
智谱AI正式推出并开源 GLM-4.6V 系列多模态大语言模型,包含面向云端与高性能集群的 GLM-4.6V (106B) 基础模型,以及针对本地部署和低延迟场景优化的 GLM-4.6V-Flash (9B) 轻量化版本。该系列模型将上下文窗口扩展至 128K Token,在视觉理解与推理领域达到同等参数规模开源模型的 SOTA 性能,更重要的是首次集成原生多模态工具调用能力,打破传统多模态模型“感知”与“执行”分离的瓶颈,为多模态智能体落地提供统一技术底座。
- 项目主页:https://z.ai/blog/glm-4.6v
- GitHub:https://github.com/zai-org/GLM-V
- 模型:https://huggingface.co/collections/zai-org/glm-46v
核心突破:原生多模态工具调用,无需文本中转
传统大语言模型的工具调用依赖纯文本交互,处理图像、文档等多模态内容时需经过“视觉转文本”的中间步骤,不仅易造成信息丢失,还会增加系统复杂度。GLM-4.6V 实现的原生多模态工具调用,从根本上解决了这一问题:
- 多模态输入直达工具:图像、截图、文档页面可直接作为工具参数传递,无需预先转换为文字描述,完整保留视觉细节与格式信息。
- 多模态输出闭环推理:模型能直接理解工具返回的混合内容——包括搜索结果图表、网页截图、产品图片等,并将这些视觉信息纳入推理链,生成图文融合的结构化输出。
- 感知-执行闭环:通过原生支持,模型可自主完成“视觉感知→工具调用→结果理解→决策输出”的全流程,无需人工介入中转,大幅提升复杂任务的处理效率。
四大核心能力与典型应用场景
GLM-4.6V 凭借长上下文与多模态工具调用能力,可覆盖从内容创作到开发落地的全场景需求:
1. 富文本内容理解与创作:端到端生成结构化图文内容
模型支持输入论文、报告、幻灯片等多模态文档,实现从内容解析到创作的一站式处理:
- 复杂文档深度理解:精准识别文档中的文本、图表、公式、表格等元素,建立跨模态内容关联;
- 自主调用视觉工具:在生成内容时,自动调用工具从源文档中裁剪关键图表、截图等视觉元素;
- 视觉审核与编排:对候选视觉素材进行相关性、质量评估,过滤无效信息,最终生成可直接用于社交媒体、知识库的图文交错文章。
2. 视觉网络搜索:多模态搜索-推理-报告全链路
GLM-4.6V 构建了端到端的多模态搜索工作流,替代传统“文本搜索→人工配图”的模式:
- 意图识别与搜索规划:根据用户需求自动判断搜索类型(文搜图/图搜文),触发对应的检索工具;
- 多模态结果对齐:直接解析搜索返回的图文混合结果,筛选与查询最相关的信息片段;
- 结构化报告生成:融合文本与视觉线索,生成包含数据图表、案例图片的完整分析报告。
3. 前端复现与视觉交互:缩短“设计→代码”周期
针对前端开发场景,模型实现了从视觉设计到代码生成、交互式修改的全流程支持:
- 像素级还原设计稿:上传界面截图或设计文件,模型可识别布局、组件、配色方案,生成高保真的 HTML/CSS/JS 代码;
- 可视化交互式编辑:用户在生成页面的截图上圈选目标区域,用自然语言下达修改指令(如“将按钮左移10px并改为深蓝色”),模型可自动定位对应的代码片段并完成修改。
4. 128K长上下文理解:处理超大规模多模态内容
GLM-4.6V 的视觉编码器与 128K Token 上下文深度对齐,单次推理可处理海量多模态数据,相当于 150页复杂文档、200页幻灯片或1小时视频内容:
- 跨文档财务分析:同时处理多家上市公司的财务报表,跨文档提取核心指标,生成精准的对比分析表,无关键细节丢失;
- 长视频全局摘要与细粒度推理:对整场合足球比赛视频进行全局总结,同时可定位每个进球的时间戳、球员动作等细节信息。
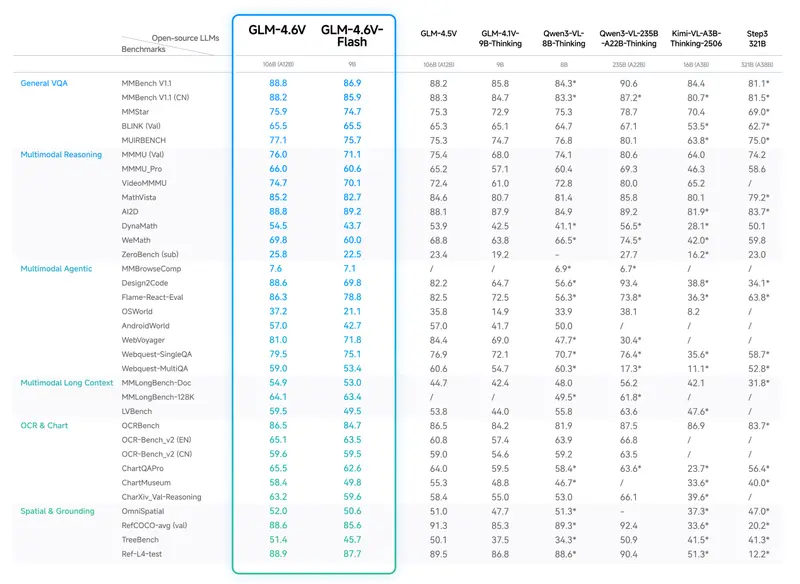
性能表现:同等参数规模开源模型达SOTA
在 MMBench、MathVista、OCRBench 等超过20个主流多模态基准测试中,GLM-4.6V 展现出领先性能:
- 在多模态理解、逻辑推理、长上下文处理等核心任务上,均达到同等参数规模开源模型的SOTA水平;
- 轻量化版本 GLM-4.6V-Flash (9B) 以更低的参数量,实现了与大模型相近的多模态基础能力,满足本地部署的低延迟需求。
核心技术支撑:从架构到训练的全方位优化
GLM-4.6V 的性能突破源于四大核心技术创新:
1. 长序列建模与跨模态对齐
- 将训练上下文窗口扩展至128K Token,并基于海量长上下文图文数据进行持续预训练;
- 借鉴 Glyph 视觉语言压缩对齐思想,利用大规模交错语料库增强视觉编码与语言语义的协同作用,提升跨模态信息关联能力。
2. 亿级多模态世界知识增强
在预训练阶段引入亿级规模的多模态感知与世界知识数据集,涵盖百科知识等多层次概念体系,既强化了基础视觉感知能力,又大幅提升跨模态问答的准确性与完整性。
3. 智能体数据合成与 MCP 协议扩展
- 基于大规模合成数据开展智能体训练,提升模型的工具调用规划能力;
- 扩展模型上下文协议(MCP):通过 URL 标识多模态内容,解决文件大小与格式限制,支持在多图像场景中精准操作特定图片;实现“草稿→图像选择→最终润色”的端到端图文输出机制,确保生成内容的高相关性。
4. 强化学习驱动的多模态智能体优化
- 将工具调用行为纳入通用强化学习(RL)目标,让模型在复杂工具链中的任务规划、指令遵循、格式规范能力更协调;
- 引入视觉反馈循环机制:模型利用视觉渲染结果(如生成的网页截图)自我纠正代码或动作,验证了多模态智能体自我改进的潜力。
体验与部署方式
- 在线体验:可通过 Z.ai 平台 或 智谱清言 App,选择 GLM-4.6 模型选项,直接体验多模态理解与工具调用能力;
- API 集成:通过与 OpenAI 兼容的 API,快速将 GLM-4.6V 集成到自有应用中;
- 本地部署:模型权重已在 HuggingFace 和 ModelScope 开源,支持 vLLM、SGLang 等高吞吐量推理框架,满足本地私有化部署需求。
GLM-4.6V 系列的发布,进一步降低了多模态智能体的开发门槛,其原生工具调用与长上下文能力,为企业级多模态应用落地提供了高效、低成本的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











