
智谱AI正式推出GLM-Image——业界首个开源的工业级离散自回归图像生成模型。这款模型创新性地采用自回归模块+扩散解码器的混合架构,既继承了自回归模型对复杂语义的精准理解能力,又兼具扩散模型高保真细节生成的优势,在文本渲染、知识密集型图像生成等场景实现显著突破,同时支持文生图、图生图、图像编辑等丰富任务,为图像生成领域提供了兼顾精度与创意的新方案。
- 项目主页:https://z.ai/blog/glm-image
- GitHub:https://github.com/zai-org/GLM-Image
- 模型:https://huggingface.co/zai-org/GLM-Image
- 魔塔:https://modelscope.cn/models/ZhipuAI/GLM-Image
GLM-Image的自回归模块基于90亿参数的GLM-4-9B-0414初始化,扩散解码器则沿用70亿参数单流DiT结构的CogView4。测试结果显示,其通用图像生成质量与主流潜在扩散模型持平,而在需要精确语义对齐、复杂信息表达的场景中表现尤为突出,填补了传统扩散模型在知识密集型任务中的能力短板。

研发背景:直击传统扩散模型的核心痛点
近年来,扩散模型凭借训练稳定性强、泛化能力优异的特点,成为图像生成领域的主流方案。但在实际应用中,端到端的扩散模型仍存在明显局限:面对复杂指令和知识密集型生成需求时,往往难以精准把握语义逻辑,在信息表达的准确性、细节与指令的对齐度上表现欠佳。
与此同时,部分新兴高质量图像生成模型展现出的优势,让业界看到了自回归建模的潜力——这类模型在处理需要丰富知识嵌入、复杂语义理解的图像生成任务时,能更好地兼顾逻辑一致性与细节表现力。
正是基于这一行业痛点,GLM-Image从设计之初就确立了双目标解耦的研发思路:将“复杂信息的稳健理解”与“高质量图像细节生成”拆分为两个独立模块,分别由自回归模型和扩散模型承担。其中,自回归模块负责生成承载低频语义信号的标记,勾勒图像的整体布局与核心内容;扩散解码器则专注于精炼高频细节,最终输出高保真的图像成果。这种分工协作的架构,让GLM-Image既具备艺术审美层面的表现力,又能满足信息传达的精准性要求。
核心技术细节:分层设计,兼顾语义与细节
GLM-Image的性能突破,源于其在视觉标记选择、自回归预训练、解码器架构等关键环节的精细化设计。
1. 视觉标记选择:语义-VQ策略平衡信息完整性与相关性
视觉标记是连接文本指令与图像生成的核心桥梁,不同标记类型直接影响模型的收敛效率与生成质量。此前主流的视觉标记方案分为三类,各有优劣:
- 离散重建训练的视觉编码:信息完整性高,但语义相关性弱;
- 离散语义训练的视觉编码:语义相关性强,信息完整性次之;
- 一维向量提取的统计语义特征:语义相关性强,但信息完整性不足,且与图像的对应性较弱。
GLM-Image最终选择语义-VQ作为核心标记化策略,具体采用XOmni的标记器方案。该方案的优势在于,能在标记建模过程中强化语义相关性,让模型更好地理解文本指令与图像元素的对应关系;同时结合扩散解码器,将语义标记还原为细节丰富的图像,实现“语义精准+细节保真”的双重目标。
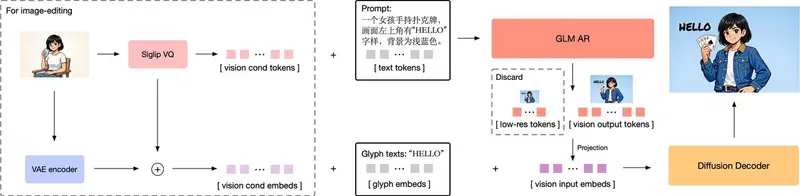
2. 自回归预训练:多分辨率训练+渐进式生成,提升高分辨率可控性
GLM-Image的自回归模块以GLM-4-9B-0414为基础,针对图像生成任务进行了针对性改造:
- 模型结构调整:冻结文本词嵌入层以保留语言理解能力,新增视觉词嵌入层用于视觉标记投影,同时将原语言模型头部替换为视觉LM头部;采用MRoPE位置嵌入,适配文生图、图生图任务中“文本+图像”交错排列的输入场景。
- 多分辨率分阶段训练:依次完成256px、512px、512px-1024px混合分辨率的训练流程。结合XOmni标记器16倍的图像压缩比,不同阶段的样本标记数量分别达到256、1024、1024-4096;再通过扩散解码器32倍的上采样因子,最终实现1024px-2048px的高分辨率图像生成。
- 渐进式生成策略优化:在低分辨率训练阶段,采用光栅扫描顺序生成标记;但随着分辨率提升,这种方法会导致模型可控性下降。为此,GLM-Image创新采用“先布局、后细节”的渐进式策略——生成高分辨率标记前,先生成256个与目标图像宽高比一致的低分辨率标记,确定图像整体布局;同时为这些布局标记增加训练权重,解决其因数量少而关注度不足的问题,显著提升高分辨率图像的生成质量。

3. 解码器框架:单流DiT架构+轻量化优化,兼顾效率与能力
扩散解码器是GLM-Image还原细节的关键,其核心设计围绕“语义标记驱动+细节补全”展开,同时通过架构优化降低计算成本:
- 骨干网络与扩散策略:沿用CogView4的单流DiT架构,采用流匹配作为扩散调度策略,保障训练稳定性与收敛效率。
- 轻量化条件输入设计:将语义-VQ标记通过投影层处理后,与VAE潜在表示沿通道维度连接,既保留输入序列长度,又几乎不增加额外计算开销;同时,由于语义-VQ标记已携带充足语义信息,解码器直接舍弃了传统的大型文本编码器,大幅降低内存占用与计算成本。
- 文本渲染能力强化:针对中文、长文本等复杂文本渲染需求,引入轻量级Glyph-byT5模型,对图像中的文本区域进行字符级编码,生成的字形嵌入与视觉嵌入沿序列维度连接,显著提升文本生成的准确性。
- 图像编辑细节保留优化:在图生图、图像编辑任务中,仅靠语义-VQ标记无法精准保留参考图像的高频细节。为此,GLM-Image将参考图像的VAE潜在表示与语义标记共同作为解码器的条件输入;同时采用块因果注意力机制,相比全注意力机制大幅减少kvcache计算开销,在保证细节保留能力的前提下提升运行效率。
4. 后训练优化:解耦强化学习,同步提升语义与细节质量
为进一步缩小“语义理解”与“细节生成”的能力差距,GLM-Image在训练后期采用解耦强化学习策略,分别对自回归模块和扩散解码器进行针对性优化,两者均采用GRPO算法训练(扩散解码器适配flow-GRPO变体):
- 自回归模块优化目标:聚焦低频奖励,提升语义一致性与艺术表现力。整合HPSv3美学评分、OCR文本渲染准确性评分、VLM语义正确性评估等多维度奖励,强化模型对复杂指令的遵循能力。
- 扩散解码器优化目标:聚焦高频奖励,精炼细节保真度与文本精准度。利用LPIPS指标优化感知纹理与细节相似度,结合OCR信号提升文本渲染质量,同时引入手部评分模型,解决图像生成中“手部细节失真”的行业通病。
全面评测:文本渲染与知识密集型任务优势显著
通过在多个权威基准测试中的验证,GLM-Image的性能优势得到充分印证,尤其在文本相关、知识密集型图像生成任务中表现突出。

1. 文本渲染专项测试:准确率领先,中文长文本表现亮眼
- CVTG-2k基准:在多区域文字生成任务中,2-5个区域的单词准确率平均值达到0.9116,归一化编辑距离(NED)达0.9557,文本生成精度远超多数开源及闭源模型。
- LongText-Bench基准:英文长文本生成得分0.9524,中文长文本得分高达0.9788,展现出对跨语言长文本的卓越理解与渲染能力,攻克了中文文本生成易失真的难题。
2. 通用图像生成测试:性能稳健,与主流模型持平
在OneIG_EN/OneIG_ZH、DPG Bench、TIFF Bench等通用基准测试中,GLM-Image表现稳定:
- OneIG英文综合得分0.528,中文综合得分0.511,其中文本子项得分分别达0.969、0.976,凸显文本对齐优势;
- DPG Bench密集提示词生成总体得分84.78,全局、实体、属性等细分指标均衡,能精准还原复杂描述中的图像元素;
- TIFF Bench短提示、长提示生成得分均超81分,表明模型对不同复杂度指令的适应能力一致可靠。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











