由快手联合中科院自动化所、南京大学、清华大学、中国科学技术大学共同研发的Thyme,重新定义了视觉多模态模型的能力边界。它不再局限于传统的“用图像思考”,而是通过自主生成、执行代码,完成多样化的图像处理与计算操作,让高分辨率感知、复杂推理等难题有了更高效的解决路径。
- 项目主页:https://thyme-vl.github.io
- GitHub:https://github.com/yfzhang114/Thyme
- 模型:https://huggingface.co/collections/Kwai-Keye/thyme-689ebea74a628c3a9b7bd789
比如面对“识别图像中极小区域文字”这类需求,普通模型可能因目标过小直接识别失败,而Thyme会先分析问题,自动生成“图像放大+精准裁剪”的执行代码,优化图像后再进行识别——整个过程无需人工干预,像给模型配备了“自主解题的工具箱”。
核心定位:不止于“看”,更能“主动解决”
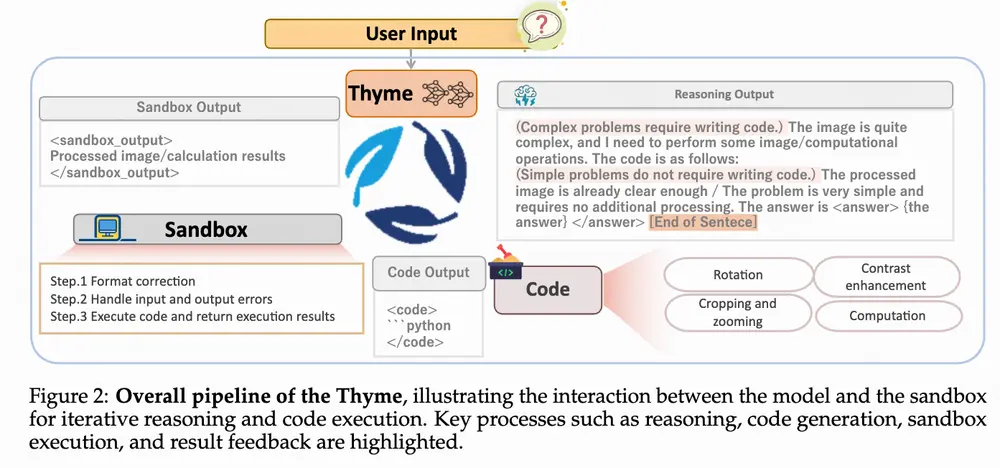
Thyme的全称是“Think Beyond Images”,从命名就能看出其核心突破:它是一款具备代码生成与执行能力的多模态大语言模型(MLLM) 。
传统视觉多模态模型的逻辑是“输入图像→直接分析”,面对高分辨率图像的细节丢失、复杂场景的信息干扰时,很容易出现判断偏差;而Thyme的逻辑是“输入需求→分析问题→生成代码→优化处理→输出结果”,通过代码这一“中间工具”,填补了“感知”与“精准解决”之间的差距。
四大核心功能:覆盖从处理到推理的全流程
1. 多样化图像处理:精准优化视觉输入
支持裁剪、缩放、旋转、对比度增强等常用操作,还能根据图像问题动态组合操作——比如处理倾斜的低清文档时,会先生成“旋转校正”代码,再执行“对比度增强”,最后通过“裁剪”聚焦有效区域,为后续分析扫清障碍。
2. 复杂数学计算:代码化提升推理精度
面对需要计算的问题(如“图像中两个目标的实际距离”“工程图纸中的尺寸换算”),Thyme会将数学逻辑转化为可执行代码,通过代码运算替代模型“主观判断”,大幅降低复杂推理中的误差。
3. 自主决策能力:无需人工干预的“问题诊断”
模型会先评估需求与图像的匹配度:若图像清晰、问题简单,直接输出结果;若存在“目标过小”“角度倾斜”“计算复杂”等问题,会自主决定需要执行的操作类型,甚至规划多步操作的顺序。
4. 高效端到端训练:快速解锁全能力
通过“监督微调(SFT)+强化学习(RL)”的组合训练模式,无需漫长训练周期即可激活核心能力——仅需200 GPU小时的SFT训练,就能让模型掌握基础的代码生成与图像处理逻辑,后续RL阶段再进一步优化精度。
四大关键特点:为什么Thyme能脱颖而出?
1. 高自主性:从“被动响应”到“主动解决”
区别于需要人工指定操作的工具型模型,Thyme的核心优势在于“自主”:无需提前设定处理规则,模型会根据问题场景动态生成代码、执行操作,全程无需人工介入,适配更复杂的未知场景。
2. 训练效率高:短周期激活全能力
传统多模态模型要覆盖“图像处理+代码生成+推理”等多能力,往往需要数千GPU小时的训练;而Thyme通过精心设计的两阶段训练,仅用200 GPU小时完成SFT阶段,再通过RL阶段优化,大幅降低了训练成本与时间。
3. 性能稳定提升:近20个基准测试验证
在感知、推理、一般任务三大类近20个基准测试中,Thyme均表现出“一致且显著”的提升:高分辨率感知任务性能超现有方法25%以上,数学推理任务优于开源模型,即便是对综合能力要求高的一般任务,也能保持稳定优势。
4. 强适应性:灵活应对复杂场景
能根据问题复杂度动态调整策略:简单问题直接处理,复杂问题调用工具,甚至在单次任务中完成“裁剪+缩放+旋转”的多步操作;遇到未见过的场景时,也能通过代码定义新工具,避免“能力边界局限”。
工作原理:两阶段训练+创新算法,平衡“探索”与“精度”
Thyme的能力不是凭空而来,而是依赖“数据+算法”的双重支撑,核心分为两个训练阶段:
阶段1:监督微调(SFT)——打牢基础能力
- 数据支撑:使用包含500K样本的精心标注数据集,覆盖6大核心场景:无需编码的基础图像操作、高分辨率图像裁剪、大角度旋转校正、低对比度增强、复杂代码计算、多轮交互任务;
- 训练目标:让模型掌握“问题分析→代码生成→操作执行”的基本逻辑,能应对常见场景的需求,为后续优化打下基础。
阶段2:强化学习(RL)——提升精度与适应性
- 难度升级:手动收集高分辨率问答对,增加训练难度(如“从4K监控图中识别远处车牌”),逼迫模型优化处理策略;
- 核心算法GRPO-ATS:这是Thyme的关键创新——通过“自适应温度采样”,为“文本生成”和“代码生成”设置不同的“探索系数”:文本生成保留一定灵活性以应对多样需求,代码生成则降低随机性以确保执行精度,最终实现“推理不僵化、代码不报错”的平衡。
实测表现:三大任务场景,性能全面领先
1. 感知任务:高分辨率场景优势显著
在监控、自动驾驶等依赖高分辨率图像的场景中,Thyme能通过代码优化图像细节,性能提升超过25%——比如在4K道路图像中识别远处交通标志,准确率比传统模型高近30%。
2. 推理任务:数学计算误差大幅降低
面对MathVision、MathVista、MathVerse等数学推理基准测试,Thyme通过代码将复杂计算转化为“精确运算”,避免模型“凭经验估算”的偏差,部分任务的推理准确率提升超20%。
3. 一般任务:综合能力更稳定
在Hallucination bench(减少幻觉)、MMStar(多模态综合)、MMVet Hard(高难度多模态)等测试中,Thyme在“感知+推理”结合的任务中表现突出,比如“根据医学影像描述计算病变体积”,准确率比同类模型高15%以上。
应用场景:从专业领域到日常交互,落地潜力广泛
1. 高分辨率图像处理:精准识别微小目标
- 监控领域:从4K/8K监控视频中识别远处车牌、人脸;
- 医疗领域:在医学影像(如CT、MRI)中识别微小病变(如早期肿瘤结节);
- 工业领域:从高清工业相机图中检测产品表面的细微划痕。
2. 复杂推理任务:解决“计算型”难题
- 工程设计:计算建筑图纸中的结构应力、构件尺寸换算;
- 金融分析:根据市场数据生成代码,计算投资风险系数;
- 科研领域:处理实验图像数据,通过代码计算实验结果(如“细胞计数”“粒子轨迹分析”)。
3. 多轮交互任务:逐步细化需求
适用于需要“逐步优化”的场景,比如:用户先要求“放大图像某区域”,Thyme处理后,用户再要求“增强该区域对比度”,模型能基于前一步结果调整操作,无需重新开始。
4. 实时交互系统:快速响应需求
由于训练高效、推理速度快,Thyme可适配智能客服、虚拟助手等实时场景——比如用户向虚拟助手发送“识别合同中的小字条款”,模型能在几秒内完成“放大+裁剪+识别”,快速反馈结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











