尽管前沿的多模态模型(如 GPT-4O)在代码生成上展现了强大的能力,但它们在真实的前端开发场景中仍无法满足现代前端工作流程的动态需求。这些模型虽然能够生成代码,但输出的前端代码通常是静态的,缺乏模块化、可重用性和动态行为等关键特性。这些特性对于构建可扩展、交互式的用户界面至关重要,因此生成的代码往往低效且不符合最佳开发实践。
为了解决这一问题,Flame-Code-VLM团队提出了一套完整的解决方案,包括数据合成管线、模型训练及评估套件,并基于此构建了 Flame 模型。Flame 能够根据图文信息生成特定前端框架的代码,目前专注于 React 开发场景。
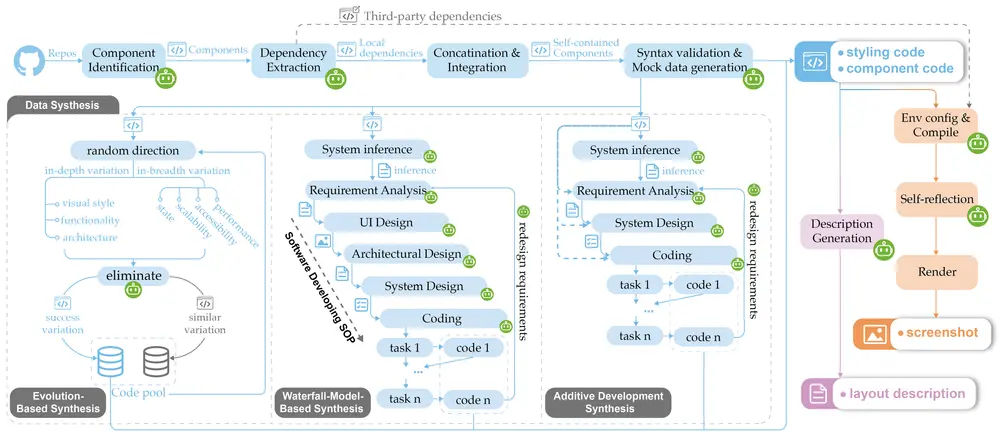
1. 数据合成
核心挑战:构建高质量的图-文(代码)数据集是关键。我们提出了一个智能体工作流驱动的数据合成管线,能够提取、渲染并注释自包含的前端代码片段。该管线确保生成的大规模、多样化且高保真的数据集,支持单图像和多图像输入,并提供详细的图像描述,可用于视觉思维推理开发。
数据合成策略:
- 基于进化思想的合成:模拟自然选择过程,逐步优化代码片段。
- 基于瀑布流模型的合成:按照线性阶段逐步生成数据。
- 基于增量式开发思想的合成:逐步迭代,逐步完善代码。
在数据合成过程中,我们通过 DeepSeek API 接入 DeepSeek V2 和 V3 模型进行数据构建。生成的图文(代码)数据将全部开源。
2. 模型训练
我们通过将 Siglip 图像编码器 与 Deepseek 的代码模型 通过一个两层 MLP 连接,构建了 Flame 模型,并采用三阶段训练策略:
- 第一阶段:预热两层连接器,使用公开的图文数据进行训练。
- 第二阶段:训练图像编码器及连接器,使用合成的数据进行训练。
- 第三阶段:进行 SFT(Supervised Fine-Tuning),训练所有参数,同样使用合成数据。
这种训练方案在特定场景的数据下表现出更好的效果。
3. 评估套件
为了确保生成的代码符合实际开发标准,我们构建了一个全面的评估套件,评估生成代码的三个关键因素:
- 语法精确性:代码是否符合语法规范。
- 功能正确性:代码是否能实现预期功能。
- 视觉一致性:生成的 UI 是否与设计稿一致。
该评估方法为未来的多模态模型代码生成能力提供了可靠的测评标准。
4. 特性与优势
- 全面的数据准备管道:仓库包含使用三种不同数据合成方法提取、合成和结构化多模态数据集的脚本和工具。
- 端到端训练管道:实现了 Flame 的三阶段训练策略,包括视觉编码器预训练、图像布局解释训练和完整的指令调优。
- React 代码生成的评估管道:提供了基准测试数据集、自动化测试脚本和 pass@k 评估指标。
- 支持多图像输入:模型能够处理多个版本的设计稿,并相应地更新生成的代码,实现迭代式 UI 优化。
5. 训练与实现
Flame 的实现基于 LLaVA-VL/LLaVA-NeXT 的修改。使用时,只需将原仓库中相应的代码文件替换为本仓库中的代码文件。我们公开了构建 Flame 数据准备管线、模型训练过程和评估套件的完整实现,旨在推动多模态前端代码生成技术的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











