
百川智能宣布其最新研发的Baichuan-Omni-1.5开源全模态模型正式上线。这款模型支持文本、图像、音频和视频等多种格式的数据处理,并具备文本与音频的双模态生成能力。Baichuan-Omni-1.5 是从 Baichuan-omni 升级的最新的、端到端训练的、支持全模态输入/双模态输出的多模态大模型。该模型使用Qwen2.5-7B作为大语言模型基座,可以端到端方式,接受图像、视频、文本、音频作为输入,并且以可控的方式生成高质量文本和语音。
Baichuan-Omni-1.5-Base: 为促进全模态大模型发展,我们开源了使用高质量海量数据训练的全模态基座模型。该模型未经SFT指令微调,可塑性强,是目前性能最好的全模态基座模型。
Baichuan-Omni-1.5: 基于性能强悍的Baichuan-Omni-1.5-base,使用高质量的全模态对齐数据,进行端到端的多模态指令数据训练。Baichuan-Omni-1.5的纯文本、图像、视频、音频理解能力达到了 GPT-4o-mini 级别。
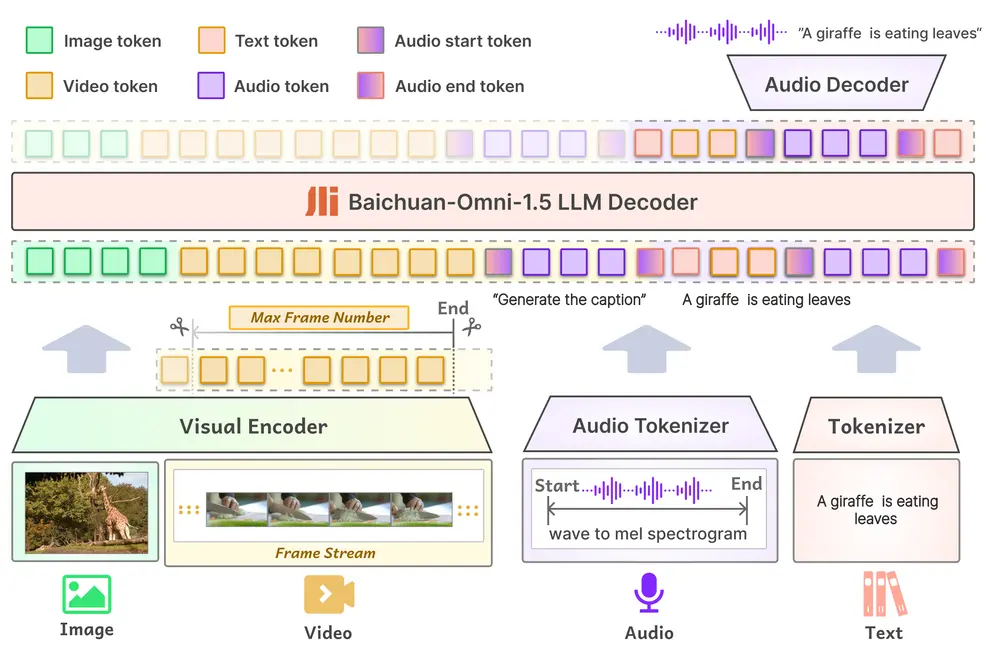
性能优势
官方表示,Baichuan-Omni-1.5在视觉、语音及多模态流式处理等方面均表现出色,超越了GPT-4o mini。特别是在医疗领域的多模态应用中,Baichuan-Omni-1.5展现了更加显著的优势。
模型:
Baichuan-Omni-1.5:
Baichuan-Omni-1.5-Base:
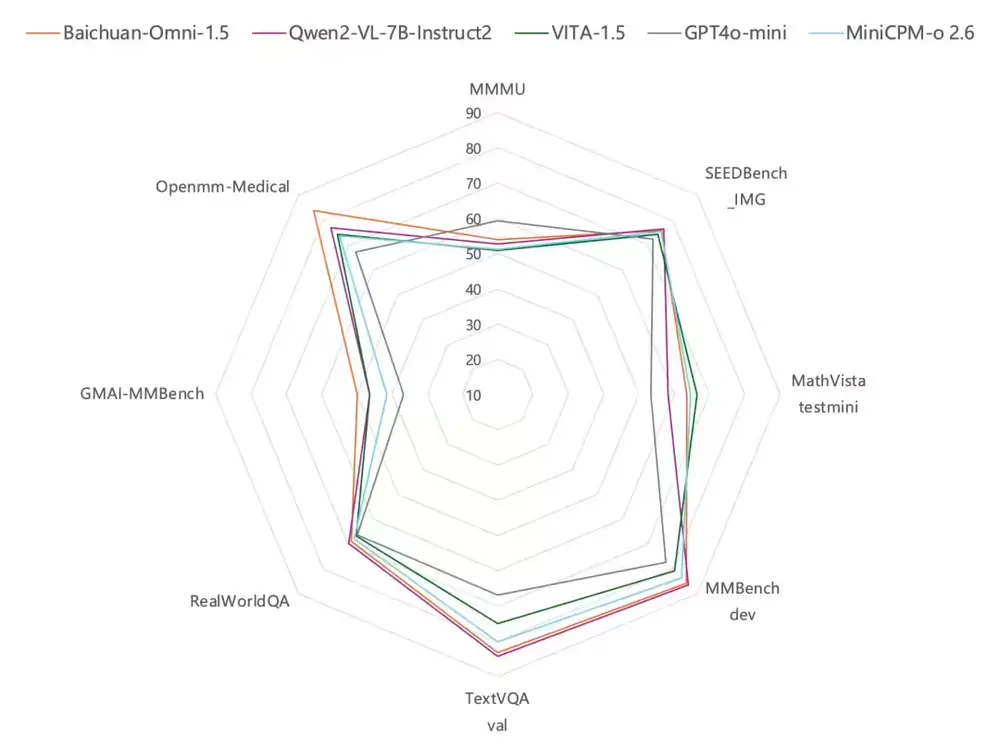
功能亮点
该模型不仅支持多种交互操作,还拥有强大的多模态推理能力和跨模态迁移能力。在音频技术领域,Baichuan-Omni-1.5采用端到端解决方案,支持多语言对话、音频合成、自动语音识别以及文本转语音等功能,并且能够实现音视频实时交互。
在视频理解方面,通过优化编码器、训练数据和方法等关键环节,Baichuan-Omni-1.5的整体性能远超GPT-4o-mini。
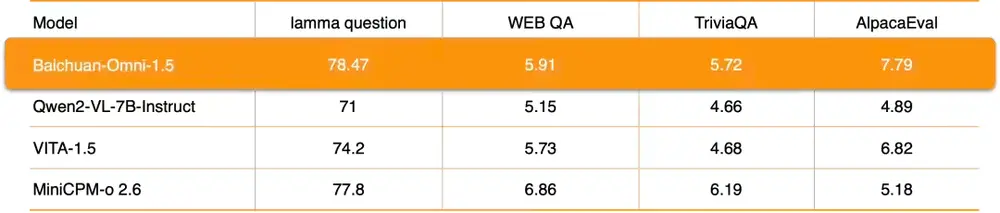
模型结构
Baichuan-Omni-1.5的设计考虑到了输入和输出的多样化需求。输入部分兼容各种模态的数据,通过相应的Encoder/Tokenizer接入大型语言模型;输出部分则创新性地采用了文本-音频交错输出的方式,通过Text Tokenizer和Audio Decoder同时生成文本和音频内容。
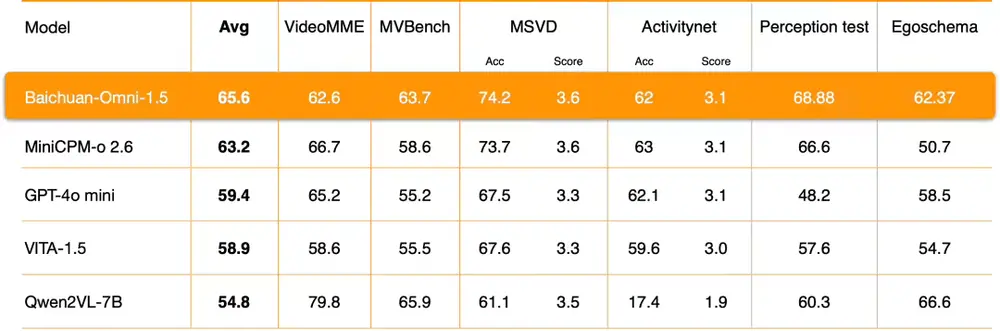
数据支持
为了保证模型的高效运行,百川智能构建了一个庞大的数据库,包含3.4亿条高质量图片/视频-文本数据和近100万小时的音频数据。此外,在监督微调(SFT)阶段使用了1700万条全模态数据,进一步提升了模型的性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











