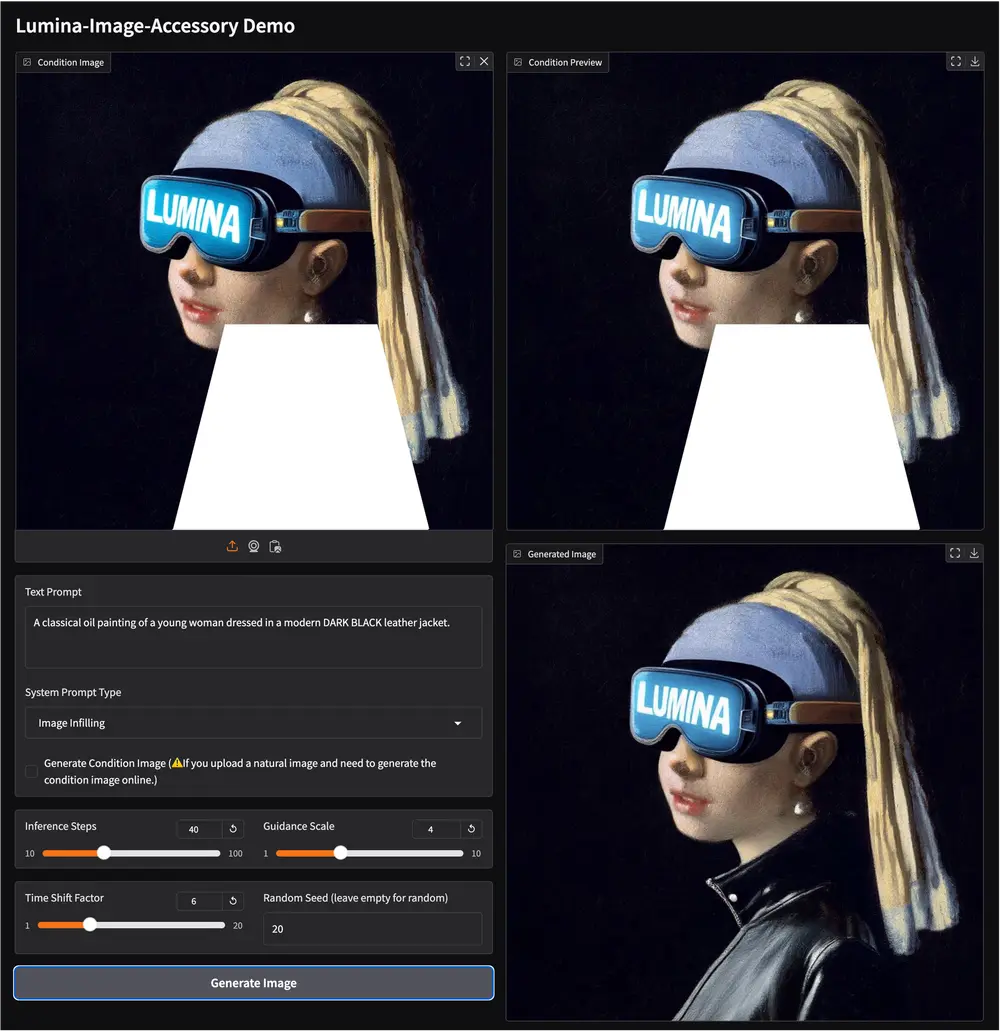
在上一代模型 OmniGen 发布仅 7 个月后,北京人工智能研究院正式推出了其升级版——OmniGen2,一个集成了视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力的统一多模态模型。
- 项目主页:https://vectorspacelab.github.io/OmniGen2
- GitHub:https://github.com/VectorSpaceLab/OmniGen2
- 模型:https://huggingface.co/OmniGen2/OmniGen2
- Demo:https://huggingface.co/spaces/OmniGen2/OmniGen2
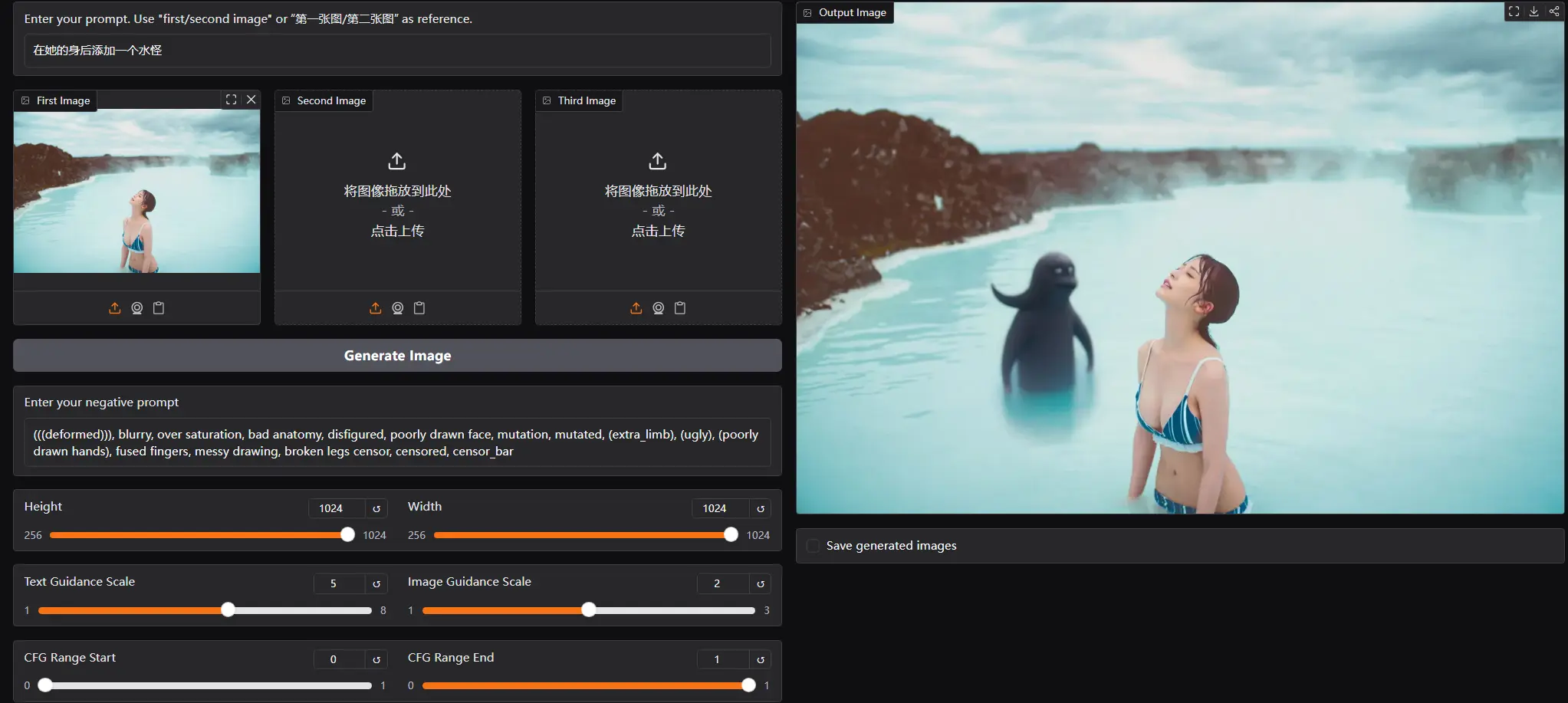
该模型不仅在图像质量和任务多样性方面有显著提升,还引入了独特的多模态反思机制,使 AI 在生成图像的同时具备“自我评估”和“迭代优化”的能力,为轻量级开源图像生成模型树立了新标杆。

🧠 核心功能一览
- ✅ 多模态统一框架:涵盖理解、生成、编辑与上下文重构
- ✅ 双路径解耦架构:兼顾语言建模与高质量图像输出
- ✅ 支持自然语言指令编辑:实现局部修改,保留整体一致性
- ✅ 基于主体的上下文生成:从参考图中提取并重新构建对象
- ✅ 内置反思机制:自动评估结果并优化输出质量
- ✅ 开源友好:适用于消费级 GPU 部署运行
🔬 模型架构详解
OmniGen2 采用双路径解耦架构,分别处理文本与图像任务:
- 自回归路径:负责文本理解和语言建模
- 扩散变换器路径:用于图像生成与编辑
关键设计在于将视觉信息与语言建模分离处理:
- ViT 编码器为 MLLM(多模态大语言模型)提供视觉特征,保持其语言推理能力不受干扰
- VAE 编码器则专注于为扩散模型提供精细图像特征
这种架构既保留了语言模型的强大推理能力,又实现了高保真、一致性强的图像输出。
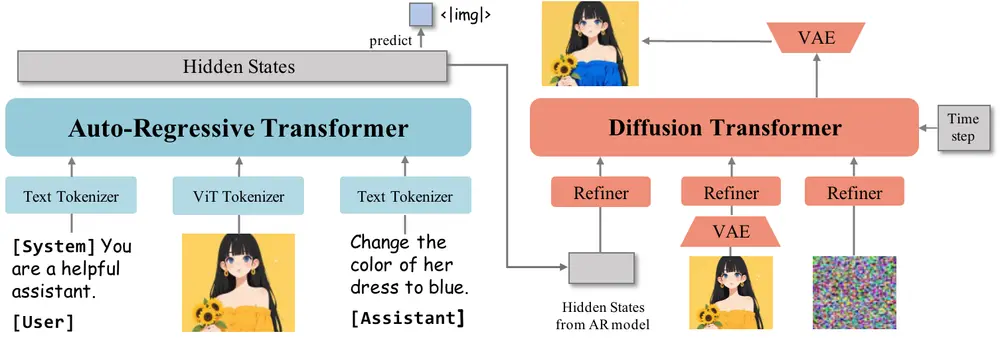
📐 多模态旋转位置嵌入(Omni-RoPE)
为了更好地支持复杂任务如图像编辑与上下文生成,OmniGen2 引入了 Omni-RoPE(Omni Multi-modal Rotary Positional Embedding)机制。
它将位置信息分为三部分:
- 序列与模态标识符 $ id_{seq} $:唯一标识不同图像,确保区分性
- 高度坐标 $ h $:表示图像标记的垂直位置
- 宽度坐标 $ w $:表示图像标记的水平位置
对于非图像内容,空间坐标设为零,从而实现跨模态的一致性表达。这一机制显著提升了模型在图像编辑等任务中的准确性和连贯性。
💡 主要功能模块解析
1. 视觉理解
OmniGen2 能高效理解图像内容,并结合文本输入完成推理任务。得益于冻结的 MLLM 结构和 ViT 编码器的支持,它在对象识别、语义对齐等方面表现优异。

2. 文本到图像生成
支持根据复杂自然语言描述生成高度忠实的图像。模型能有效捕捉组合关系与长提示细节,生成结果在语义与视觉层面都具备高度一致性。
3. 指令驱动图像编辑
用户可通过自然语言指令对图像进行精确修改,例如:
- 更换物体样式或颜色
- 调整构图或布局
- 添加或删除特定元素
模型能够保留未编辑区域的内容,确保整体视觉真实感。

4. 基于主体的上下文生成
OmniGen2 能够从参考图像中提取“主体”,并根据新提示将其置于全新背景中重新渲染。这一能力尤其适用于角色设定迁移、虚拟形象构建等场景。
5. 多模态反思机制
这是 OmniGen2 最具创新性的功能之一:
- 它不仅能生成图像,还能对其质量进行分析
- 通过图像-文本联合评估,识别问题并提出改进方向
- 实现自我修正与迭代优化,提升最终输出的可控性与可靠性
⚙️ 使用门槛与资源需求
尽管功能强大,但 OmniGen2 并非仅限于高端服务器环境:
- 最低推荐硬件配置:英伟达 RTX 3090 或约 17GB 显存 的等效显卡
- 低显存设备支持:可通过启用 CPU 卸载方式运行
- 性能优化建议:降低
cfg_range_end参数可在不影响质量的前提下提升推理速度
📊 小结对比表
| 功能 | 描述 |
|---|---|
| 架构 | 双路径解耦设计,兼顾语言建模与图像生成 |
| 输入支持 | 文本、图像、混合模态 |
| 输出支持 | 高质量图像、编辑图像、上下文重构图像 |
| 特色机制 | Omni-RoPE、反思机制、主体上下文生成 |
| 显存要求 | 推荐 17GB VRAM,可降级运行 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











