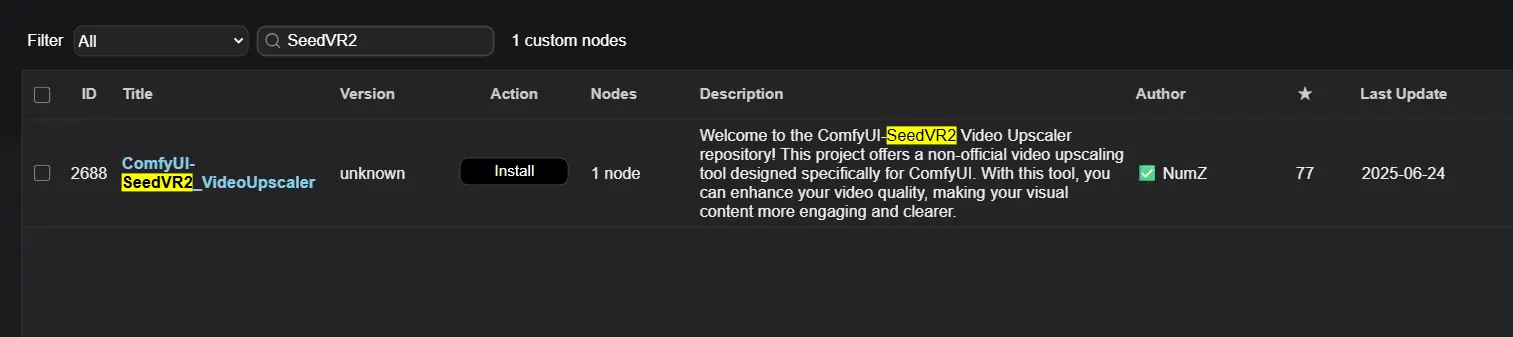
字节跳动推出的视频修复模型 SeedVR2 在图像增强和视频超分领域表现出色。开发者 numz 基于该模型开发了 ComfyUI 插件 ComfyUI-SeedVR2_VideoUpscaler,已可在 ComfyUI 中直接使用,支持视频与图像的高质量放大生成。
- GitHub:https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler
- 模型:https://huggingface.co/numz/SeedVR2_comfyUI/tree/main
本文将详细介绍该插件的功能、安装方式、配置参数及性能表现,帮助你快速上手使用。

🚀 功能亮点
- 高质量放大:支持任意长度视频放大,效果清晰自然
- 自动下载模型:无需手动下载,插件会自动从服务器获取所需模型文件
- FP8 支持:提升处理速度,降低显存占用(需硬件支持)
- 时间一致性控制:通过调整
batch_size可激活时间一致性机制,避免帧间抖动
📦 安装指南
1. 克隆插件仓库到 ComfyUI 的 custom_nodes 目录:
cd ComfyUI/custom_nodes
git clone https://github.com/numz/ComfyUI-SeedVR2_VideoUpscaler.git2. 安装依赖项
若使用虚拟环境(venv):
pip install -r ComfyUI-SeedVR2_VideoUpscaler/requirements.txt
pip install flash_attn tritonFlash Attention 和 Triton 是关键依赖,安装时可能会因 Python 或 CUDA 版本不匹配而失败,建议参考以下资源:
若使用 ComfyUI 内嵌 Python(python_embeded):
python_embeded\python.exe -m pip install -r ComfyUI-SeedVR2_VideoUpscaler/requirements.txt
python_embeded\python.exe -m pip install flash_attn triton3. 模型存放路径
模型将自动下载至:
models/SEEDVR2/也可手动下载并放置于此目录。
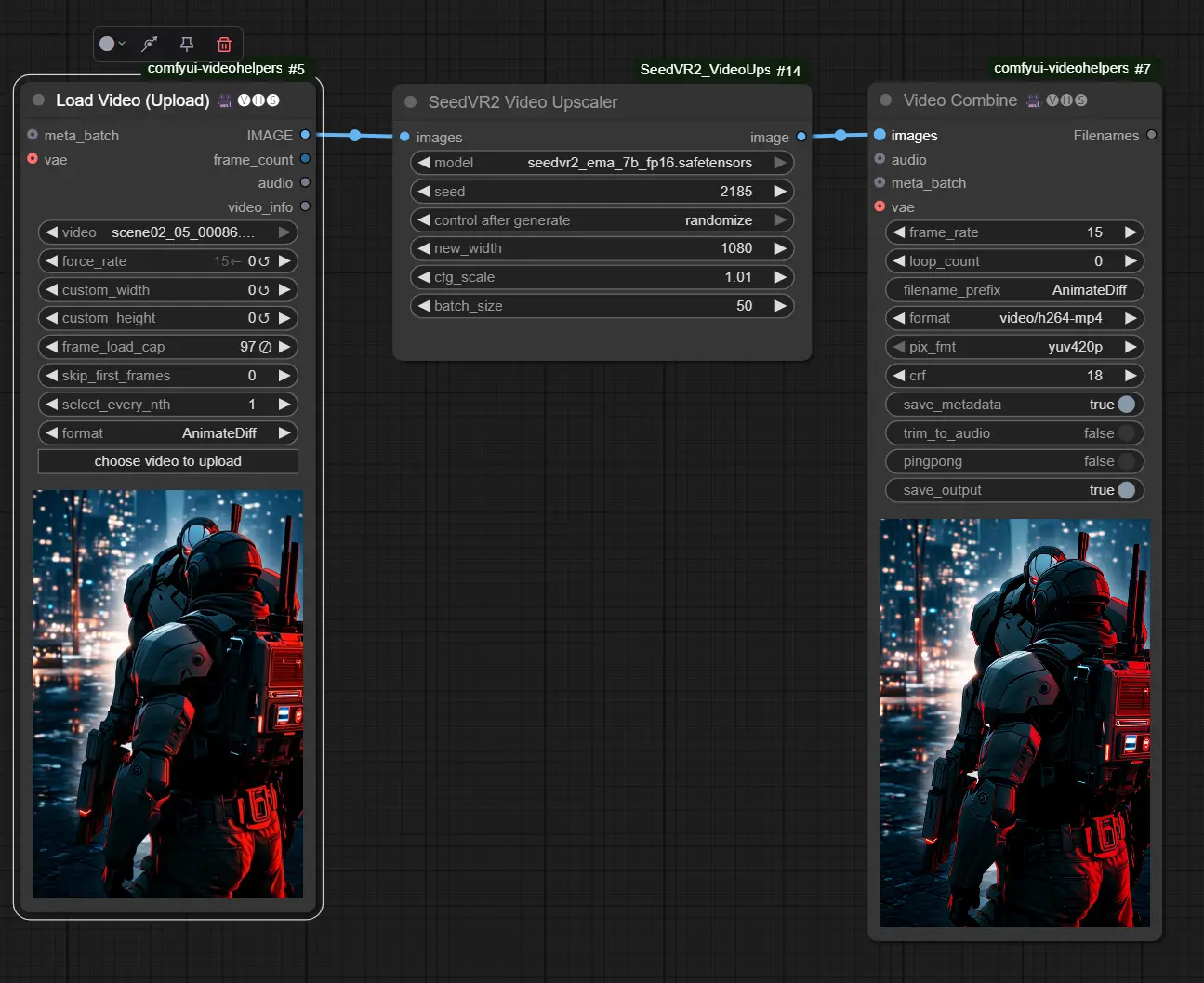
⚙️ 使用方法
- 启动 ComfyUI,在节点菜单中找到 SeedVR2 Video Upscaler
- 配置节点参数:
| 参数名 | 说明 |
|---|---|
| model | 选择 3B 或 7B 模型 |
| seed | 设置种子值,系统会基于此生成新种子 |
| new_width | 设定目标宽度,高度将按比例调整 |
| cfg_scale | 控制生成质量与细节强度 |
| batch_size | 非常重要! 显存消耗大,推荐设置为 1(无时间一致性)或 5~20(开启时间一致性) |
| preserve_vram | 是否启用低显存模式(适用于 <24GB 显存的 GPU) |
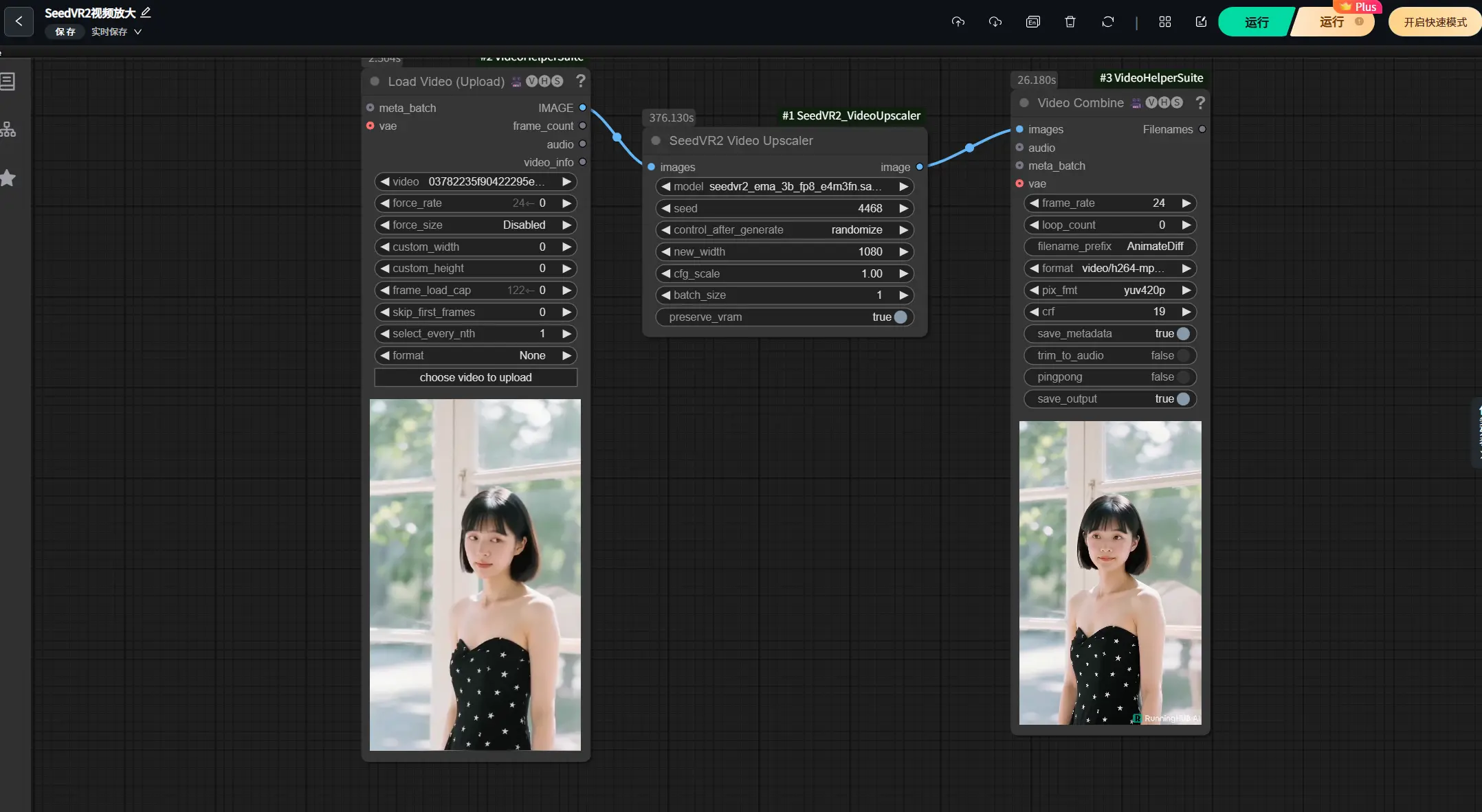
如果你的显卡性能不足,可以使用之前介绍过的云平台RunningHub来运行此插件。
🧪 性能表现
英伟达H100(93GB 显存)
| 帧数 | 分辨率 | 批次大小 | FP8 耗时 (s) | FP8 帧率 | FP16 耗时 (s) | FP16 帧率 |
|---|---|---|---|---|---|---|
| 5 | 512×768 → 1080×1620 | 1 | 22.52 | 0.22 | 27.84 | 0.18 |
| 20 | 512×768 → 1080×1620 | 5 | 39.75 | 0.15 | — | — |
| 20 | 512×768 → 1620×2430 | 1 | 191.28 | 0.10 | — | — |
更新亮点:相比旧版,FP8 模式下处理速度最高可提升 4 倍!
英伟达RTX4090(24GB 显存)
| 模型类型 | 帧数 | 分辨率 | 批次大小 | 耗时 (s) | 帧率 |
|---|---|---|---|---|---|
| 3B FP8 | 5 | 512×768 → 1080×1620 | 1 | 22.52 | 0.22 |
| 3B FP16 | 5 | 512×768 → 1080×1620 | 1 | 27.84 | 0.18 |
| 7B FP8 | 5 | 512×768 → 1080×1620 | 1 | 75.51 | 0.07 |
即使是 RTX4090 这样的消费级显卡,在启用
preserve_vram=True后也能运行 3B 模型,但耗时略有增加。
⚠️ 注意事项与限制
- 显存需求高:即使是 3B 模型也建议至少 18GB 显存,推荐使用 RTX4090 及以上显卡
- 依赖项易出错:
flash_attn和triton对 Python 和 CUDA 版本有严格要求,安装前请确认兼容性 - 依赖版本冲突风险:
omegaconf等库可能与其他插件冲突 - 时间一致性需合理设置 batch_size:推荐设为 5~20,否则可能丢失帧间一致性
- 模型加载慢:首次运行会自动下载模型,可能影响启动速度
🔧 已知待解决问题
- 3B 模型在进程结束时未正常卸载(开发者正在排查)
- 未来计划推出更优基准测试与性能优化方案
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











