Hugging Face团队最近发布了两款名为SmolVLM-256M和SmolVLM-500M的新模型,它们被宣称为能够分析图像、短视频以及文本的最小AI模型。这两款模型特别设计用于在资源受限的设备上运行,比如内存不足1GB的笔记本电脑,并且非常适合那些寻求以极低成本处理大量数据的开发者。
- 模型:https://huggingface.co/collections/HuggingFaceTB/smolvlm-256m-and-500m-6791fafc5bb0ab8acc960fb0
- Demo:SmolVLM-256M和SmolVLM-500M
模型参数与能力
- SmolVLM-256M 和 SmolVLM-500M 分别拥有2.56亿和5亿个参数,这些参数大致反映了模型解决问题的能力。
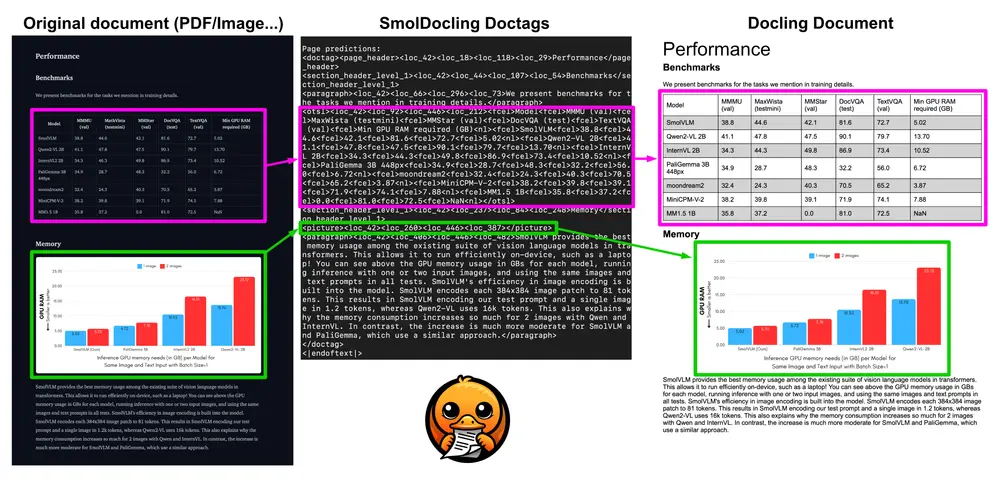
- 这些模型可以执行多种任务,包括描述图像或视频片段,回答有关PDF及其内容(包括扫描文本和图表)的问题等。
训练数据集
为了训练这两个模型,Hugging Face团队使用了两个专门创建的数据集:
- The Cauldron:包含50个高质量的图像和文本数据集。
- Docmatix:一组文件扫描及其详细描述。 这两个数据集均由Hugging Face的M4团队开发,该团队专注于多模态AI技术的研究和发展。
性能表现
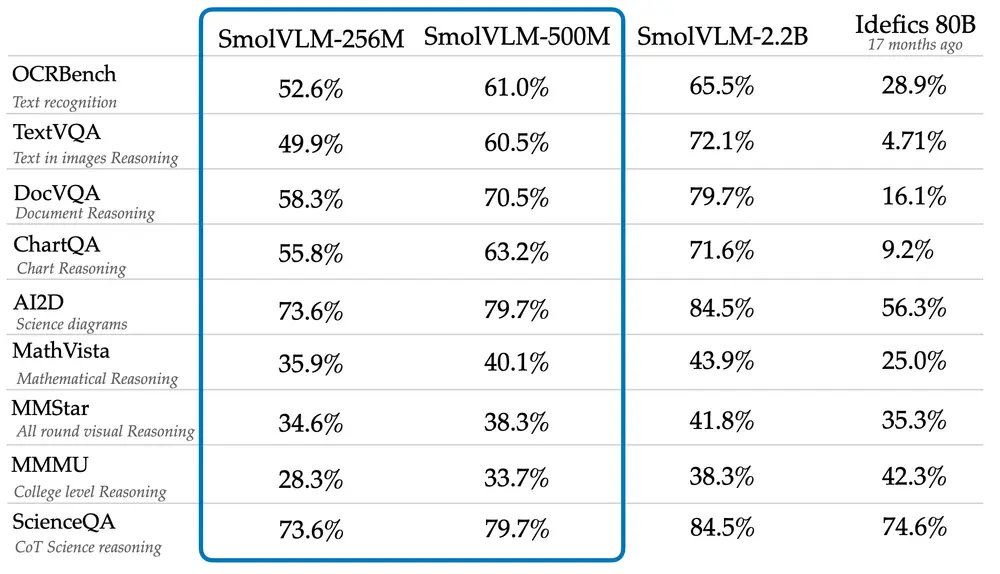
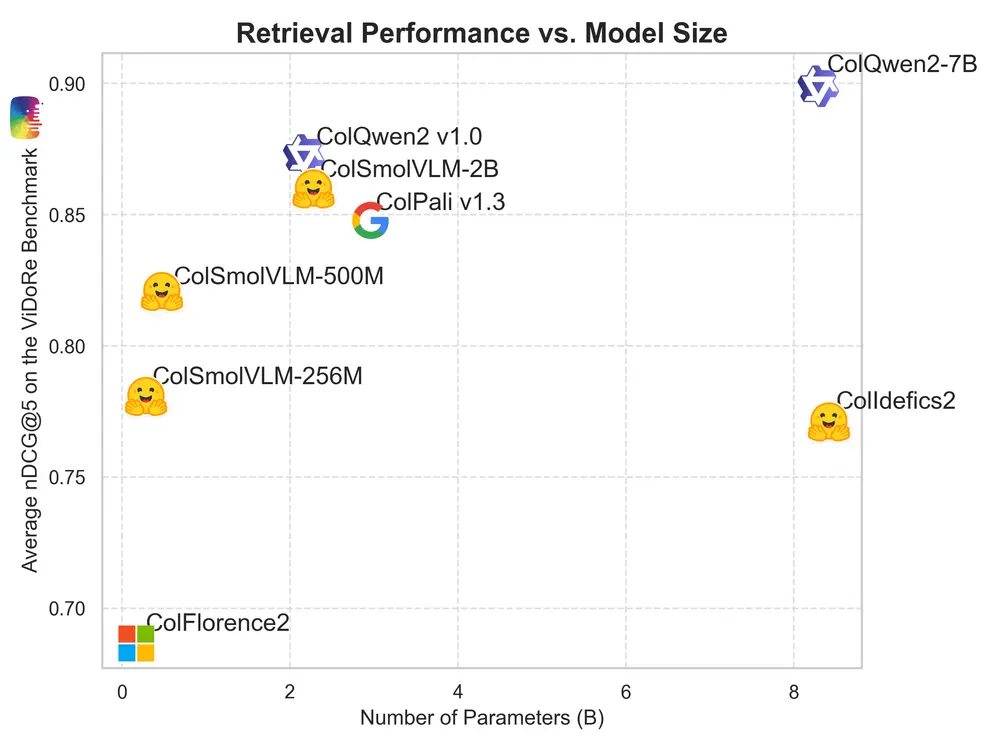
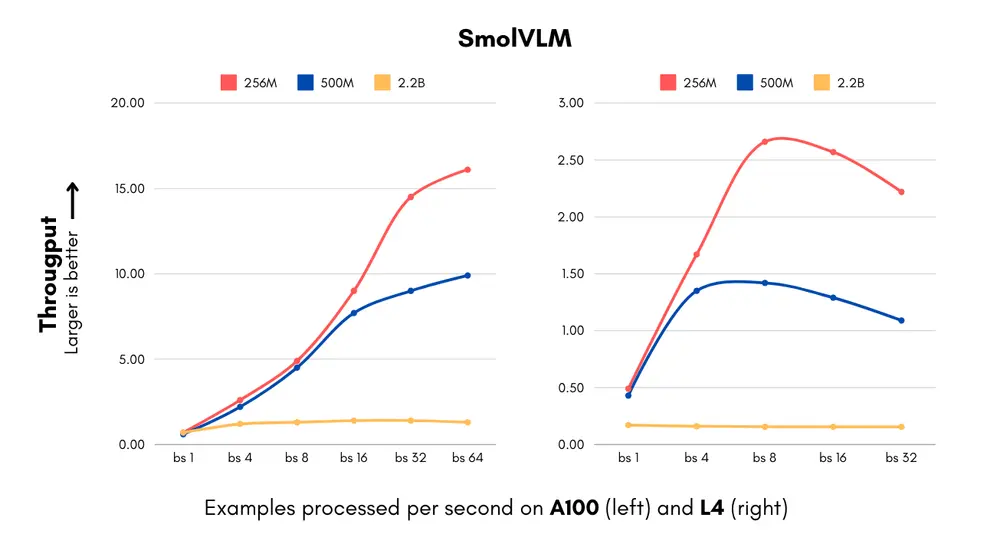
尽管规模较小,但SmolVLM-256M和SmolVLM-500M在多个基准测试中表现出色,尤其是在AI2D测试中,评估了模型分析小学科学图表的能力,它们的表现甚至超过了更大的Idefics 80B模型。这表明即使在资源有限的情况下,小型模型也能提供强大的性能。
使用与许可
这两个模型可通过Hugging Face网站获取,并采用Apache 2.0许可证,这意味着用户可以自由地使用这些模型而无需担心版权问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











