
深度求索(DeepSeek-AI)在DeepSeek-R1爆火后,又在今天释出了多模态理解与生成模型 Janus-Pro,它是之前工作 Janus 的升级版本,目前释出了两个版本Janus-Pro-7B和Janus-Pro-1B。Janus-Pro 在多模态理解(如图像问答、场景理解等)和文本到图像生成(根据文本描述生成图像)方面表现出色,通过优化训练策略、扩展训练数据和扩大模型规模,实现了显著的性能提升。
- Janus-Pro-7B:https://huggingface.co/deepseek-ai/Janus-Pro-7B
- Janus-Pro-1B:https://huggingface.co/deepseek-ai/Janus-Pro-1B
- Demo:https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
- 第三方Demo:https://huggingface.co/spaces/AP123/Janus-Pro-7b
- ComfyUI节点:https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro
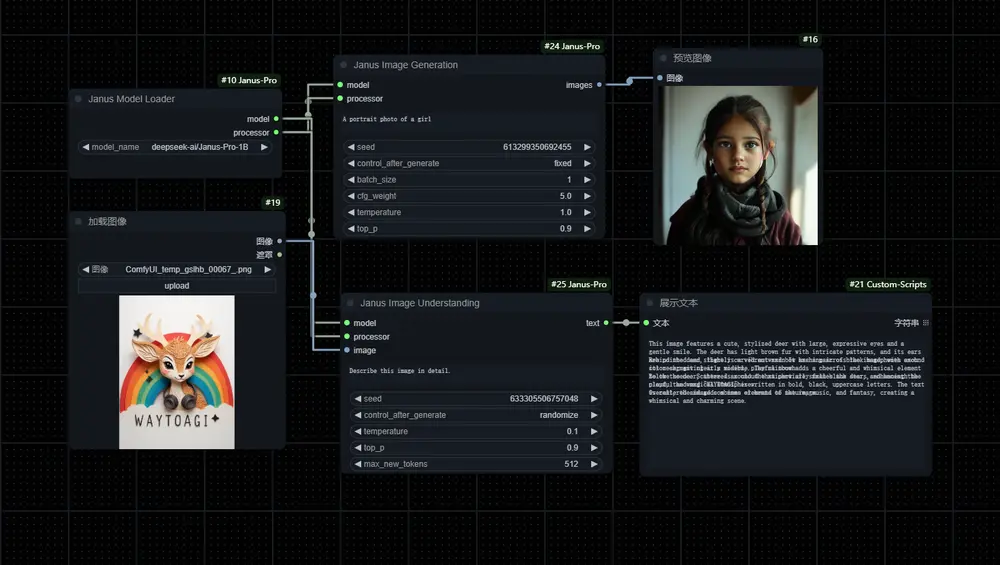
Janus-Pro 是一个专注于多模态任务的深度学习模型,旨在同时处理多模态理解(如图像分类、视觉问答等)和多模态生成(如文本到图像生成)任务。例如,它可以理解一张图片的内容并回答相关问题,也可以根据一段文字描述生成对应的图像。与传统的单一任务模型不同,Janus-Pro 通过解耦视觉编码器,将多模态理解与生成任务分开处理,从而在两个任务上都取得了优异的性能。
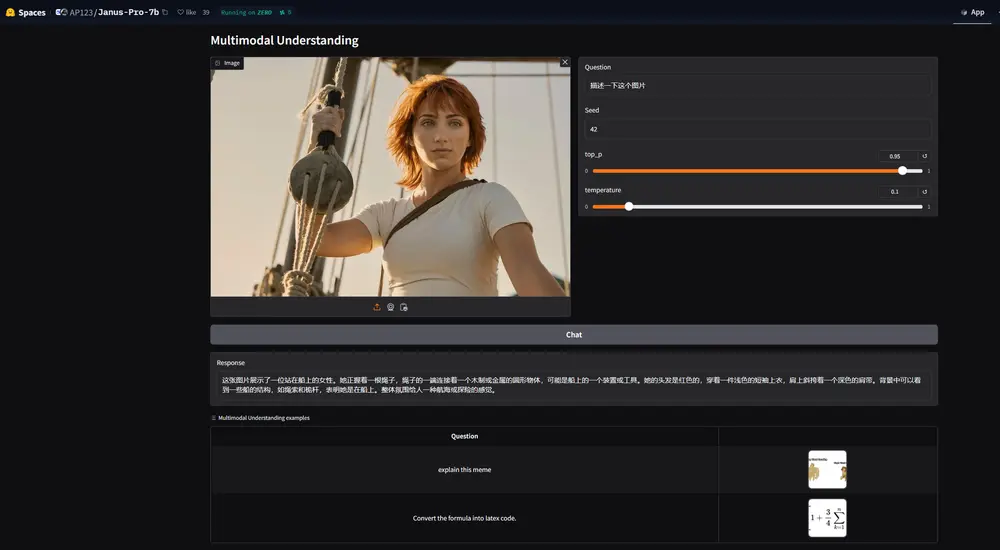
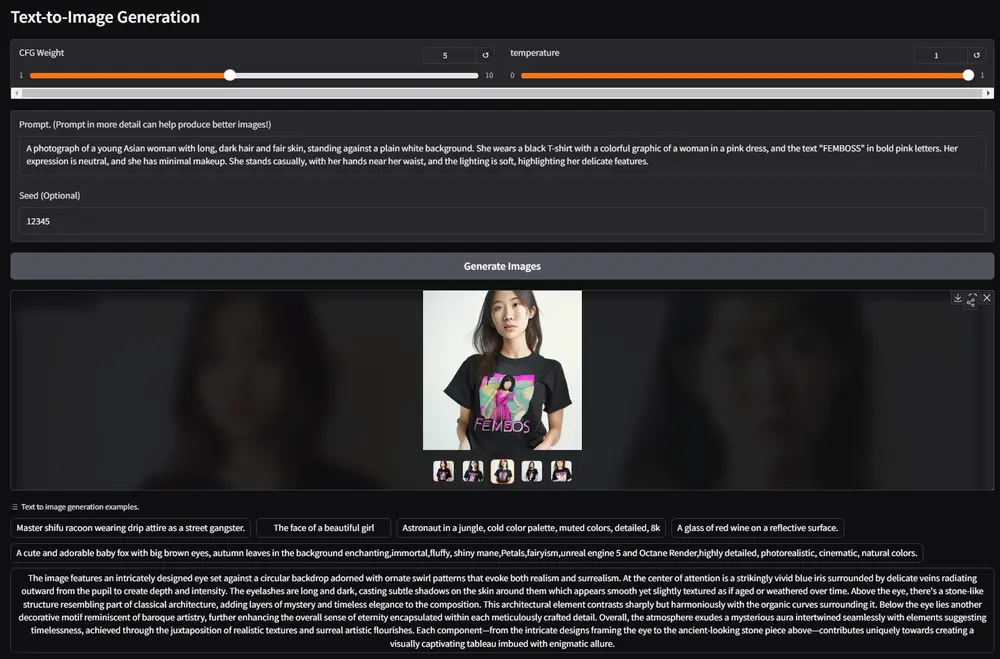
主要功能
- 多模态理解:能够理解图像、视频等视觉内容,并结合文本信息进行问答、分类等任务。例如,它可以识别图像中的物体、场景,并回答与图像内容相关的问题。
- 文本到图像生成:根据文本描述生成高质量的图像。例如,输入“一只在草地上奔跑的金色猎犬”,模型可以生成对应的图像。
- 多模态对话:结合视觉和语言信息进行对话,例如描述图像内容或根据图像回答问题。
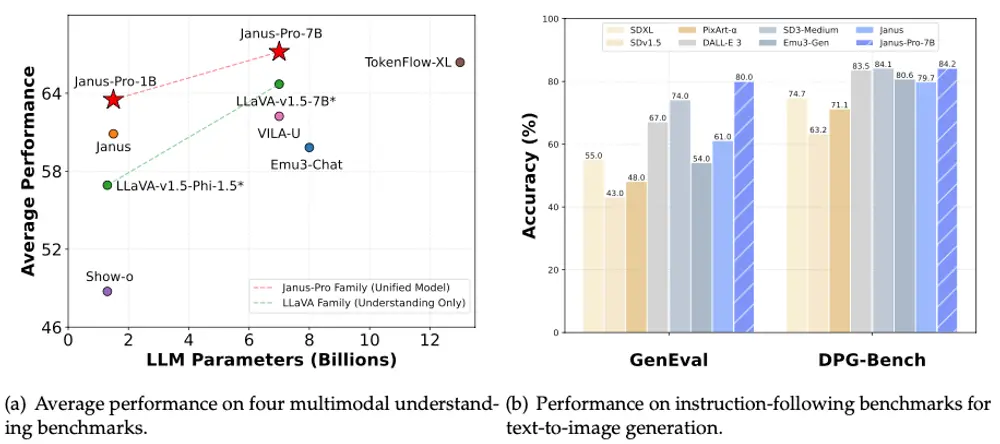
主要特点
- 解耦视觉编码器:为多模态理解和生成任务分别设计了独立的视觉编码器,避免了两者之间的冲突,提高了性能。
- 大规模训练数据:使用了大量高质量的多模态数据进行训练,包括图像、文本对齐数据和合成数据。
- 优化的训练策略:通过调整训练阶段的策略,提高了模型的训练效率和稳定性。
- 可扩展性:支持不同规模的模型(如 1B 和 7B 参数规模),验证了该方法的可扩展性。
工作原理
Janus-Pro 的架构基于解耦的视觉编码器和统一的自回归变换器(Transformer)。具体工作原理如下:
- 视觉编码:对于多模态理解任务,使用 SigLIP 编码器提取图像的语义特征;对于生成任务,使用 VQ tokenizer 将图像转换为离散 ID 序列。
- 特征融合:将视觉特征和文本特征融合后输入到自回归 Transformer 中进行处理。
- 自回归生成:模型通过自回归的方式逐步生成输出,无论是理解任务的答案还是生成任务的图像。
- 优化训练:通过多阶段训练策略,分别对不同组件进行训练,并在不同阶段调整数据比例和训练步骤。

具体应用场景
- 内容创作:根据文本描述生成高质量的图像或视频,用于广告、游戏、影视等创意产业。
- 智能助手:结合视觉和语言理解能力,为用户提供更智能的交互体验,例如通过图像识别回答问题或提供建议。
- 教育与培训:生成与教学内容相关的图像或动画,帮助学生更好地理解和记忆知识。
- 医疗与健康:辅助医生进行医学图像分析,生成医学图像用于教学或研究。
- 智能客服:通过理解用户上传的图片或视频内容,提供更精准的客服支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











