DeepSeek-VL2 是由深度求索(DeepSeek-AI)推出的一系列先进混合专家(MoE, Mixture of Experts)视觉语言模型,旨在显著提升其前代产品 DeepSeek-VL 的性能和功能。DeepSeek-VL2 在多个任务中展示了卓越的能力,包括视觉问答、光学字符识别(OCR)、文档/表格/图表理解以及视觉定位等。该模型系列包含三个变体,分别具有1.0B、2.8B和4.5B激活参数,以适应不同的计算需求。
- GitHub:https://github.com/deepseek-ai/DeepSeek-VL2
- 模型:https://huggingface.co/collections/deepseek-ai/deepseek-vl2-675c22accc456d3beb4613ab
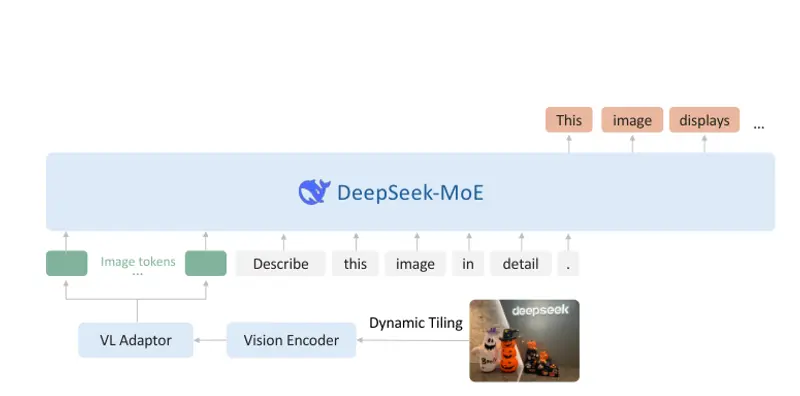
亮点与创新
1、数据扩展与新能力引入
- 优质训练数据翻倍:DeepSeek-VL2 使用的训练数据量是其前代的两倍,涵盖了更多的高质量图像和文本对,增强了模型的理解能力。
- 新任务支持:引入了梗图理解、视觉定位、视觉故事生成等新能力,使模型能够处理更多样化的任务。
- 科研文档学习:通过学习更多科研文档数据,DeepSeek-VL2 可以更好地理解复杂的科研图表,并通过 Plot2Code 功能根据图像生成 Python 代码,适用于科学计算和数据分析领域。
2、动态平铺视觉编码策略
- 支持动态分辨率图像:DeepSeek-VL2 采用了一种创新的切图策略,将图像分割成多个子图和一张全局缩略图,从而支持高分辨率图像(最多1152x1152)和极端长宽比(如1:9或9:1),适配更多应用场景。
- 高效处理不同长宽比:这一策略使得模型能够灵活应对各种图像尺寸和比例,提高了视觉理解的鲁棒性。
3、优化的语言模型架构
- 压缩Key-Value缓存:通过将Key-Value缓存压缩到潜在向量,显著减少了内存占用,提升了训练和推理效率。
- MoE架构:语言部分采用了混合专家(MoE)架构,结合了稀疏计算技术,实现了高性能和低成本的平衡。
4、精细的视觉-语言数据构建流程
- 三阶段训练流程:继承了DeepSeek-VL的三阶段训练方法,确保模型在不同阶段逐步提升性能。
- 负载均衡:针对图像切片数量不定的问题,引入了负载均衡机制,确保训练过程中的稳定性和高效性。
- 不同流水并行策略:对图像和文本数据使用不同的流水并行策略,进一步优化了训练效率。
- 专家并行:对MoE语言模型引入了专家并行,实现了高效的分布式训练。
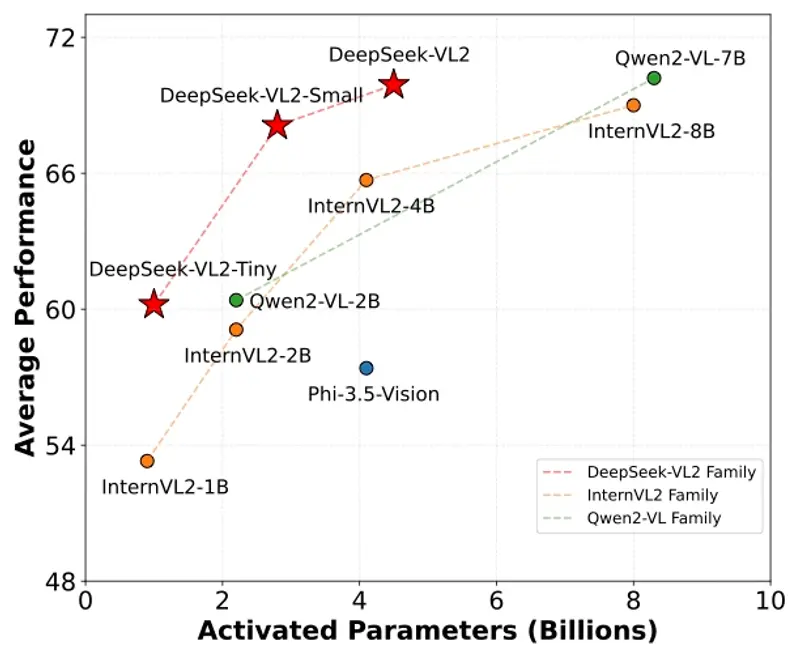
核心模块
1、视觉编码器
- 切图策略:将输入图像分割成多个子图和一张全局缩略图,通过共享的视觉变换器(Vision Transformer)处理每个子图,并整合提取的特征。
- 动态分辨率支持:通过切图策略,模型可以处理任意分辨率的图像,最高支持1152x1152的分辨率和极端长宽比。
2、视觉-语言适配器
- 特征压缩:将视觉编码器提取的特征压缩并映射到语言模型的嵌入空间,确保视觉信息能够有效地融入语言理解过程中。
- 跨模态融合:通过适配器模块,视觉和语言信息得以无缝融合,增强了模型的多模态理解能力。
3、专家混合语言模型(DeepSeekMoE LLM)
- 多头潜在注意力机制:采用多头潜在注意力机制,增强了模型对复杂语义结构的理解能力。
- 稀疏计算:通过稀疏计算技术,减少了不必要的计算开销,提升了推理效率。
- 大规模参数:DeepSeek-VL2 系列包含三种变体,分别拥有1.0B、2.8B和4.5B激活参数,以适应不同的计算资源和应用场景。
性能与优势
- 竞争力强:与现有的开源密集型和基于MoE的模型相比,DeepSeek-VL2 在相似或更少的激活参数下实现了具有竞争力的或最先进的性能。
- 高效训练:通过负载均衡、不同流水并行策略和专家并行等技术,DeepSeek-VL2 实现了高效的训练过程,缩短了开发周期。
- 广泛适用性:DeepSeek-VL2 不仅适用于传统的视觉问答和OCR任务,还能处理更复杂的科研图表理解和视觉定位等任务,适配更多应用场景。
- 灵活性:提供三种不同规模的模型变体,用户可以根据实际需求选择最适合的版本,平衡性能和计算资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...