
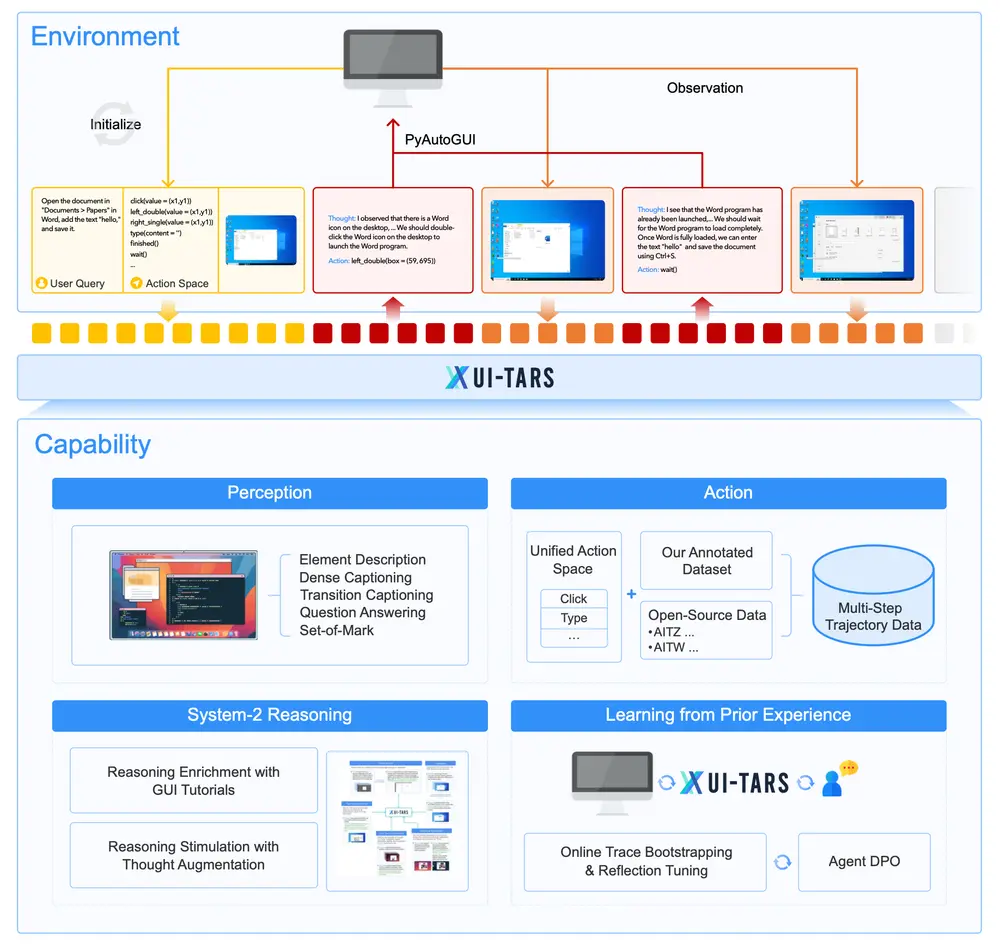
字节跳动与清华大学的研究人员推出新型自动化 GUI(图形用户界面)交互模型 UI-TARS,它是一种原生的 GUI 代理模型,能够通过感知屏幕截图作为输入,并执行类似人类操作的交互任务(如键盘输入和鼠标操作)。与依赖于商业模型(如 GPT-4o)和专家手工设计的提示和工作流的现有代理框架不同,UI-TARS 是一个端到端的模型,能够直接从屏幕截图中理解和执行任务,无需依赖于文本描述或系统级权限。
例如,在一个任务中,用户要求代理在网页浏览器中找到并点击一个特定的按钮。传统方法可能需要通过 HTML 代码或其他文本描述来定位按钮,而 UI-TARS 只需通过屏幕截图直接识别按钮的位置并执行点击操作,就像人类用户一样。
主要功能
- 增强的感知能力:UI-TARS 能够通过大规模 GUI 截图数据集来理解 UI 元素,并生成精确的描述和字幕。
- 统一的动作建模:将不同平台上的动作标准化,通过大规模动作轨迹数据实现精确的交互。
- 系统 2 推理:引入深思熟虑的推理能力,支持多步决策,包括任务分解、反思思考和里程碑识别等。
- 迭代训练与在线学习:通过自动收集、过滤和优化新的交互轨迹,UI-TARS 能够从错误中学习,并适应未预见的情况,几乎不需要人工干预。
主要特点
- 纯视觉输入:完全依赖屏幕截图,无需文本描述或系统级权限。
- 端到端设计:将感知、推理、记忆和动作执行集成到一个统一的模型中,无需模块化的工作流。
- 自适应能力:通过在线学习和迭代优化,能够适应新任务和环境变化。
- 数据驱动:通过大规模数据训练,能够不断学习和改进,减少对人工标注的依赖。
工作原理
UI-TARS支持桌面、移动及网页应用的操作,利用多模态输入(如文本、图像、交互)来理解视觉环境。其用户界面包含两个标签页:左侧显示逐步的“思考过程”,右侧展示打开的文件、网站和应用程序,并自动执行相应的操作。
UI-TARS 的工作原理可以分为以下几个关键步骤:
- 感知:模型通过屏幕截图输入,识别和理解 GUI 元素及其布局。
- 推理:在执行动作之前,模型会生成“思考”步骤,模拟人类的深思熟虑过程。
- 动作执行:根据推理结果,模型选择并执行相应的动作(如点击、输入文本等)。
- 在线学习:通过在虚拟机上执行任务并收集新的交互轨迹,模型不断优化自身性能。
- 错误纠正:通过标注错误和纠正行为,模型学会从错误中恢复,提高鲁棒性。
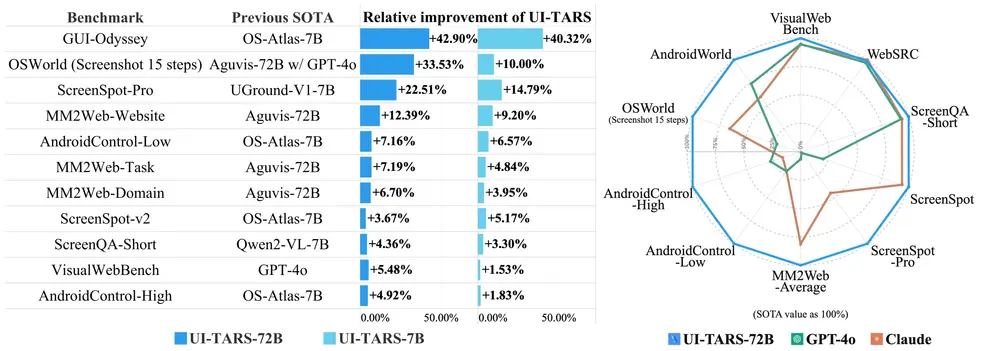
性能超越竞争对手
在多个基准测试中,UI-TARS的表现均优于其他模型,比如在VisualWebBench上得分82.8%,高于GPT-4o的78.5%和Claude 3.5的78.2%。此外,在WebSRC和ScreenQA-short等测试中,UI-TARS同样表现出色。研究人员还强调了UI-TARS在处理复杂GUI元素理解和定位方面的卓越能力,这为高效的任务执行奠定了坚实的基础。
具体应用场景
- 自动化办公任务:例如在 Word 中插入表格、在 Excel 中进行数据处理或在 PowerPoint 中调整幻灯片布局。
- 移动设备自动化:在 Android 或 iOS 设备上执行复杂的多步操作,如安装应用、设置系统参数等。
- 网页自动化:在浏览器中自动完成表单填写、网页导航或数据抓取任务。
- 跨平台任务:在桌面操作系统(如 Windows、macOS)和移动操作系统之间无缝切换,执行统一的任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











