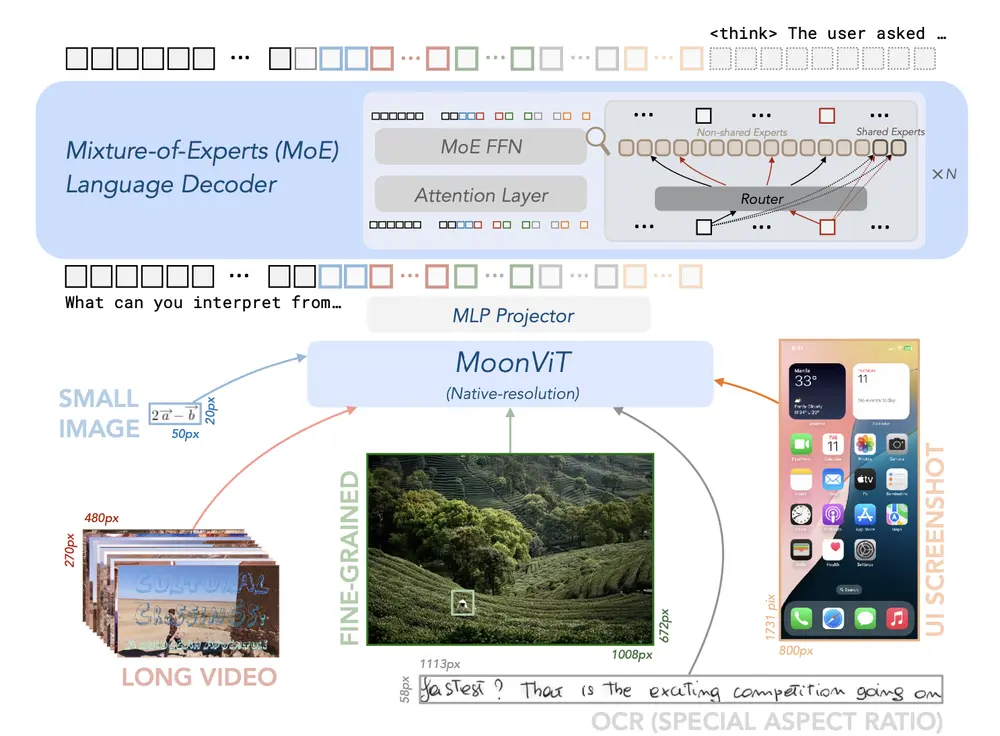
新加坡国立大学和微软的研究人员推出用于 GUI(图形用户界面) 自动化的视觉代理模型ShowUI ,它是一个结合了视觉、语言和行动能力的大模型,旨在提高人机交互的效率和生产力。ShowUI通过理解和执行与GUI相关的复杂任务,展示了其在数字世界中的创新能力。简单来说,其类似于Claude之前推出的Computer Use,能够通过自然语言来控制 AI 实现点击、输入、选择、滚动等操作。目前开发者已经释出一款2B参数大小的ShowUI-2B,,该模型实现了 75.1% 的准确率,性能提高了 1.4 倍。
- GitHub:https://github.com/showlab/ShowUI
- 模型:https://huggingface.co/showlab/ShowUI-2B
- Demo:https://huggingface.co/spaces/showlab/ShowUI
ShowUI模型的核心在于它能够处理GUI任务,这些任务通常涉及理解屏幕截图、解析用户指令,并在GUI环境中执行相应的动作。例如,用户可能要求ShowUI在某个软件中创建一个文档或填写表单,ShowUI需要能够理解这个请求,识别屏幕上的相关元素,并执行点击或输入等动作来完成任务。

主要功能
- UI引导的视觉令牌选择(UI-Guided Visual Token Selection):通过将屏幕截图视为一个连接图,自适应地识别冗余关系,并在自注意力模块中作为令牌选择的标准,从而减少计算成本。
- 交错视觉-语言-行动流(Interleaved Vision-Language-Action Streaming):统一GUI任务中的多样化需求,有效管理视觉-行动历史,提高训练效率。
- 小规模高质量GUI指令遵循数据集:通过精心的数据策划和采用重采样策略,解决显著的数据类型不平衡问题。
主要特点
- 轻量级模型:ShowUI是一个2B(即2亿参数)的模型,使用256K数据,实现了75.1%的零样本屏幕截图定位准确率。
- 减少冗余视觉令牌:在训练期间减少了33%的冗余视觉令牌,提高了1.4倍的训练速度。
- 跨环境导航实验:在Web、移动设备和在线环境中展示了模型的有效性和潜力。
工作原理
ShowUI的工作原理包括以下几个关键步骤:
- 构建UI连接图:将屏幕截图分割成规则的块,每个块作为一个节点,通过识别相同RGB值的相邻块来形成连接组件,从而简化冗余区域。
- 视觉令牌选择:在训练期间,在每个组件中随机选择一部分令牌,保留它们原始的位置信息,以减少计算量。
- 交错VLA流:将视觉和行动信息按顺序组合,以处理历史信息,如先前的动作和观察结果。
- 数据策划和重采样:选择代表性的数据,并在训练期间通过平衡不同数据类型的概率,确保模型在不同设置下的性能一致性。

具体应用场景
ShowUI可以应用于多种GUI自动化任务,包括但不限于:
- Web自动化:自动完成网上表单填写、数据输入等任务。
- 移动应用操作:在移动设备上执行点击、滑动等操作,以自动化应用程序中的流程。
- 桌面软件交互:在桌面环境中执行文件管理、应用程序设置更改等任务。
- 跨平台GUI导航:在不同的设备和平台上实现一致的GUI导航和操作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











