
近日,蚂蚁集团旗下的 百灵大模型(Ling)团队 正式宣布开源其最新推出的统一多模态大模型 —— Ming-Lite-Omni。这是一款基于 Ling 系列轻量模型构建的 MoE 架构全模态 AI 模型,总参数达 220 亿(22B),激活参数为 28 亿(3B),具备强大的多模态理解与生成能力。
- 项目主页:https://lucaria-academy.github.io/Ming-Omni
- GitHub:https://github.com/inclusionAI/Ming/tree/main/Ming-omni
- Hugging Face:https://huggingface.co/inclusionAI/Ming-Lite-Omni
- 魔塔:https://www.modelscope.cn/models/inclusionAI/Ming-Lite-Omni
这是继 Ling-lite、Ling-plus 和 Ming-lite-uni 等模型之后,百灵团队在开源领域的又一重磅动作,标志着其在多模态大模型技术上的持续突破。

什么是 Ming-Lite-Omni?
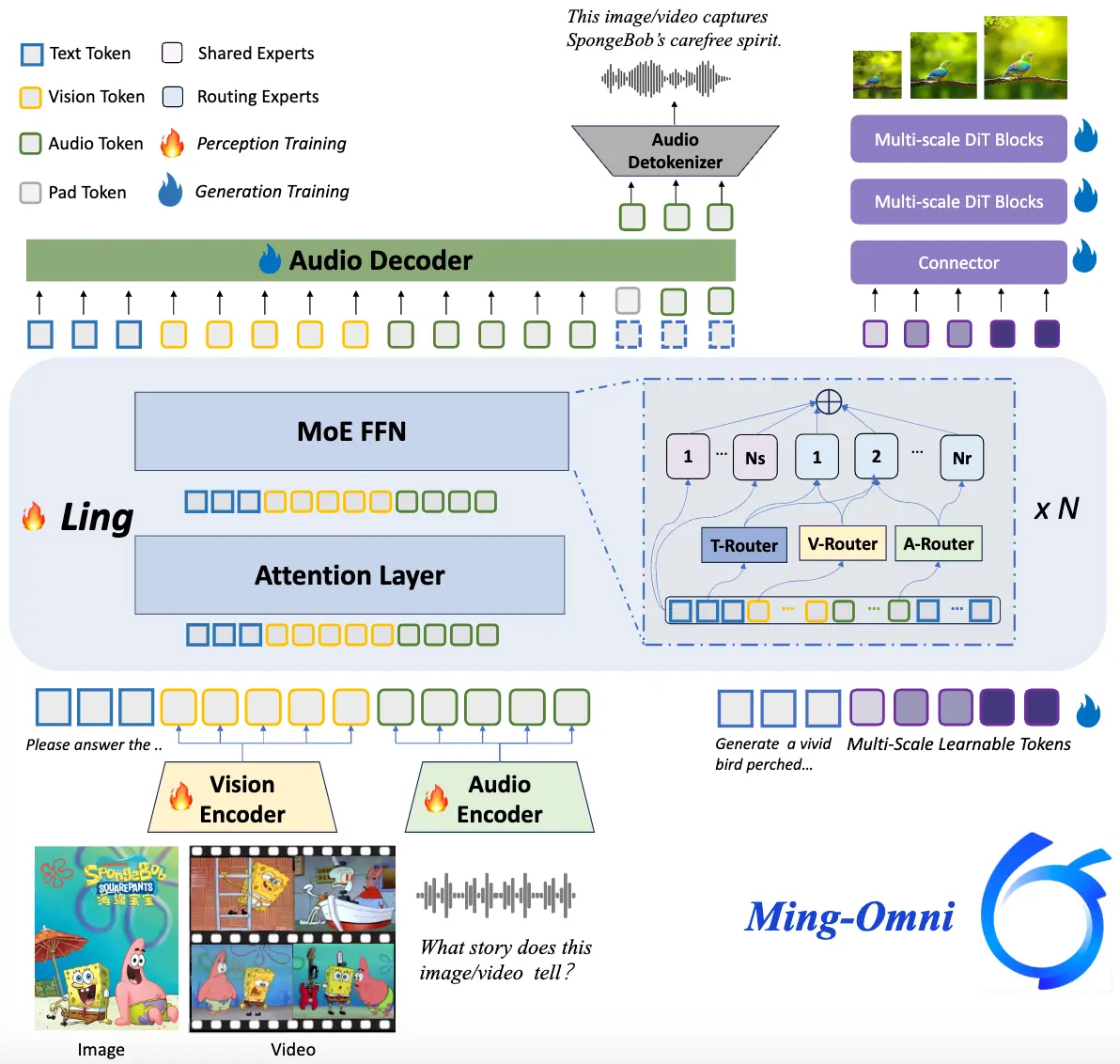
Ming-Lite-Omni 是 Ming-Omni 的轻量化版本,由 Ling-Lite 大语言模型驱动,采用 MoE(专家混合)架构,并引入“模态特定路由器”机制,实现了对多种模态输入(如图像、文本、音频、视频)的统一理解与生成。
它不仅能识别多模态内容,还能根据指令生成高质量文本、自然语音和生动图像,真正实现“看、听、说、画”一体化。
🔍 核心特性一览
✅ 统一多模态感知
- 支持图像、文本、音频、视频等所有主流模态;
- 使用专用编码器提取不同模态 token;
- 通过“模态特定路由器”协调处理,避免任务冲突;
- 在单一模型中完成跨模态融合,无需多个子模型或任务微调。
✅ 统一理解与生成
- 可在生成过程中解读用户意图;
- 支持上下文感知对话;
- 提供文本到语音、图像编辑、跨模态问答等多种功能;
- 实现从“理解”到“创造”的完整闭环。
✅ 创新生成能力
- 高质量图像生成与编辑:集成 Ming-Lite-Uni 图像解码模块;
- 自然语音合成:使用高级音频解码器,输出流畅语音;
- 支持原生分辨率图像生成与风格迁移;
- 能应对复杂多模态交互场景,如音视频问答、图像字幕生成等。
📊 性能对比:表现强劲,部分指标超越竞品
在多项基准测试中,Ming-Lite-Omni 表现出色:
| 模型 | 参数规模 | 图像理解得分(AI2D/HallusionBench/MMBench) | 视频理解得分(VideoMME/MVBench) | 音频理解得分(SpeechQA) | 图像生成 FID 值 |
|---|---|---|---|---|---|
| Ming-Lite-Omni | 2.8B 激活参数 | 71.4 | 59.4 | 4.34 | 4.85(SOTA) |
| Qwen2.5-VL-7B | 7B | 71.5 | 59.2 | 4.21 | N/A |
| Kimi-Audio | 不详 | N/A | N/A | 4.215 | N/A |
| SDXL | 不详 | N/A | N/A | N/A | 6.0+ |
🌟 关键亮点:
- 图像理解:在对象识别任务中,Ming-Lite-Omni 平均得分 58.54,优于 Qwen2.5-VL-7B 的 54.43。
- 视频理解:在 LongVideoBench 中表现优于 Qwen2.5-VL-7B。
- 语音理解:在 aishell2 测试中表现优于 Qwen2.5-Omni。
- 图像生成:GenEval 得分 0.64,FID 值 4.85,刷新现有方法 SOTA。
💡 技术创新:MoE + 模态路由,让统一多模态成为可能
Ming-Lite-Omni 的核心在于其创新性的架构设计:
- 基于 Ling-Lite 的 MoE 架构:不仅高效节省计算资源,还保证了多模态处理的灵活性;
- 模态特定路由器:动态分配专家网络资源,提升模态间协同效率;
- 统一框架下处理与生成:无需任务微调即可完成多种复杂操作,极大简化部署流程。
这种设计使得一个模型就能胜任从图像识别到语音生成、再到视频分析的多样化任务,打破了传统多模态系统依赖多个独立模型的限制。
⚙️ 开源价值:推动社区研究与定制化落地
蚂蚁集团强调,Ming-Lite-Omni 所有代码和模型权重均已开源,目标是:
- 推动多模态大模型的研究边界;
- 降低企业与开发者接入门槛;
- 加速多模态应用的落地进程。
据官方介绍,Ming-Lite-Omni 是目前首个在模态支持上与 GPT-4o 相当的开源模型,填补了国内多模态开源生态的一项空白。
📌 应用场景广泛,覆盖未来智能体验
Ming-Lite-Omni 的强大能力使其适用于多个高价值场景:
🎥 实时音视频交互
- 语音助手、视频摘要生成;
- 视频内容自动标注与检索;
- 教育、客服、虚拟人等互动场景。
🖼️ 创意内容生成
- 文本到图像生成;
- 图像风格迁移与编辑;
- 助力设计师快速生成视觉素材。
🧾 跨模态任务处理
- 音视频问答(如语音提问+图像回答);
- 图像字幕生成;
- 医疗、金融等行业的多模态辅助决策系统。
🧩 优势与挑战并存
✅ 优势:
- 多模态统一性强:单一模型搞定图像、文本、音频、视频;
- 生成能力强:语音自然、图像质量领先;
- 高效节能:仅需 2.8B 激活参数,却能达到更大模型的效果;
- 完全开源:促进学术研究与商业定制。
❗ 潜在挑战:
- 参数规模有限:虽然效率高,但在某些极端复杂任务中仍弱于超大规模闭源模型;
- 训练数据依赖:高质量多模态数据获取难度较大;
- 硬件要求较高:实时多模态交互对设备性能有一定要求。
🚀 百灵大模型持续开源,打造 AI 生态体系
今年以来,百灵大模型已陆续开源多个重要模型:
| 模型名称 | 类型 | 特点 |
|---|---|---|
| Ling-lite | LLM | 轻量级语言模型 |
| Ling-plus | LLM | 性能更强的语言模型 |
| Ming-lite-uni | 图像生成 | 高质量图像生成 |
| Ming-lite-omni-preview | 多模态预览版 | 初步实现统一多模态 |
| Ming-lite-omni | 全模态 | 当前最完整的统一多模态模型 |
这一系列动作表明,百灵大模型正在从“单模态”走向“统一多模态”,并逐步构建起一个开放、灵活、高效的多模态 AI 生态。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











