随着 Stability AI 发布 Stable Audio 2.5 ——首个专为大规模企业级音效制作设计的 AI 音频模型,其官方 API 已正式集成至 ComfyUI,支持开发者和创意团队通过可视化工作流实现高质量音乐与音效生成。
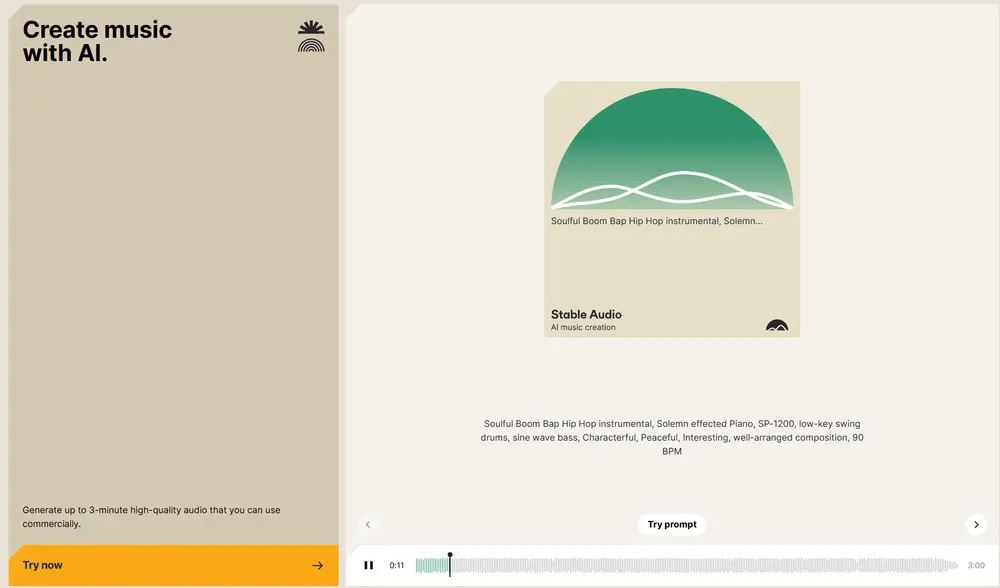
本文将详细介绍如何在 ComfyUI 中使用 Stability AI 的三个核心音频功能:
- ✅ 文本转音频(Text-to-Audio)
- ✅ 音频转音频(Audio-to-Audio)
- ✅ 音频修复(Audio Inpainting)
所有功能均基于完全授权数据训练,输出内容商业安全,适用于广告、游戏、影视、品牌声音设计等专业场景。
为什么选择Stable Audio 2.5 API?企业级能力加持
Stable Audio 2.5专为商业场景设计,接入ComfyUI后可直接赋能创意团队,其核心优势体现在四大维度:
- 极速生成:GPU环境下,生成3分钟完整曲目仅需2秒内,满足批量创作需求;
- 结构化创作:自动生成“引子-发展-结尾”的多段落音频,无需人工拼接;
- 灵活修复:支持基于现有音频片段扩展、续接,提升创作可控性;
- 商业安全:基于100%授权数据集训练,无版权侵权风险,适配广告、游戏、影视等专业场景。
准备工作:确保环境正确
在开始前,请确认以下几点:
- 更新 ComfyUI 到最新版本
- 推荐使用 Nightly 开发版(非稳定版或桌面封装版)
- 稳定版可能未包含最新的 API 节点支持
- 登录并配置网络环境
- 使用 Stability AI API 需正常登录账户
- 确保处于受许可的网络环境下(如中国大陆用户需注意访问限制)
- 查找官方工作流模板
- 在 ComfyUI 的“工作流模板”中搜索
Stability AI audio - 可直接加载预设工作流,避免手动搭建节点
- 在 ComfyUI 的“工作流模板”中搜索
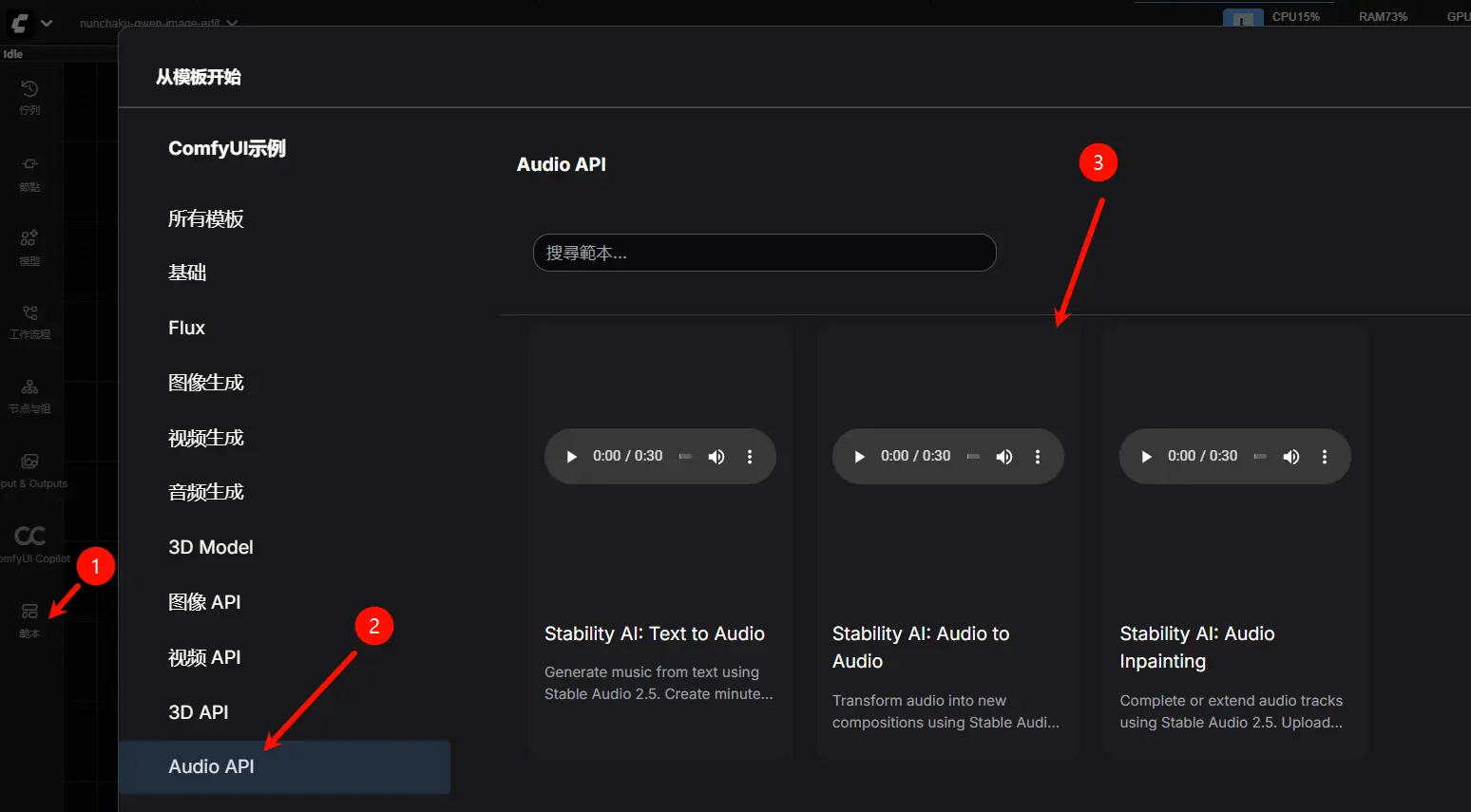
⚠️ 若加载时提示节点缺失,请检查是否为最新开发版,或重启后查看是否有节点导入失败。
功能概览:三大核心工作流
| 功能 | 输入 | 输出 | 典型用途 |
|---|---|---|---|
| 文本转音频 | 文本提示(Prompt) | 完整音频文件 | 从描述生成背景音乐、品牌提示音 |
| 音频转音频 | 原始音频 + 提示词 | 新风格音频 | 改变曲风、旋律重编、哼唱转成品 |
| 音频修复 | 部分音频 + 掩码范围 | 补全/扩展后的完整音频 | 续写未完成曲目、延长片段 |
详细操作指南
1. 文本转音频(Text-to-Audio)
对于文本转音频,你可以通过文本提示生成音频。你需要描述想要生成的音乐。从纯文本生成高质量、结构完整的音乐作品。

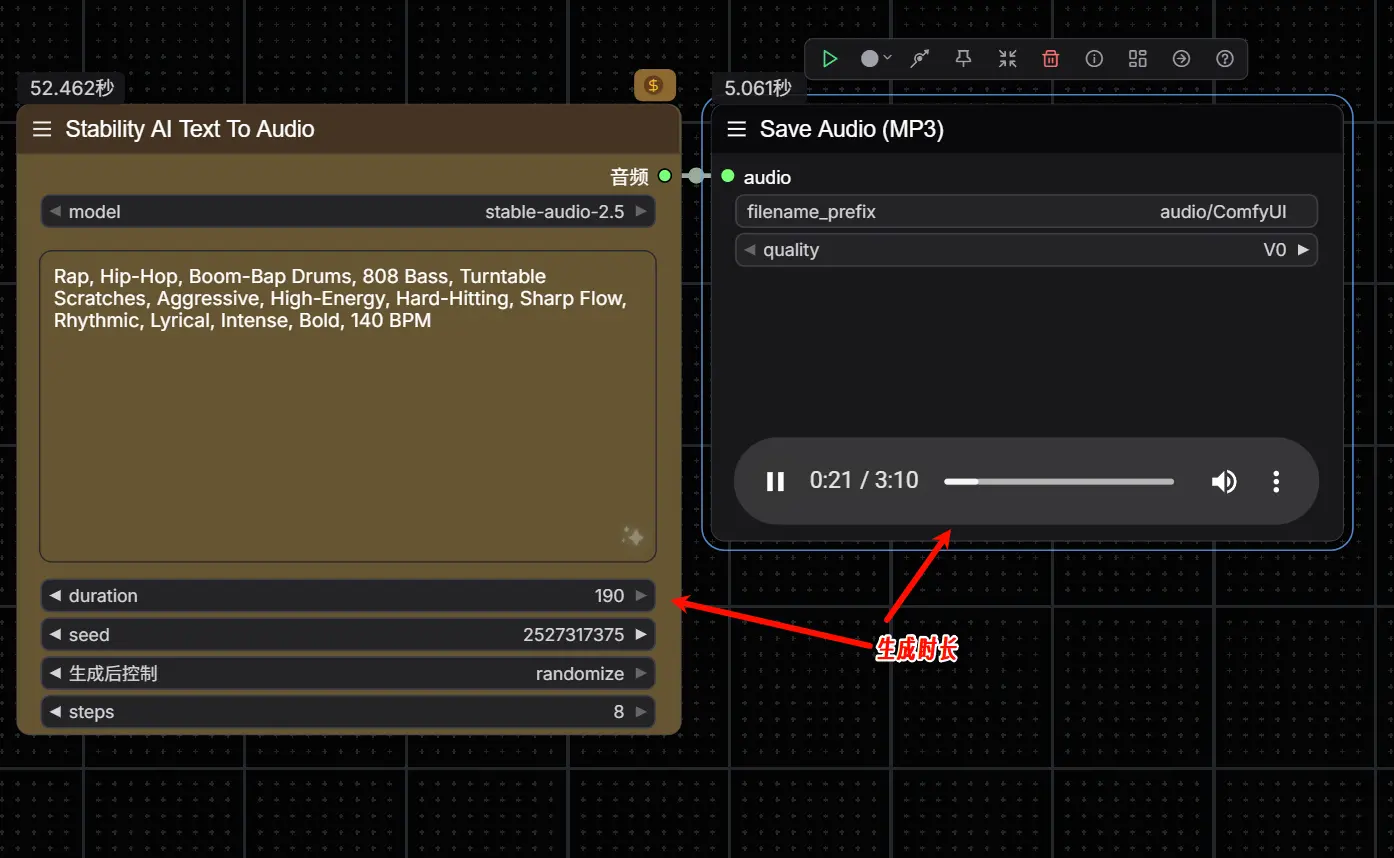
操作步骤:
- 在工作流中找到 “Stability AI Text to Audio” 节点
- 编辑 文本提示(Prompt)
示例:振奋人心的管弦乐配乐,带有丰满的合成器,渐进式节奏 - (可选)调整
duration参数- 默认为 190 秒(约 3 分钟),最大支持 300 秒
- 点击 Run 或按下
Ctrl/Cmd + Enter执行生成 - 生成的音频将自动保存至:
ComfyUI/output/audio/
技术亮点:
- 支持生成包含引子、发展、高潮和结尾的多段落结构
- 更好地响应情绪关键词与音乐术语
2. 音频转音频(Audio-to-Audio)
音频转音频基本上是音乐重采样。你可以使用它从给定的音乐片段生成新音乐,或者你可以哼唱一段旋律,然后模型将基于输入音频生成新音乐。比如,将一段现有音频(如哼唱、Demo 或采样)转换为全新风格的专业级作品。

操作步骤:
- 添加以下任一输入节点:
- Record Audio:实时录制你的旋律构思(如哼唱)
- LoadAudio:上传本地音频文件(至少 6 秒)
- 连接到 “Stability AI Audio to Audio” 节点
- 设置文本提示,描述目标风格
示例:电子舞曲风格,强劲节拍,适合夜店氛围 - 调整
strength参数控制变化程度:0.1–0.3:轻微调整,保留原旋律0.7–1.0:彻底重塑,仅保留节奏或情绪
- 点击运行,结果保存至输出目录
应用场景:
- 将草稿 Demo 快速升级为发布级配乐
- 实现跨流派改编(古典 → 合成器流行)
- 游戏音效批量变体生成
3. 音频修复(Audio Inpainting)
对已有音频进行局部补全或扩展,实现无缝续写。音频修复用于完成或扩展现有音轨。你可以使用它来完成音乐的缺失部分,或将音乐扩展到更长的时长。你需要设置想要开始和结束修复的位置。
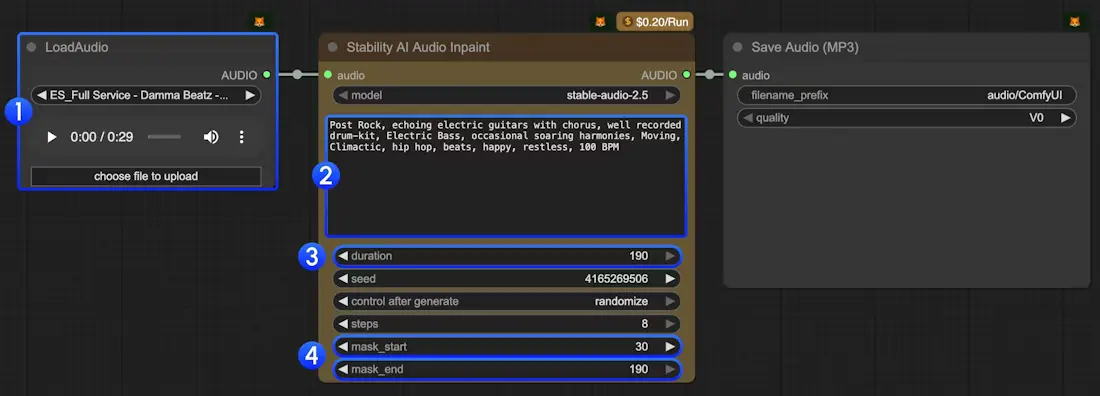
操作步骤:
- 使用 LoadAudio 节点上传原始音频
- 在 “Stability AI Audio Inpainting” 节点中设置关键参数:
mask_start:修复起始时间(单位:秒)mask_end:修复结束时间(单位:秒)例如:
mask_start=30,mask_end=60表示替换第 30–60 秒的内容
- 输入文本提示,指导模型生成风格
- (可选)修改
duration以延长总时长 - 点击运行,模型将根据上下文智能补全指定区域
实际应用:
- 补全未完成的作曲片段
- 替换某段不满意的编曲
- 将 30 秒广告音乐扩展为 90 秒版本
⚠️ 注意:请勿上传受版权保护的内容。系统会通过内容识别技术防止侵权。
创作建议:提升生成质量
- 生成符合品牌调性的APP提示音、设备反馈音,强化品牌识别;
- 为游戏场景定制环境音轨(如“恐怖 dungeon 氛围音+稀疏水滴声”);
- 上传短视频背景音乐片段,扩展为完整的长时长版本;
- 用情绪关键词(“紧张”“治愈”“欢快”)快速生成适配不同内容的音频。
为了获得更符合预期的结果,建议遵循以下提示工程原则:
| 类型 | 推荐关键词组合 |
|---|---|
| 情绪 | 振奋、紧张、宁静、神秘、欢快 |
| 结构 | 包含引子、渐强、高潮、尾声 |
| 乐器 | 交响乐团、合成器、钢琴主导、稀疏打击乐 |
| 场景 | 广告背景、游戏战斗、纪录片开场、零售空间 |
| 流派 | 电子、环境音乐、电影原声、工业风 |
✅ 示例提示:
“黑暗的电影紧张感,搭配稀疏的打击乐和低频嗡鸣,缓慢推进,适合作品开场”
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











