
OmniGen2 是由北京人工智能研究院推出的统一多模态生成模型,目前已正式适配 ComfyUI 原生环境,支持从文本生成图像、指令级图像编辑到多图融合的一站式创作流程。

作为新一代多功能视觉生成系统,OmniGen2 凭借其创新架构与强大泛化能力,在开源社区中展现出领先的综合表现。本文将带你完整掌握如何在 ComfyUI 中部署并运行 OmniGen2 的三大核心任务工作流:文生图、图像编辑、多图合成。
北京人工智能研究院推出新一代统一多模态图像生成模型OmniGen2:视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力
OmniGen2 是什么?
OmniGen2 是一个参数总量约 70亿(7B) 的统一多模态生成模型,由两部分构成:
- 3B 文本模型:基于 Qwen-VL-2.5 构建,具备强大的图文理解与指令解析能力;
- 4B 图像扩散模型:独立训练的图像生成路径,专注高保真视觉输出。
与前代不同,OmniGen2 采用 双路径 Transformer 架构,实现文本与图像模块的参数解耦,既提升了生成质量,也避免了传统联合训练中“文本干扰图像”的问题。
核心能力一览
| 功能 | 说明 |
|---|---|
| ✅ 文生图(Text-to-Image) | 支持复杂语义描述,生成细节丰富、构图合理的图像 |
| ✅ 指令式图像编辑 | 可通过自然语言完成对象替换、风格迁移、局部修改等操作 |
| ✅ 多图像合成 | 支持输入多张参考图,结合语义提示生成新场景 |
| ✅ 上下文感知生成 | 能识别并保留人物身份、物体关系与空间布局 |
| ✅ 图像内文字生成 | 可在生成画面中准确渲染可读文本(如广告牌、标语) |
🔍 技术亮点:
- 使用 Omni-RoPE 位置编码,支持多图空间定位与身份区分
- 兼具强视觉理解与可控生成能力
- 统一架构覆盖多种任务,无需切换模型
环境准备:确保兼容最新功能
由于 OmniGen2 使用了较新的节点逻辑(如多图输入控制、动态尺寸处理),请务必确认你的 ComfyUI 环境满足以下条件:
- 使用的是 最新 nightly 开发版(非 release 或桌面稳定版)
- 启动日志无节点导入失败报错
- 自定义节点插件已更新至最新版本
📌 若加载工作流时提示节点缺失,请先升级 ComfyUI 至最新 commit 版本。
所需模型文件清单
所有模型均可通过 HuggingFace或魔塔下载,工作流中已包含自动提示信息,推荐加载后按提示下载。
- HuggingFace:https://huggingface.co/Comfy-Org/Omnigen2_ComfyUI_repackaged
- 魔塔:https://www.modelscope.cn/models/Comfy-Org/Omnigen2_ComfyUI_repackaged
| 模型类型 | 文件名 | 大小 | 说明 |
|---|---|---|---|
| Diffusion Model | omnigen2_fp16.safetensors | ~8.1GB | 主生成模型,必须加载 |
| VAE | ae.safetensors | 319.77MB | Flux 系列通用 VAE,若已有可复用 |
| Text Encoder | qwen_2.5_vl_fp16.safetensors | ~2.1GB | 基于 Qwen-VL-2.5 的文本编码器 |
📁 保存路径建议:
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 diffusion_models/
│ │ └── omnigen2_fp16.safetensors
│ ├── 📂 vae/
│ │ └── ae.safetensors
│ └── 📂 text_encoders/
│ └── qwen_2.5_vl_fp16.safetensors文生图工作流操作指南
1. 获取工作流文件
从工作流模板中点击加载工作流,即可自动加载完整流程,工作流文件中已包含模型下载信息,加载后会提示下载对应模型。
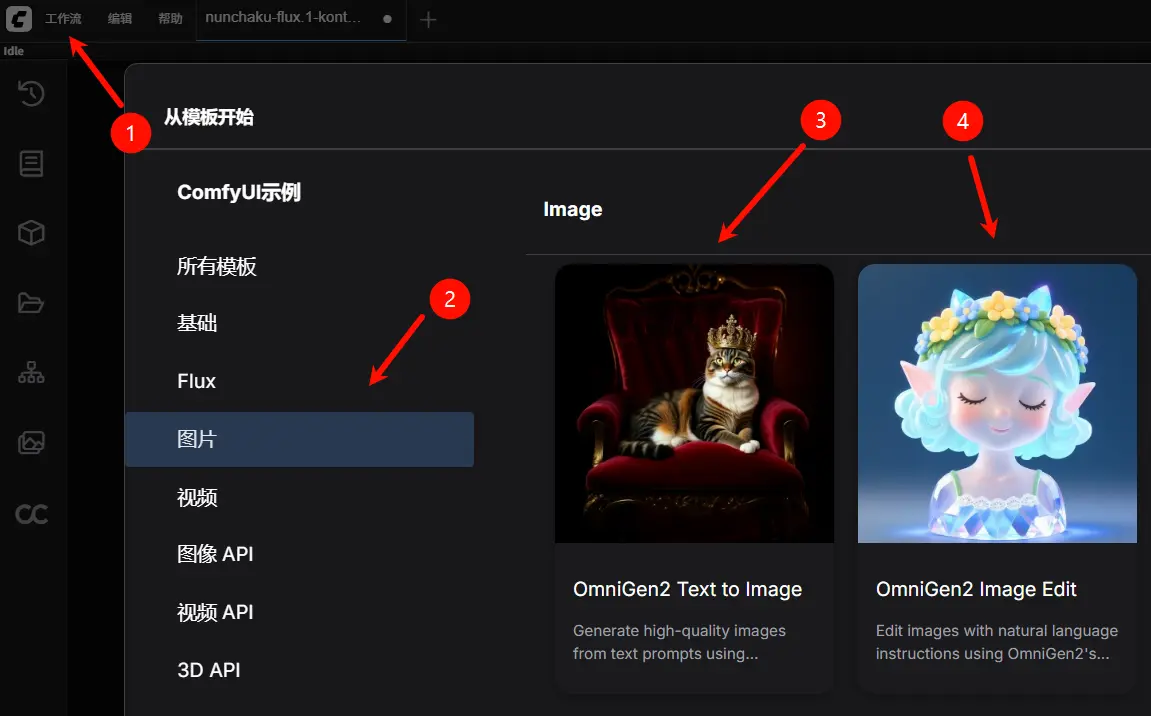
2. 按步骤完成工作流运行
- 加载主模型:确保
Load Diffusion Model节点加载了omnigen2_fp16.safetensors。 - 加载文本编码器:确保
Load CLIP节点加载了qwen_2.5_vl_fp16.safetensors。 - 加载 VAE:确保
Load VAE节点加载了ae.safetensors。 - 设置图像尺寸:在
EmptySD3LatentImage节点设置生成图片的尺寸(推荐 1024x1024)。 - 输入提示词:
- 在第一个
CLipTextEncode节点中输入正向提示词(想要出现在图像中的内容)。 - 在第二个
CLipTextEncode节点中输入负向提示词(不想要出现在图像中的内容)。
- 在第一个
- 开始生成:点击
Queue Prompt按钮,或使用快捷键Ctrl(cmd) + Enter(回车)来执行文生图。 - 查看结果:生成完成后对应的图片会自动保存到
ComfyUI/output/目录下,你也可以在SaveImage节点中预览。
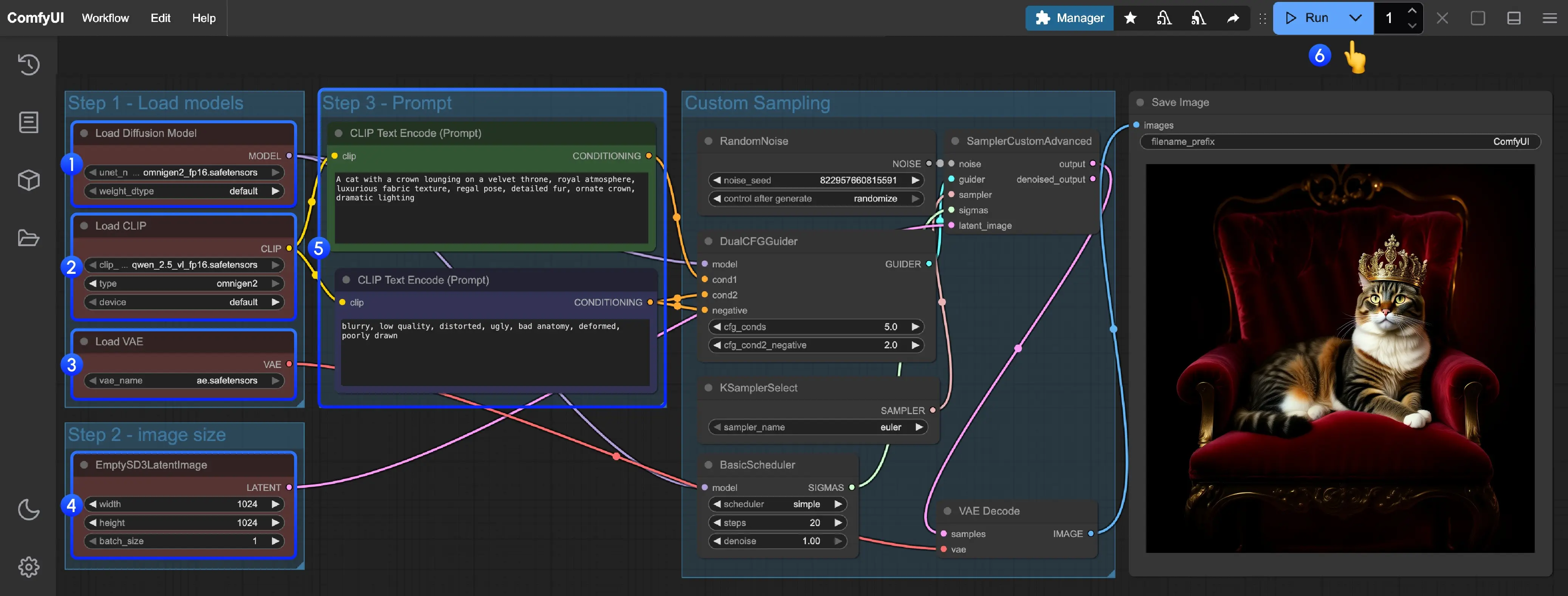
官方工作流默认的步数是20步,生成的图像会非常模糊,建议大家将步数调整50步。
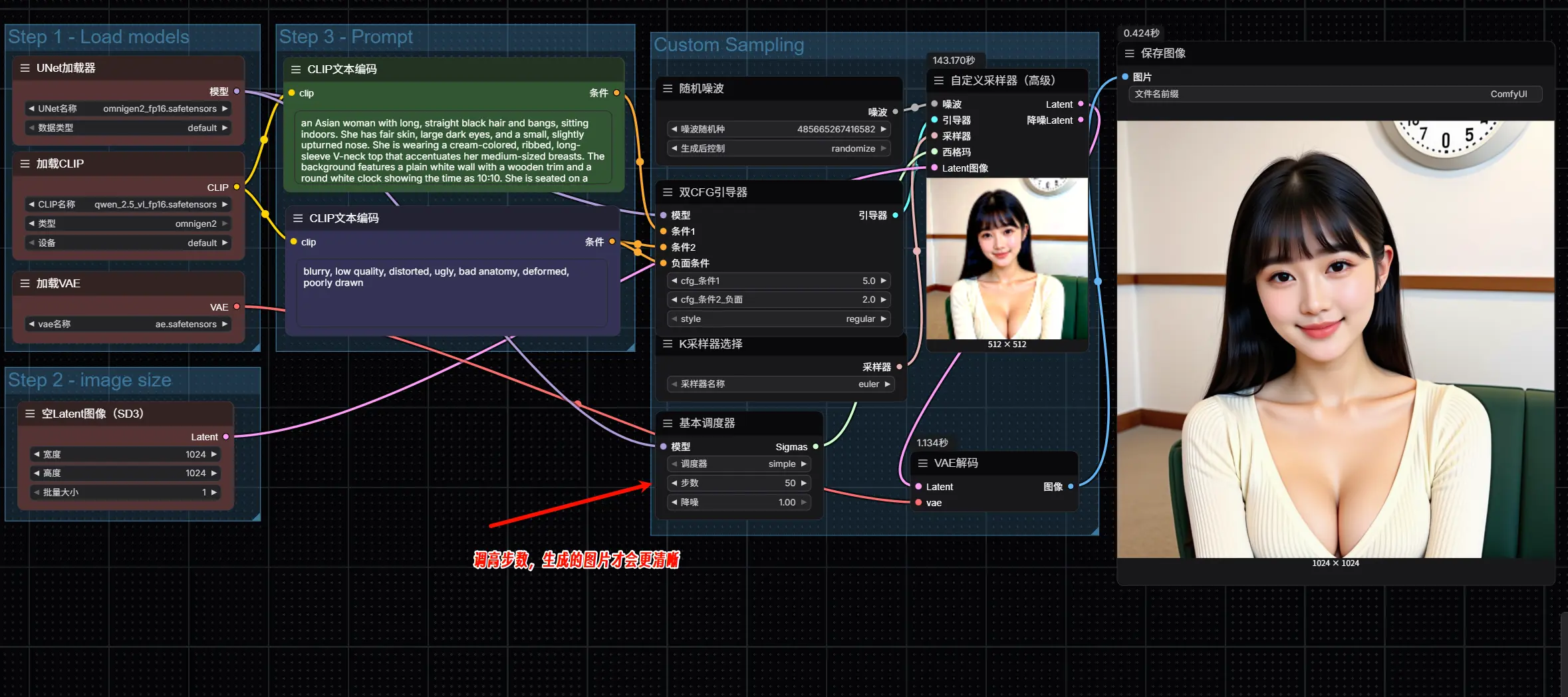
3. 配置关键节点
| 节点 | 设置要求 |
|---|---|
| Load Diffusion Model | 加载 omnigen2_fp16.safetensors |
| Load CLIP | 加载 qwen_2.5_vl_fp16.safetensors |
| Load VAE | 使用 ae.safetensors |
| EmptySD3LatentImage | 推荐设置为 1024x1024,也可自定义分辨率 |
| CLIPTextEncode (Positive) | 输入正向提示词,如:“一位穿汉服的女孩站在樱花树下,阳光明媚” |
| CLIPTextEncode (Negative) | 输入负向提示词,如:“模糊、畸变、低质量” |
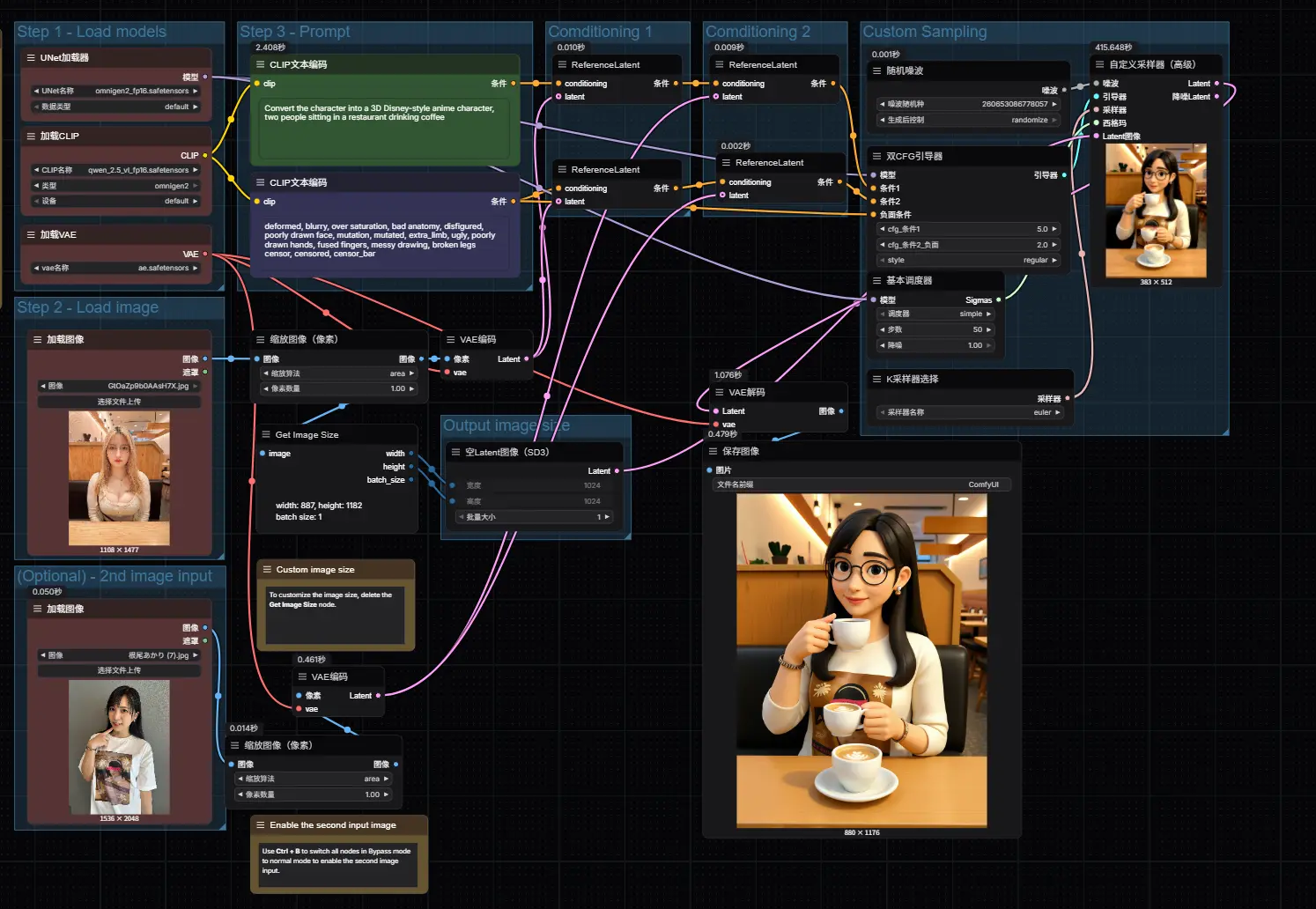
图像编辑工作流详解
OmniGen2 支持基于自然语言指令的精细化图像编辑,例如:
- “把猫换成狗”
- “给这个人戴上墨镜”
- “背景改为雪山”
- “在墙上添加一行英文‘Welcome’”
1. 获取工作流文件
从工作流模板中点击加载工作流,即可自动加载完整流程,工作流文件中已包含模型下载信息,加载后会提示下载对应模型。
2. 按步骤完成工作流运行
- 加载主模型:确保
Load Diffusion Model节点加载了omnigen2_fp16.safetensors。 - 加载文本编码器:确保
Load CLIP节点加载了qwen_2.5_vl_fp16.safetensors。 - 加载 VAE:确保
Load VAE节点加载了ae.safetensors。 - 上传图像:在
Load Image节点中上传提供的图片。 - 输入提示词:
- 在第一个
CLipTextEncode节点中输入正向提示词(想要出现在图像中的内容)。 - 在第二个
CLipTextEncode节点中输入负向提示词(不想要出现在图像中的内容)。
- 在第一个
- 开始生成:点击
Queue Prompt按钮,或使用快捷键Ctrl(cmd) + Enter(回车)来执行文生图。 - 查看结果:生成完成后对应的图片会自动保存到
ComfyUI/output/目录下,你也可以在SaveImage节点中预览。
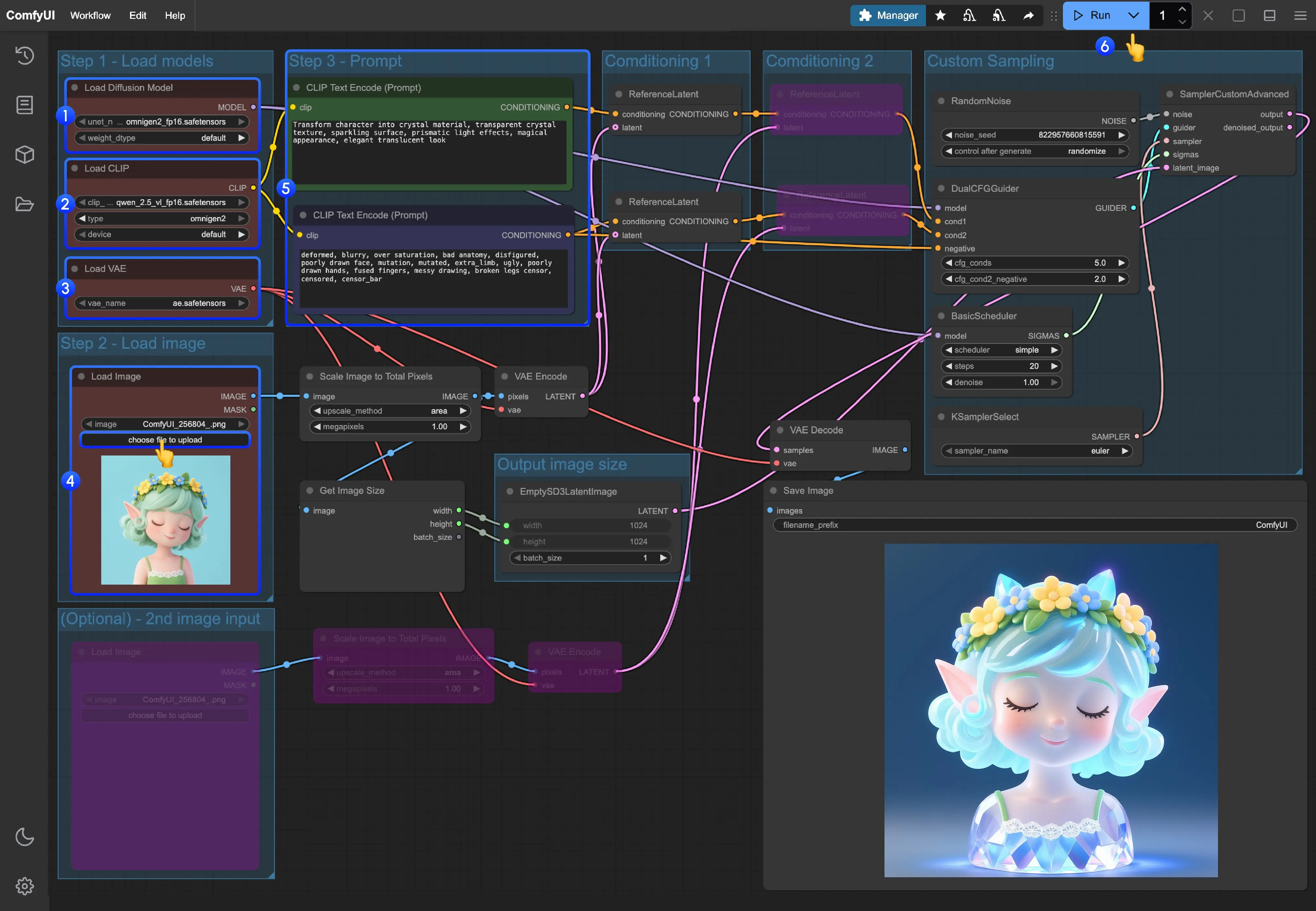
官方工作流默认的步数是20步,生成的图像会非常模糊,建议大家将步数调整50步。
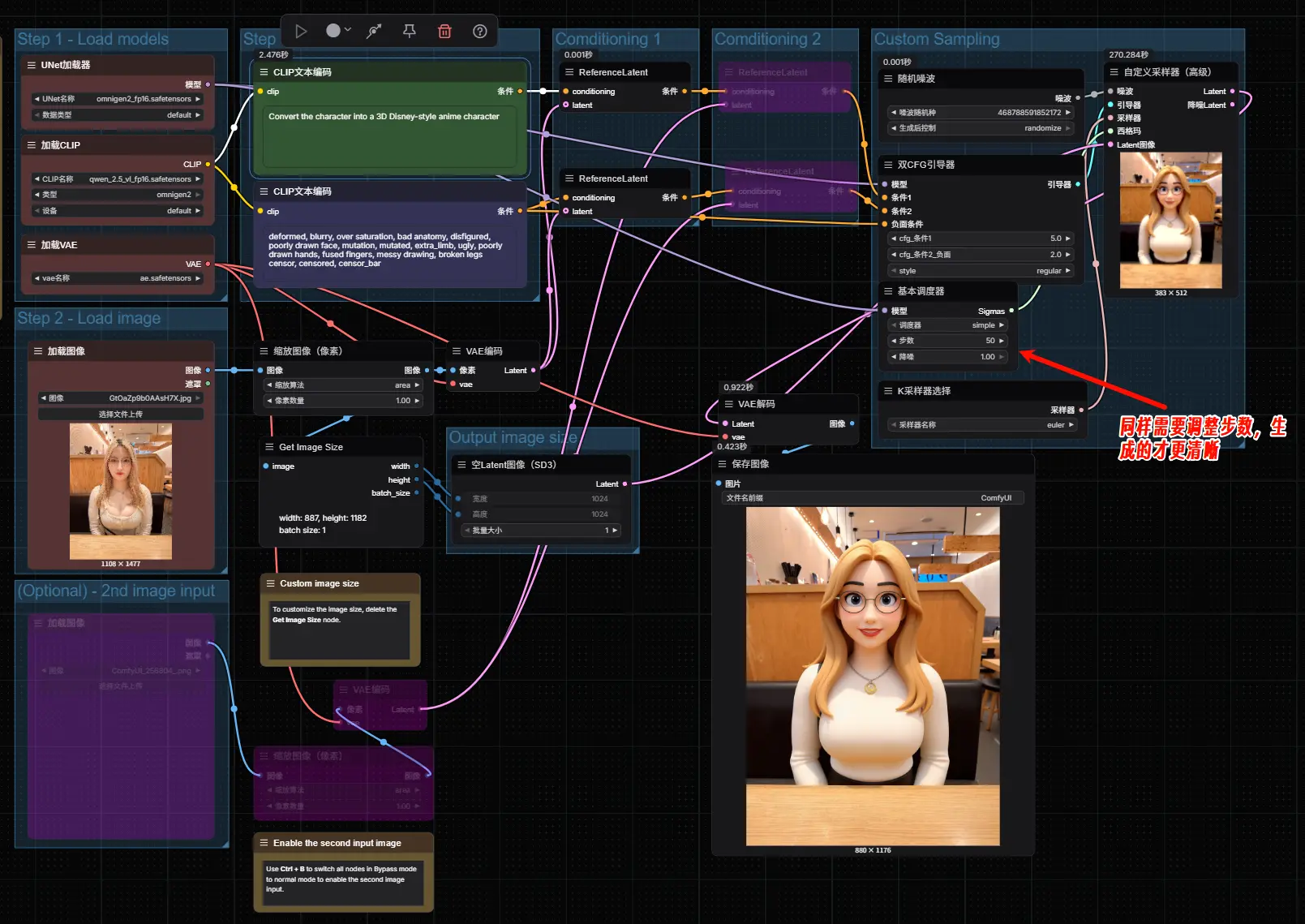
💡 提示:编辑效果受提示词精确度影响较大,建议使用具体描述而非模糊词汇。
补充说明:启用高级功能
▶ 启用第二张参考图
工作流中部分节点默认处于禁用状态(显示为粉紫色),如需输入第二张图像(如风格参考或对象迁移):
- 选中对应节点组
- 使用快捷键
Ctrl + B激活输入通道 - 连接额外的
Load Image节点
▶ 自定义输出尺寸
若需指定非默认分辨率:
- 删除
Get image size与EmptySD3LatentImage之间的连接 - 手动在
EmptySD3LatentImage中输入目标宽高(如1344x768)
适用场景与性能建议
| 场景 | 推荐配置 |
|---|---|
| 快速原型设计 | 1024×1024 分辨率,FP16 精度 |
| 显存有限设备(≤24GB) | 不建议开启多图输入,优先单图编辑 |
| 高精度输出需求 | 可尝试延长采样步数至 36~50,提升细节还原度 |
| 文字生成任务 | 需明确写出字体样式与排布位置,如:“醒目的红色艺术字写着‘Sale’” |
📌 实测反馈:在 RTX 4090D(24GB)上,1024×1024 图像生成平均耗时约 90 秒(含缓存后降至 60 秒以内)。
总结
OmniGen2 的出现,标志着我们正逐步迈向“单一模型、多种任务”的理想生成范式。它不仅能在文生图任务中表现出色,更在图像编辑、多图融合等复杂场景中展现出前所未有的灵活性与一致性。
结合 ComfyUI 的可视化编排能力,用户可以轻松构建跨任务的工作流管线,实现真正意义上的“可控创意”。
未来我们将持续跟进 OmniGen 系列更新,并推出进阶教程,包括:
- 局部重绘控制
- 多阶段编辑链设计
- 身份保持的人物编辑方案
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











