
加州大学默塞德分校、字节跳动、武汉大学和北京大学的研究人员推出新型多模态大语言模型Sa2VA,它将SAM-2视频分割模型与LLaVA视觉-语言模型相结合,实现了对图像和视频的密集、基于语义的理解。Sa2VA能够处理包括图像和视频的指代表达式分割(referring segmentation)、图像和视频对话(image/video chat)等多种任务,且仅需单次指令调优(one-shot instruction tuning)即可完成任务切换。例如,Sa2VA能够根据用户提供的语言描述,如“请分割出穿着蓝色连衣裙跳舞的金发女孩”,在视频中准确识别并分割出目标对象,同时还能与用户进行关于视频内容的对话,如回答“视频中的天气如何?”等问题。
- 项目主页:https://lxtgh.github.io/project/sa2va
- GitHub:https://github.com/magic-research/Sa2VA
- 模型:https://huggingface.co/ByteDance/Sa2VA
- Demo:https://huggingface.co/spaces/fffiloni/Sa2VA-simple-demo

主要功能
- 指代表达式分割:Sa2VA能够根据语言描述,在图像或视频中精确分割出所指对象。例如,在视频中,根据描述“请分割出穿着黑色夹克的男子”,Sa2VA能够识别并分割出视频中符合该描述的男子。
- 图像和视频对话:Sa2VA能够理解并回答有关图像或视频内容的问题,如“图中的动物是什么?”或“视频中的人在做什么?”,实现与用户的自然语言交互。
- 基于语义的字幕生成:Sa2VA能够根据图像或视频内容生成描述性的字幕,如为一张展示滑雪者在雪山上跳跃的照片生成字幕“滑雪者在雪山上进行高难度跳跃”。
主要特点
- 统一的多模态理解框架:Sa2VA将文本、图像和视频统一在一个共享的LLM(大型语言模型)标记空间内,使得模型能够跨模态地理解和处理信息。
- 高效的单次指令调优:Sa2VA只需一次指令调优即可适应多种任务,无需针对每个任务进行复杂的模型调整或训练,大大提高了模型的灵活性和实用性。
- 强大的分割和对话能力:Sa2VA在指代表达式分割任务上取得了优异性能,同时在图像和视频对话任务上也表现出色,能够准确理解并回应用户的提问。
工作原理
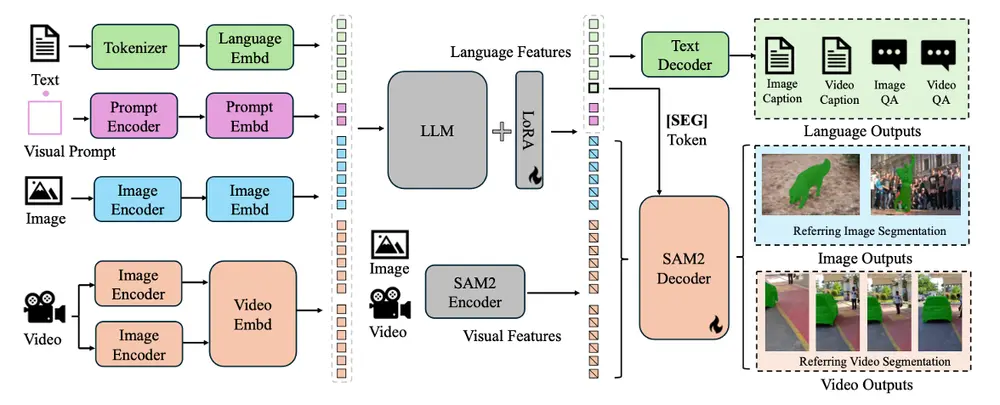
Sa2VA的工作原理主要基于以下几个关键组件和步骤:
- 输入编码:将输入的文本、图像和视频编码成LLM能够处理的标记(tokens)。文本通过分词器转换成文本标记,图像和视频则通过视觉编码器转换成视觉标记。
- LLM处理:将编码后的文本和视觉标记输入到LLM中进行处理。LLM利用其强大的语言理解和生成能力,根据输入的指令和视觉信息生成相应的输出,如分割掩码、对话回答或字幕文本。
- 分割掩码生成:对于指代表达式分割任务,LLM会生成一个特殊的[SEG]标记,该标记的隐藏状态被用作提示输入到SAM-2的解码器中,解码器根据提示生成对应的分割掩码,实现对目标对象的精确分割。
- 输出解码:将LLM生成的输出标记解码成最终的输出结果,如文本回答、分割掩码或字幕文本等。
具体应用场景
- 视频编辑与创作:Sa2VA可以帮助视频编辑者根据语言描述快速定位和分割视频中的特定对象,从而进行更精准的视频剪辑和特效添加,提高视频创作的效率和质量。
- 智能监控与分析:在监控视频分析中,Sa2VA能够根据监控目标的描述实时识别和跟踪目标对象,为安全监控提供更智能的分析手段,如在复杂场景中快速定位可疑人员或事件。
- 虚拟助手与交互:Sa2VA可以集成到虚拟助手系统中,使虚拟助手能够理解用户关于图像和视频内容的提问,并给出准确的回答,提升用户的交互体验,如在智能家居场景中,用户可以通过语音指令让虚拟助手识别并控制视频中的特定设备或对象。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











