多模态AI模型是能够理解和生成视觉内容的强大工具。然而,现有方法通常使用单一视觉编码器来处理这两项任务,这导致了由于理解和生成在本质上不同的需求而表现不佳。理解需要高层次的语义抽象,而生成则关注局部细节和全局一致性。这种不匹配导致冲突,限制了模型的整体效率和准确性。
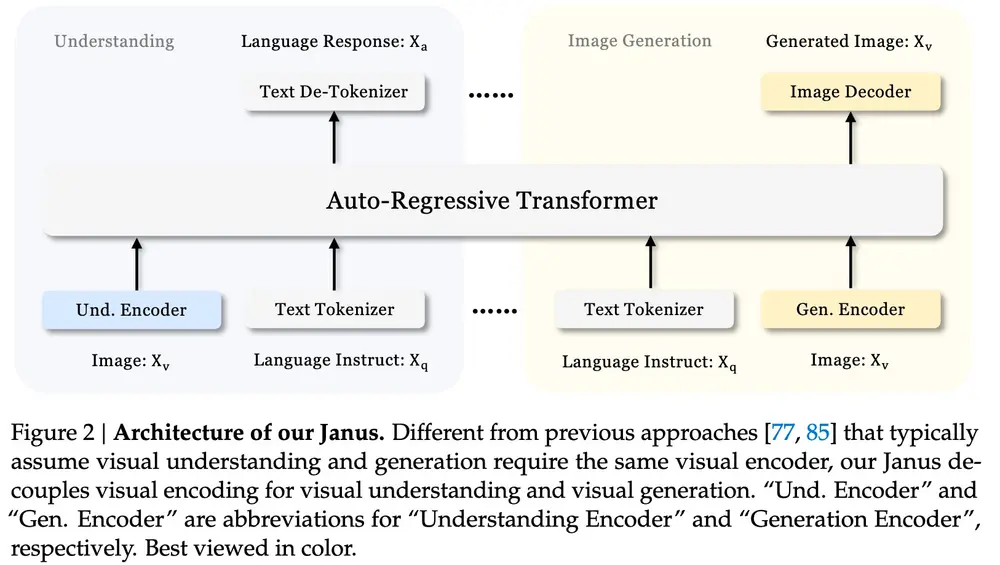
为了解决这些问题,来自深度求索(DeepSeek-AI)、香港大学和北京大学的研究人员提出了Janus,这是一种新颖的自回归框架,用于理解和生成多模态内容,比如图像和文字。通过采用两个不同的视觉编码路径来统一多模态理解和生成。这种设计有效地缓解了先前模型中固有的冲突,并提供了增强的灵活性,使得不同的编码方法最适合每种模态。“Janus”这个名字恰当地代表了这种二重性,就像罗马神一样,有两张脸代表过渡和共存。例如,你给Janus一个描述,比如“一只穿着宇航服的勇敢小狗在探索一个布满星尘和流星的外星球”,它就能根据这个描述生成一张图片。或者,你给它一张图片,它就能解释图片的内容,告诉你图片上有什么,发生了什么故事。

Janus的架构
Janus通过使用两个不同的编码器来处理图像,这两个编码器分别针对理解和生成任务进行了优化。对于理解任务,它使用一个能够提取图像高层语义信息的编码器;而对于生成任务,它使用一个能够保持图像细节和全局一致性的编码器。这样,Janus就能够在不同的任务中使用最适合的编码方法,而不会因为一个编码器要同时满足两种需求而产生冲突。
- 理解编码器SigLIP:Janus使用高维语义特征提取方法SigLIP,将视觉特征转换为与语言模型兼容的序列。这种方法能够捕获高层次的语义信息,适用于多模态理解任务。
- 生成编码器VQ tokenizer:Janus使用VQ tokenizer将视觉数据转换为离散表示,从而实现详细的图像合成。这种方法能够捕捉局部细节和全局一致性,适用于视觉生成任务。
这两个任务都由共享的Transformer处理,使模型能够以自回归方式运行。这种方法允许模型解耦每个视觉任务的要求,简化了实现并提高了可扩展性。
训练过程
Janus的训练分为三个阶段,每个阶段都增强了其多模态能力,同时保持了不同任务之间的一致性:
- 训练适配器:在这个阶段,模型学习如何将不同的视觉编码路径与语言模型对齐。
- 统一预训练:模型在大规模多模态数据集上进行预训练,以学习通用的多模态表示。
- 有监督的微调:模型在特定任务的数据集上进行微调,以优化其在特定任务上的性能。
实验结果
实验结果表明,Janus在各种基准测试中显著优于先前的模型。具体表现如下:
- 多模态理解:
- MMBench:Janus获得了69.4的分数,超过了LLaVA-v1.5和其他统一模型。
- SEED-Bench:Janus获得了63.7的分数,同样超过了其他模型。
- POPE:Janus获得了87.0的分数,甚至在某些情况下匹配或超过了特定任务的模型。
- 视觉生成:
- MSCOCO-30K:Janus实现了8.53的Fréchet Inception Distance(FID),展示了比DALL-E 2和SDXL等竞争模型更好的用户提示一致性。
这些结果表明,Janus在理解和生成视觉内容方面提供了平衡的能力,同时更具参数效率。
结论
Janus通过解决理解和生成之间的冲突,在开发统一的多模态AI模型方面迈出了重要一步。其解耦方法被证明既有效又高效,能够在高质量语义理解的同时进行详细的视觉生成。这种灵活性使Janus成为未来多模态AI发展的有希望的候选者,潜在应用扩展到其他模态,如点云或音频数据。Janus的可扩展性、灵活性和稳健性能突显了其作为下一代统一多模态模型的灵感潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











