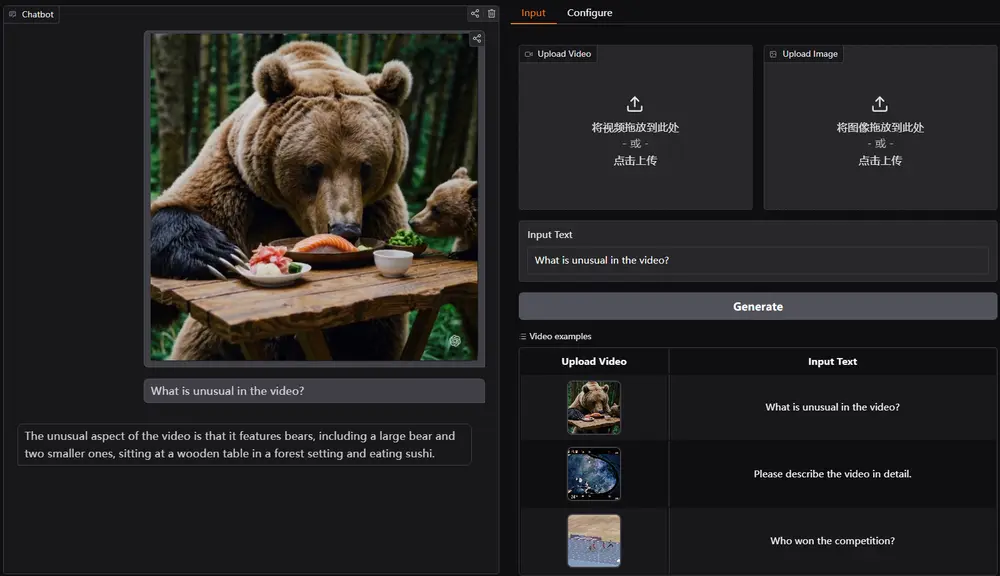
新型多模态基础模型VideoLLaMA 3:提升图像和视频理解的性能阿里巴巴达摩院的研究人员推出新型多模态基础模型VideoLLaMA 3,旨在提升图像和视频理解的性能。该模型的核心设计理念是“以视觉为中心”(vision-centric),通过高质量的图像-文本数据...多模态模型# VideoLLaMA 31年前05280