Qwen-Image-Edit 是基于 Qwen-Image 20B 模型进一步训练的图像编辑专用版本,由通义实验室推出。它不仅继承了 Qwen-Image 在文本渲染方面的强大能力,更实现了对图像内容的精准文字编辑与语义-外观双重控制编辑,是目前少有的支持中英文混合文本编辑的开源多模态模型之一。
- Hugging Face:https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI
- 魔塔:https://www.modelscope.cn/models/Comfy-Org/Qwen-Image-Edit_ComfyUI
- GGUF版:https://modelscope.cn/models/QuantStack/Qwen-Image-Edit-GGUF
该模型已深度集成至 ComfyUI,并提供官方原生工作流模板,支持模块化、可视化操作,适用于创意设计、广告制作、IP形象修改等多种场景。
核心能力
| 能力 | 说明 |
|---|---|
| ✅ 精准文字编辑 | 可在保留字体、大小、颜色和排版的前提下,对图像中的文字进行增、删、改操作,支持中文与英文混合场景。 |
| ✅ 语义+外观双重编辑 | - 语义编辑:修改物体类别、姿态、结构(如“把狗变成猫”、“旋转杯子”) - 外观编辑:调整风格、光照、材质、色彩分布等低级视觉特征 |
| ✅ 高性能推理支持 | 支持 FP8 量化模型与 4 步轻量 LoRA(Lightning),可在保证质量的同时显著提升生成速度。 |
| ✅ 跨基准 SOTA 表现 | 在多个公开图像编辑基准测试中达到或超越现有方法,具备强大的泛化能力。 |
使用前提:环境准备
为确保工作流正常运行,请确认以下条件已满足:
- ComfyUI 为最新开发版(nightly)
- 推荐使用
comfyui主仓库的dev分支; - 稳定版或桌面版可能未包含最新节点支持。
- 推荐使用
- 节点加载无报错
- 启动时检查控制台是否有红色报错信息;
- 若提示节点缺失,请更新 ComfyUI 及相关插件。
- 推荐硬件配置
- 显存 ≥ 12GB(用于 1024x1024 输出)
- 若使用 FP8 模型,可降低显存占用,适配 8–10GB 显存设备
一、工作流获取方式
你有两种方式加载 Qwen-Image-Edit 的标准工作流:
- 方式一:从模板加载(推荐)
更新 ComfyUI 后,在界面左上角点击 “Workflow” → “Templates”,搜索Qwen-Image-Edit即可找到预设工作流。 - 方式二:手动导入 JSON
将官方提供的工作流 JSON 内容拖入 ComfyUI 画布,自动加载节点结构。 - 方式三:云平台
如果你的显存不足以在本地运行,可在云平台上运行(点击查看)
二、模型下载与存放路径
所有模型文件均可在 Hugging Face或魔塔获取:
- Diffusion Model:
qwen_image_edit_fp8_e4m3fn.safetensors - LoRA:
Qwen-Image-Lightning-4steps-V1.0.safetensors - Text Encoder:
qwen_2.5_vl_7b_fp8_scaled.safetensors - VAE:
qwen_image_vae.safetensors
请将模型按以下目录结构存放:
ComfyUI/
├── models/
│ ├── diffusion_models/
│ │ └── qwen_image_edit_fp8_e4m3fn.safetensors
│ ├── loras/
│ │ └── Qwen-Image-Lightning-4steps-V1.0.safetensors
│ ├── vae/
│ │ └── qwen_image_vae.safetensors
│ └── text_encoders/
│ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
⚠️ 注意:节点会自动识别
text_encoders和diffusion_models目录,路径错误将导致加载失败。
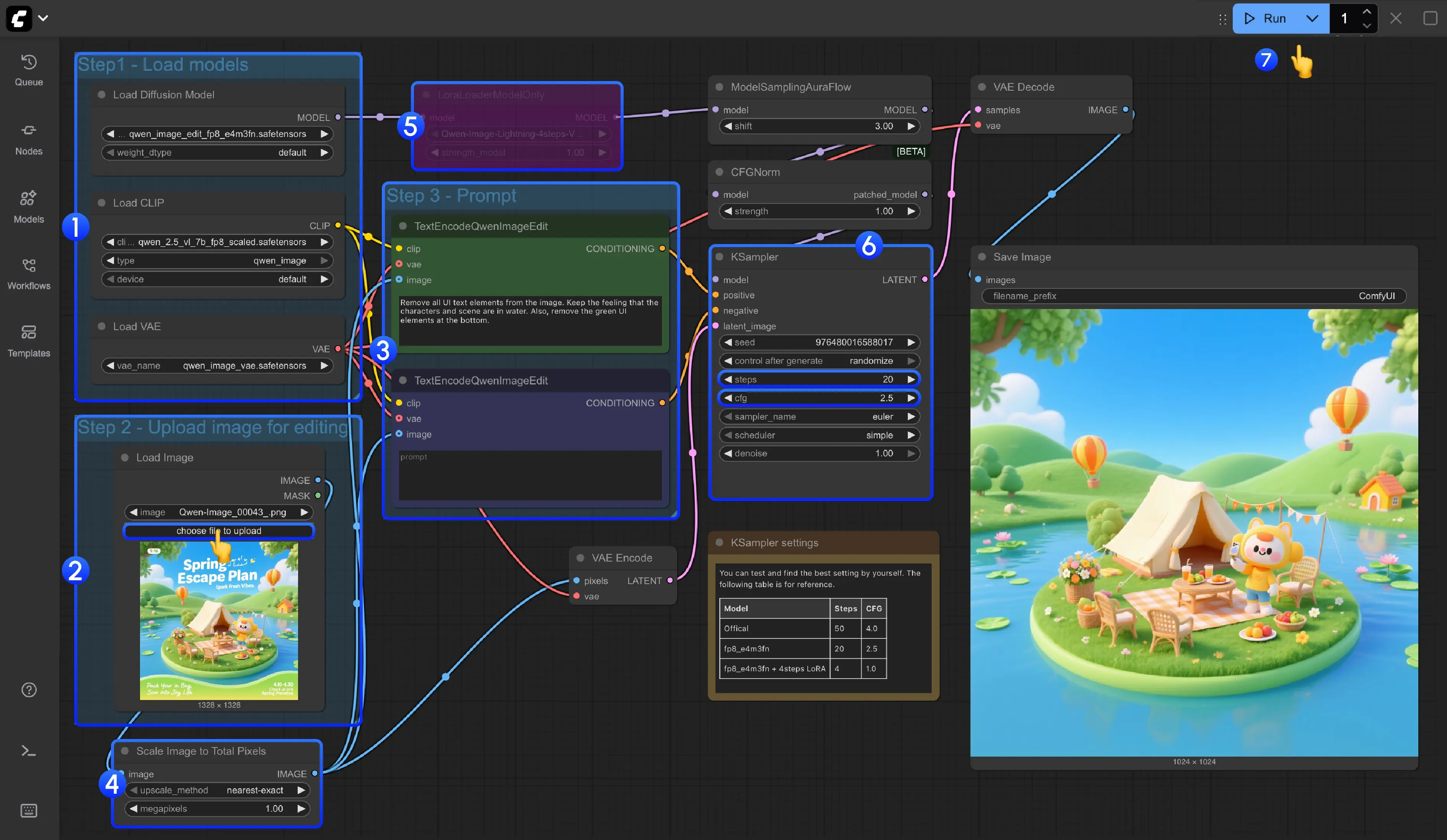
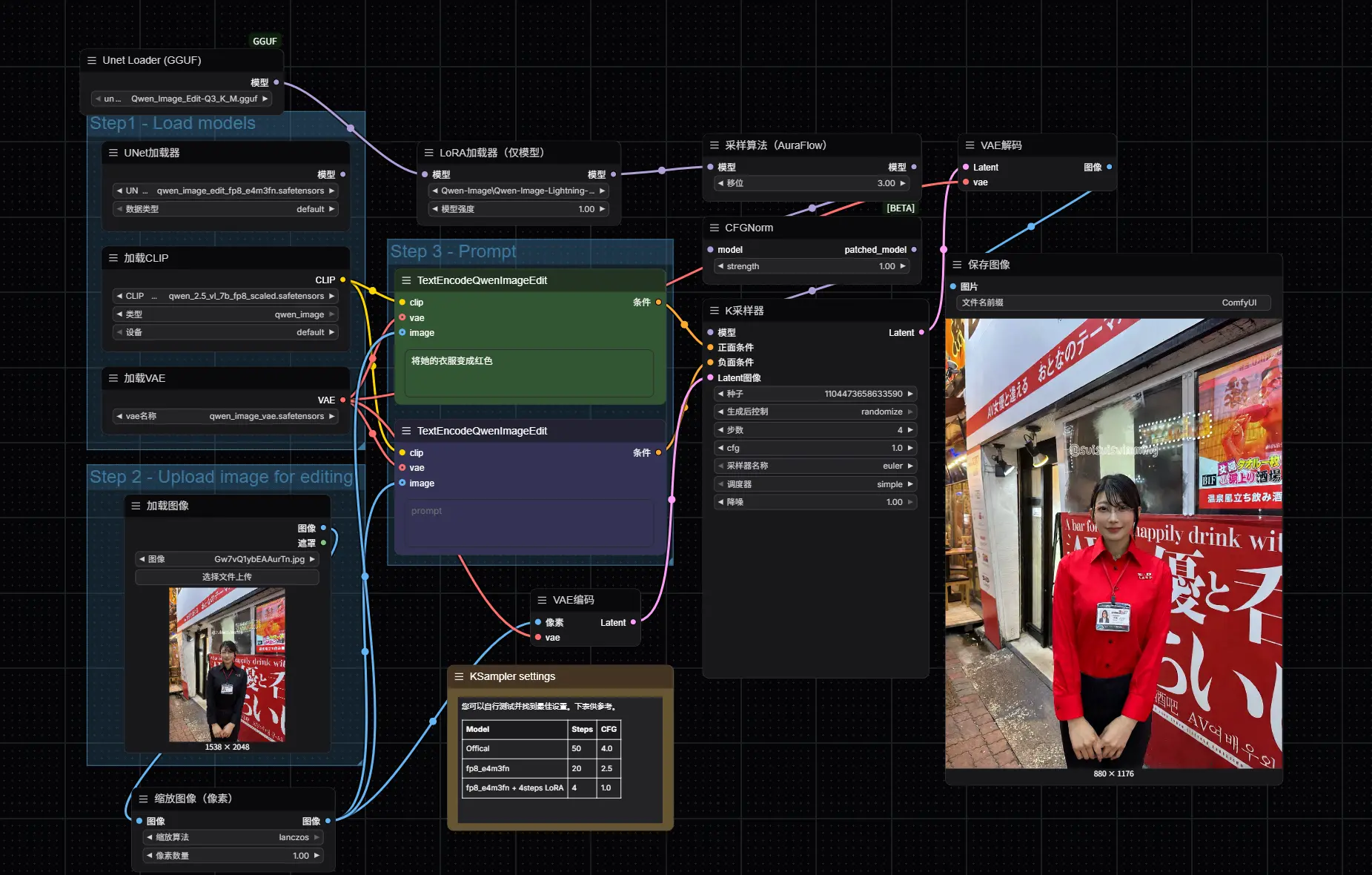
三、工作流执行步骤详解
1. 模型加载
确保以下三个关键节点正确加载对应模型:
| 节点 | 应加载模型 |
|---|---|
Load Diffusion Model | qwen_image_edit_fp8_e4m3fn.safetensors |
Load CLIP | qwen_2.5_vl_7b_fp8_scaled.safetensors |
Load VAE | qwen_image_vae.safetensors |
提示:首次使用时,下拉菜单中可能未显示模型,重启 ComfyUI 即可刷新列表。
2. 图像输入
使用 Load Image 节点上传待编辑图像。
- 支持格式:PNG、JPG、WEBP 等常见图像格式;
- 建议分辨率:512x512 至 1024x1024;
- 高分辨率图像(如 2048x2048)将通过
Scale Image to Total Pixels节点自动缩放至约 100万像素(如 1024x1024),以避免显存溢出和质量下降。
🛠️ 高级用法:若你明确了解输入尺寸且希望跳过缩放,可选中
Scale Image to Total Pixels节点后按Ctrl+B临时禁用。
3. 提示词设置
在 CLIP Text Encoder 节点中输入编辑指令(prompt),支持自然语言描述。
示例提示词:
把广告牌上的“欢迎光临”改成“今日特惠”,保持字体和颜色不变
将图中的汽车换成一只大熊猫,背景风格改为水墨画
让这个人面向镜头微笑,并把T恤颜色从蓝色改为红色
模型能理解复杂语义指令,建议尽量具体描述编辑目标。
4. 可选加速:启用 Lightning LoRA
若需提升生成速度,可启用 4-step 快速生成 LoRA:
- 找到
LoraLoaderModelOnly节点; - 取消选中该节点上的
bypass选项(或按Ctrl+B移除绕过状态); - 确保其加载了
Qwen-Image-Lightning-4steps-V1.0.safetensors。
启用后,CFG设置为1,KSampler 设置 steps=4 即可获得高质量输出,速度提升显著。
5. KSampler 参数建议
您可以自行测试并找到最佳设置。下表供参考。
| Model | Steps | CFG |
|---|---|---|
| Offical | 50 | 4.0 |
| fp8_e4m3fn | 20 | 2.5 |
| fp8_e4m3fn + 4steps LoRA | 4 | 1.0 |
💡 小贴士:节点下方通常附有注释(Notes),提供参数调优建议,可参考测试。
四、运行与输出
完成上述配置后:
- 点击右上角 Queue 按钮;
- 或使用快捷键
Ctrl+Enter(Mac 为Cmd+Enter)提交任务; - 生成结果将通过
Preview Image或Save Image节点输出。
五、常见问题与解决方案
| 问题 | 原因 | 解决方法 |
|---|---|---|
| 模型未出现在下拉菜单 | 路径错误或未重启 | 检查模型路径,重启 ComfyUI |
| 显存不足报错 | 输入图像过大或 batch 过高 | 启用缩放节点,降低分辨率 |
| 文字编辑失败 | 提示词不明确或字体复杂 | 明确描述“文字内容+保持样式”,避免艺术字 |
| 输出模糊或失真 | steps 过低或 VAE 未加载 | 提高步数,确认 VAE 已正确加载 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...










