
阿里巴巴达摩院的研究人员推出新型多模态基础模型VideoLLaMA 3,旨在提升图像和视频理解的性能。该模型的核心设计理念是“以视觉为中心”(vision-centric),通过高质量的图像-文本数据训练,增强模型对静态图像和动态视频的理解能力。
- GitHub:https://github.com/DAMO-NLP-SG/VideoLLaMA3
- 模型:https://huggingface.co/collections/DAMO-NLP-SG/videollama3-678cdda9281a0e32fe79af15
- Demo:视频/图片
例如,我们有一张包含复杂图表的图像和一段描述该图表内容的文本。传统的多模态模型可能在理解图表中的数据和逻辑关系时表现不佳。然而,VideoLLaMA 3 能够准确解析图表中的数据点、趋势和逻辑关系,并生成详细的描述或回答相关问题。同样,对于视频内容,该模型能够理解视频中的动态变化、人物行为和场景转换,生成准确的字幕或回答视频相关的问题。
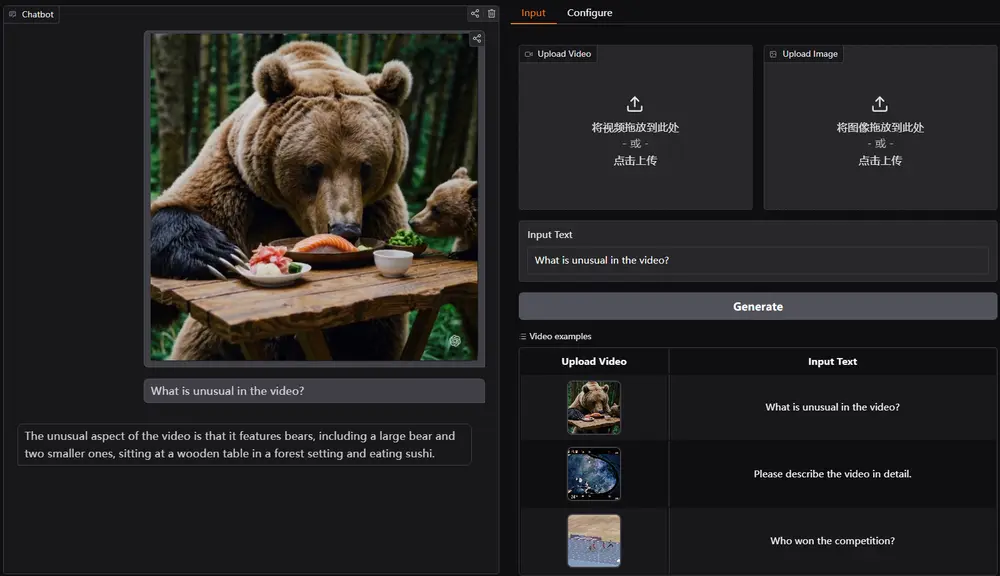
主要功能
- 图像理解:能够理解各种类型的图像,包括场景图像、文档、图表和场景文本图像。
- 视频理解:能够处理和理解视频内容,包括动态场景、人物行为和时间序列信息。
- 多模态任务:支持多种多模态任务,如视觉问答(VQA)、文档理解、数学推理和多图像理解。
- 灵活输入:支持动态分辨率的图像和视频输入,能够处理不同分辨率和宽高比的视觉数据。
- 高效视频处理:通过视频压缩技术,减少视频数据的冗余,提高处理效率。
主要特点
- 以视觉为中心的训练范式:通过大规模高质量的图像-文本数据进行预训练,增强模型对视觉内容的理解能力。
- 动态分辨率适应:模型能够处理不同分辨率的图像和视频输入,通过替换绝对位置嵌入为旋转位置嵌入(RoPE),实现灵活的输入处理。
- 视频压缩技术:通过差分帧剪枝(Differential Frame Pruner, DiffFP)技术,减少视频帧之间的冗余信息,提高视频处理效率。
- 多任务微调:在多个下游任务上进行微调,包括图像问答、视频字幕生成和视频问答,提升模型的泛化能力。
- 插件式设计:模型的多模态框架设计为插件式,可以轻松集成到其他预训练模型中。
工作原理
- 视觉编码器适应:通过微调预训练的视觉编码器,使其能够处理动态分辨率的图像输入。这一阶段使用大规模场景图像、文档和场景文本图像进行训练。
- 视觉-语言对齐:在这一阶段,模型通过大规模图像-文本数据进行训练,建立视觉编码器、投影模块和大型语言模型(LLM)之间的对齐。数据包括详细的场景图像描述、文档和图表数据,以及少量纯文本数据。
- 多任务微调:在这一阶段,模型通过多种多模态问答数据进行微调,涵盖图像和视频任务。这一阶段还引入了视频压缩模块,减少视频数据的冗余。
- 视频中心微调:在这一阶段,模型通过大规模视频数据进行微调,进一步提升视频理解能力。数据包括一般视频、流媒体视频、时间定位信息标注的视频、纯图像数据和纯文本数据。
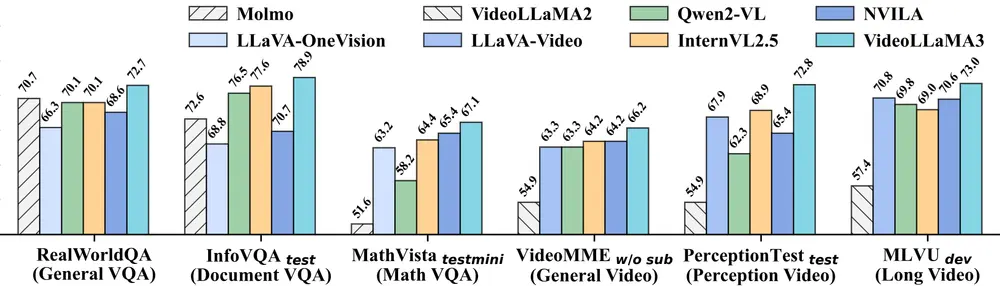
具体应用场景
- 内容创作:生成高质量的视频字幕、视频摘要和视频问答,帮助内容创作者快速生成视频脚本和字幕。
- 教育领域:为教育视频生成详细的字幕和解释,帮助学生更好地理解教学内容。
- 智能客服:通过理解用户上传的图像或视频,自动生成相关的回答或解决方案,提升客服效率。
- 视频监控:实时分析监控视频,检测异常行为或事件,并生成警报信息。
- 医疗影像分析:辅助医生分析医学图像,生成详细的报告和诊断建议。
- 自动驾驶:处理车载摄像头的视频流,实时识别道路状况和交通标志,辅助驾驶决策。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











