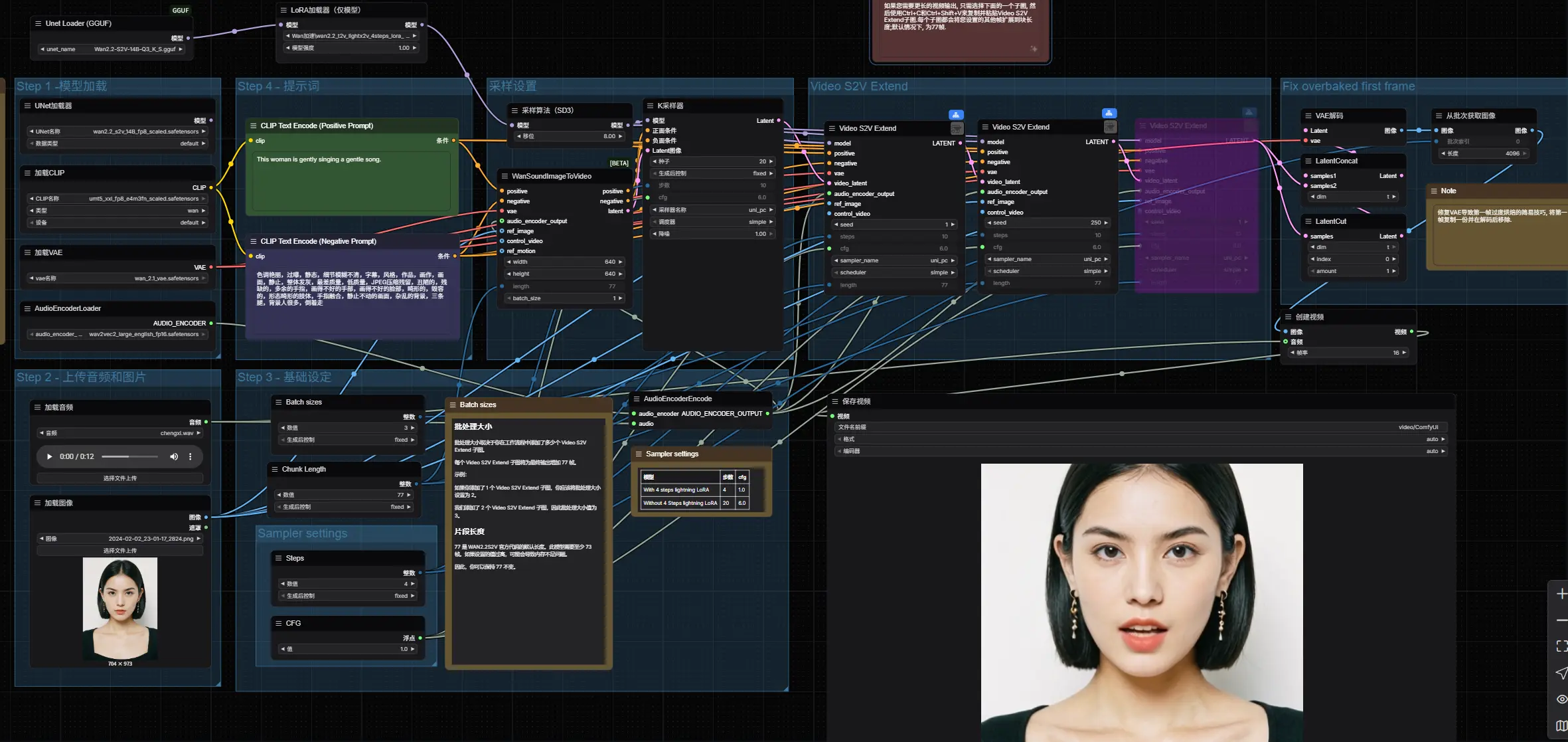
用语音激活静态图像!ComfyUI 原生适配 Wan2.2-S2V,一键生成口型同步视频ComfyUI官方宣布,高性能音频驱动视频生成模型Wan2.2-S2V已实现原生适配——无需额外插件,即可直接在ComfyUI中调用该模型,将静态图片与音频结合,生成对话、唱歌、角色表演等动态视频内容...工作流# ComfyUI# Wan2.2-S2V# 口型同步视频7个月前01,7810
Nano-banana 来了!通过 ComfyUI 原生节点调用 Gemini 2.5 Flash 图像模型一个轻量但高效的图像生成模型——Nano-banana(即 Google 的 Gemini 2.5 Flash 图像模型)现已接入 ComfyUI,通过原生 API 节点实现无缝集成。 你无需离开熟悉...工作流# Gemini 2.5 Flash# nano-banana7个月前03,0450