中国多所高校联合推出 DeepGen 1.0:50 亿参数小模型逆袭,图像生成与编辑能力媲美 800 亿巨无霸在AI领域,“大力出奇迹”似乎已成为一种默认法则:模型参数越大,效果越好。然而,由上海创智学院、复旦大学、中国科学技术大学、上海交通大学、浙江大学、西湖大学、南京大学以及南加州大学的研究人员共同推出的...图像模型# DeepGen 1.0# 多模态模型1个月前0700
阿里巴巴 Qwen 推出紧凑型多模态模型 Qwen3-VL 4B/8B,支持 FP8 低显存部署阿里巴巴通义千问(Qwen)团队于 2025 年 10 月 15 日正式发布 Qwen3-VL 4B 与 8B 两款稠密视觉语言模型,每款均提供 指令版(Instruction) 与 思维版(Reas...多模态模型# Qwen3-VL 4B# Qwen3-VL 8B# 多模态模型6个月前03390
IBM 推出 Granite Docling:专为文档转换优化的轻量级多模态模型IBM Research 正式发布 Granite Docling-258M,一款基于 IDEFICS3 架构构建的新型多模态图像-文本到文本模型,专为高效、准确的文档理解与结构化转换而设计。 Git...多模态模型# Granite Docling-258M# 多模态模型# 文档转换6个月前01060
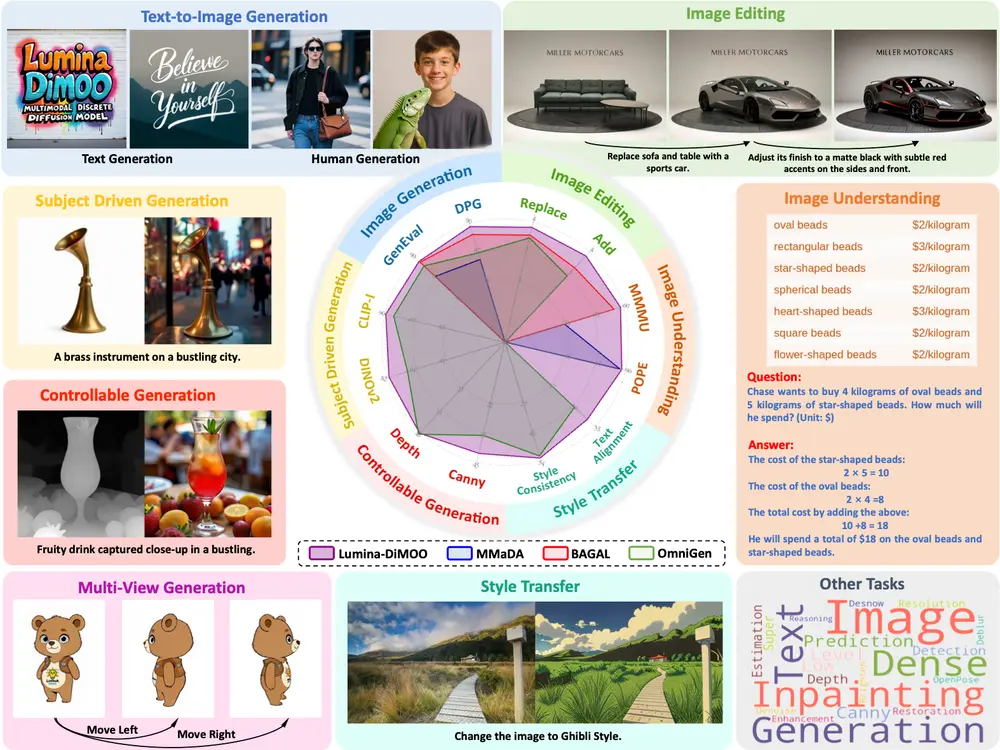
中国团队推出 Lumina-DiMOO:支持生成与理解的全能多模态模型由上海人工智能实验室牵头,联合上海创智学院、上海交通大学、悉尼大学、南京大学、香港中文大学和清华大学的研究团队,共同推出 Lumina-DiMOO ——一个面向多模态生成与理解一体化的新型基础模型。 ...图像模型# Lumina-DiMOO# 多模态模型7个月前02590
Thyme:会生成代码的多模态模型,突破“图像思考”边界由快手联合中科院自动化所、南京大学、清华大学、中国科学技术大学共同研发的Thyme,重新定义了视觉多模态模型的能力边界。它不再局限于传统的“用图像思考”,而是通过自主生成、执行代码,完成多样化的图像处...多模态模型# Thyme# 多模态模型7个月前01270
昆仑万维天工项目组推出多模态模型Skywork UniPic:能够统一处理图像理解、文本到图像生成和图像编辑等多种任务昆仑万维天工项目组推出多模态模型Skywork UniPic,它是一个参数量为15亿的自回归模型,能够统一处理图像理解、文本到图像生成和图像编辑等多种任务,而无需针对每个任务单独适配或连接模块。 Gi...多模态模型# Skywork UniPic# 多模态模型8个月前03830
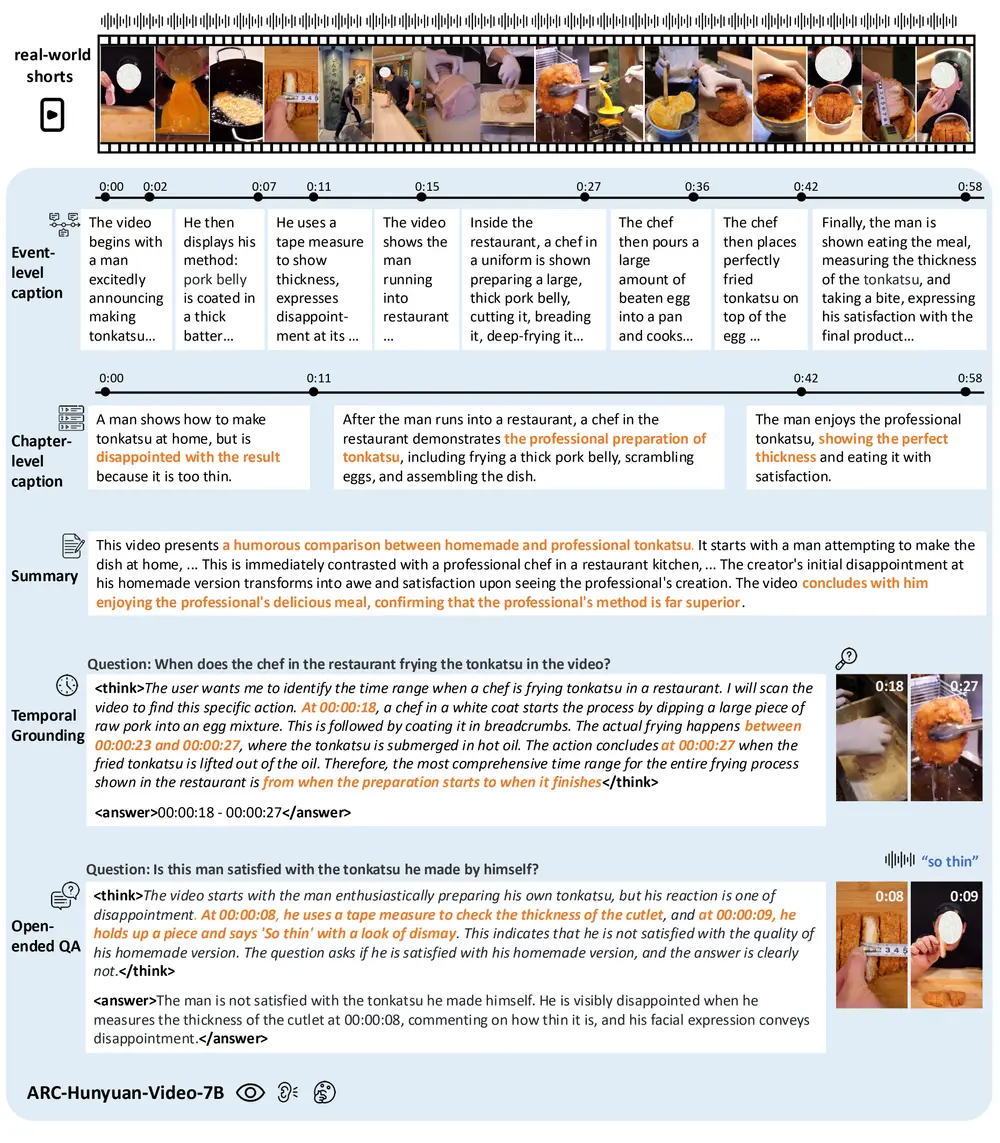
腾讯ARC实验室发布 ARC-Hunyuan-Video-7B:专为短视频理解而生的多模态模型在微信视频号、TikTok 等平台上,每天有数亿条用户生成的短视频被上传。这些视频内容多样、节奏快、信息密度高,往往融合了画面、语音、音效、文字甚至情绪表达。如何让AI真正“理解”这些视频,而不仅仅是...多模态模型# ARC-Hunyuan-Video-7B# 多模态模型# 腾讯ARC实验室8个月前05520
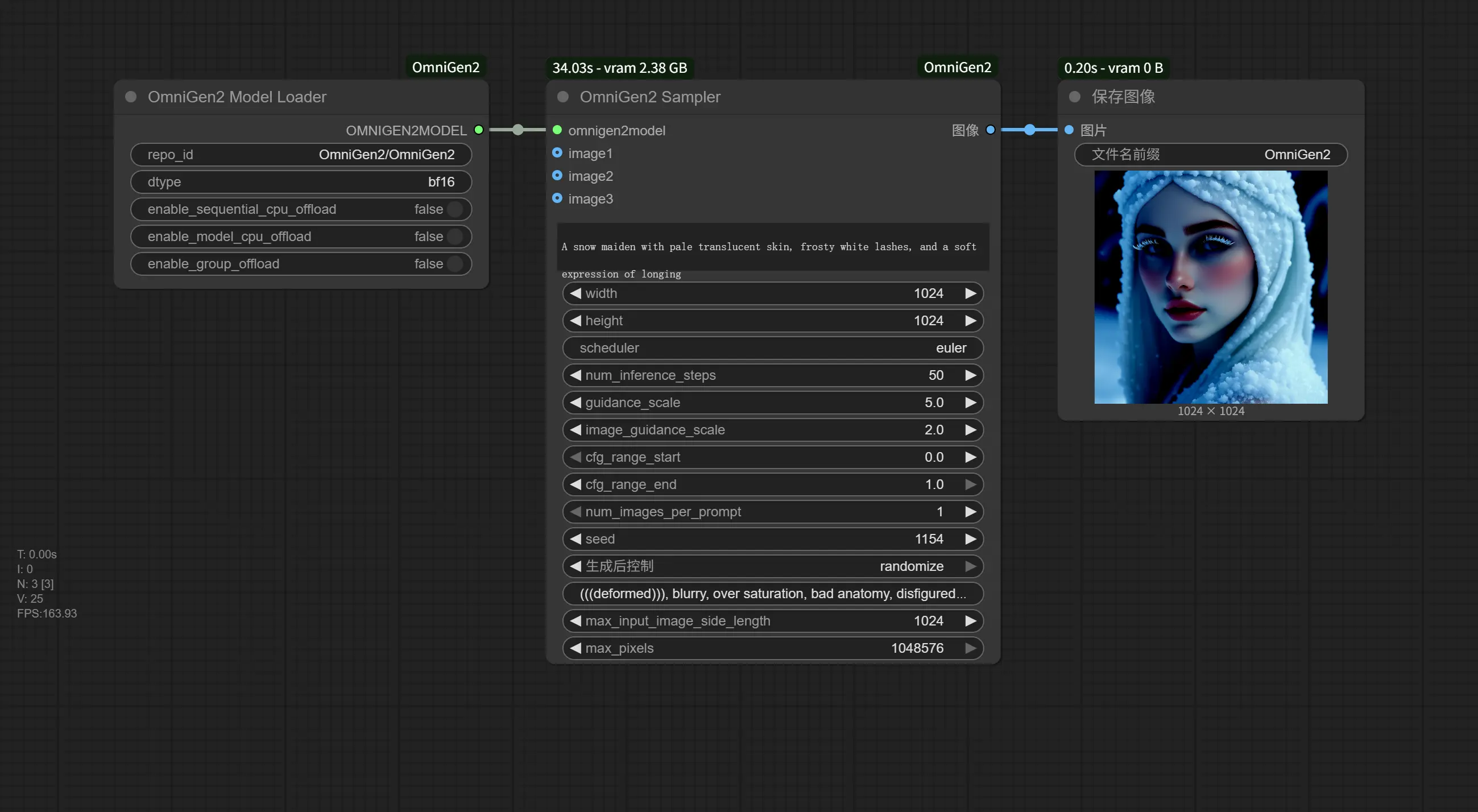
ComfyUI-OmniGen2:为多模态模型OmniGen2 打造的 ComfyUI 自定义节点插件北京AI研究院发布的集成了视觉理解、文本到图像生成、指令驱动编辑和基于主体的上下文生成能力的统一多模态模OmniGen2,如果你希望在 ComfyUI 中实现图像生成、编辑和视觉理解任务,那么 Com...插件# ComfyUI# OmniGen2# 多模态模型9个月前04420
开源版GPT-4o!字节跳动开源新一代多模态模型 BAGEL:多模态理解、图像生成、图像编辑,还能“思考”字节跳动发布了一款名为 BAGEL 的开源多模态基础模型,该模型拥有 70 亿活跃参数(总规模为 140 亿),在大规模交错多模态数据上进行训练。BAGEL 不仅在标准多模态理解排行榜中超越了当前主流...图像模型# BAGEL# GPT-4o# 多模态模型10个月前09170
字节跳动推出多模态文档图像解析模型Dolphin在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。 GitHub:https://github.com/bytedance/Dolphin...多模态模型# Dolphin# 多模态模型# 字节跳动9个月前04040
新型统一多模态模型家族 BLIP3-o:同时支持图像理解和图像生成任务Salesforce、马里兰大学、弗吉尼亚理工大学、纽约大学、华盛顿大学和加州大学戴维斯分校的研究人员推出新型统一多模态模型家族 BLIP3-o ,同时支持图像理解和图像生成任务。多模态模型是指能够处...多模态模型# BLIP3-o# 多模态模型11个月前02490
Ollama v0.7.0发布:添加新多模态模型引擎,多模态模型支持全面升级Ollama 最新发布的 v0.7.0 版本带来了对多模态模型的支持,标志着其在本地推理和模型集成能力上的重要突破。此次更新不仅扩展了视觉多模态模型的支持范围,还通过全新的多模态引擎提升了性能、准确性...早报# Ollama# 多模态模型# 多模态模型引擎11个月前05740