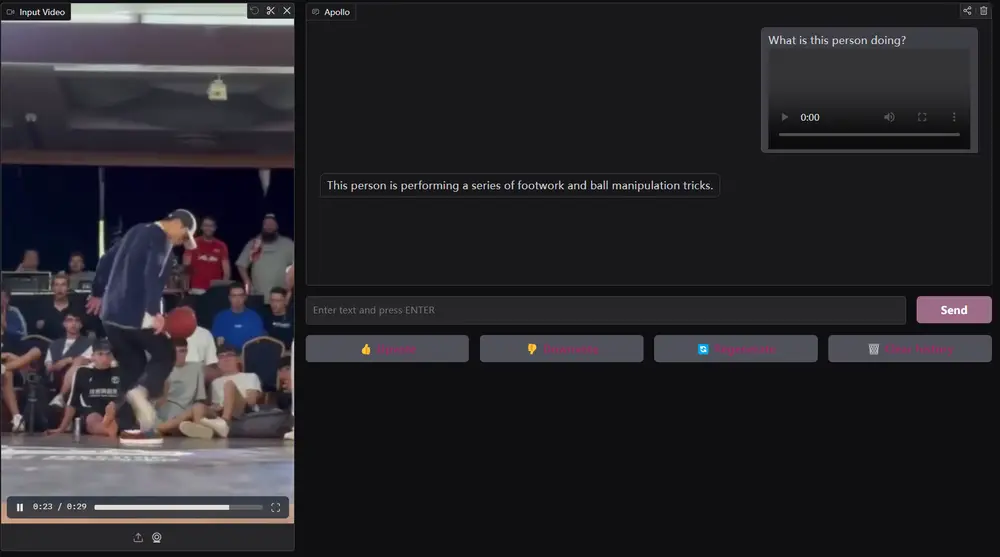
随着DeepSeek R1的发布,强化学习在大模型领域的潜力得到了进一步挖掘。Reinforcement Learning with Verifiable Reward(RLVR)方法为多模态任务提供了全新的优化思路,在几何推理、视觉计数、图像分类和物体检测等任务中展现了显著优于传统监督微调(SFT)的效果。

然而,现有研究大多集中在Image-Text多模态任务上,尚未涉足更复杂的全模态场景。基于此背景,通义实验室团队探索了RLVR与视频全模态模型的结合,并于近日宣布开源R1-Omni模型。
R1-Omni亮点
R1-Omni的一大亮点在于其透明性,即增强的推理能力。通过RLVR方法,音频信息和视频信息在模型中的作用变得更加清晰可见。例如,在情绪识别任务中,R1-Omni能够明确展示哪些模态信息对特定情绪判断起到了关键作用。
研究揭示了以下关键见解:
- 增强的推理能力:R1-Omni 展示了卓越的推理能力,让人们能够更清晰地理解视觉和音频信息如何共同作用于情感识别。
- 提升的理解能力:与 SFT 相比,RLVR 在情感识别任务上的表现显著提高。
- 更强的泛化能力:RLVR 模型在分布外场景中表现出色,显示出明显更好的泛化能力。
工作原理
冷启动阶段
使用 Explainable Multimodal Emotion Reasoning (EMER) 数据集和手动标注的 HumanOmni 数据集初始化模型,使其具备初步的情感推理能力。EMER 数据集包含详细的推理标注,帮助模型学习如何结合视觉和音频信息进行情感识别。
强化学习优化
- 奖励函数设计:奖励函数分为两部分——准确性奖励(Racc)和格式奖励(Rformat)。准确性奖励评估情感预测是否正确,格式奖励确保输出符合预定义的结构。
- GRPO 优化:通过生成多个候选响应并比较它们的奖励值,模型学习优先选择高奖励的响应,从而提升推理能力和输出质量。
多模态输入处理
模型接收视频帧和音频流作为输入,生成带有推理过程的候选响应。推理过程详细解释视觉和音频信息如何共同影响情感识别。
例如,有一个视频片段,其中一个人在说话,表情愤怒,声音高亢且急促。传统的情感识别模型可能只能识别出愤怒的情绪,但无法解释其推理过程。而 R1-Omni 不仅能准确识别出愤怒情绪,还能详细解释其推理过程:“视频中人物的表情愤怒,眼神锐利,声音高亢且急促,这些视觉和音频线索共同表明人物处于愤怒状态。”
实验验证
为了验证 R1-Omni 的性能,通义实验室团队将其与原始的 HumanOmni-0.5B 模型、冷启动阶段的模型以及在 MAFW 和 DFEW 数据集上有监督微调的模型进行了对比。
实验结果显示:
- 在同分布测试集(DFEW 和 MAFW)上,R1-Omni 相较于原始基线模型平均提升超过 35%,相较于 SFT 模型在 UAR 上的提升高达 10% 以上。
- 在不同分布测试集(RAVDESS)上,R1-Omni 同样展现了卓越的泛化能力,WAR 和 UAR 均提升超过 13%。
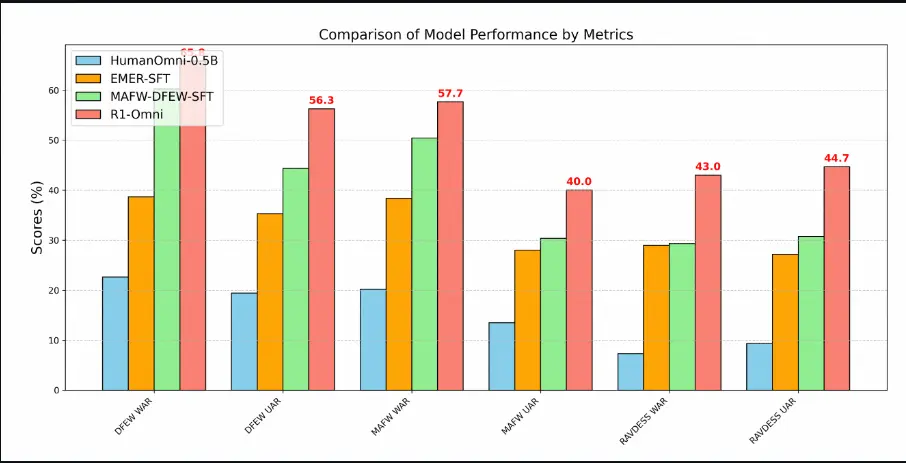
这些结果充分证明了 RLVR 在提升推理能力和泛化性能上的显著优势。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











