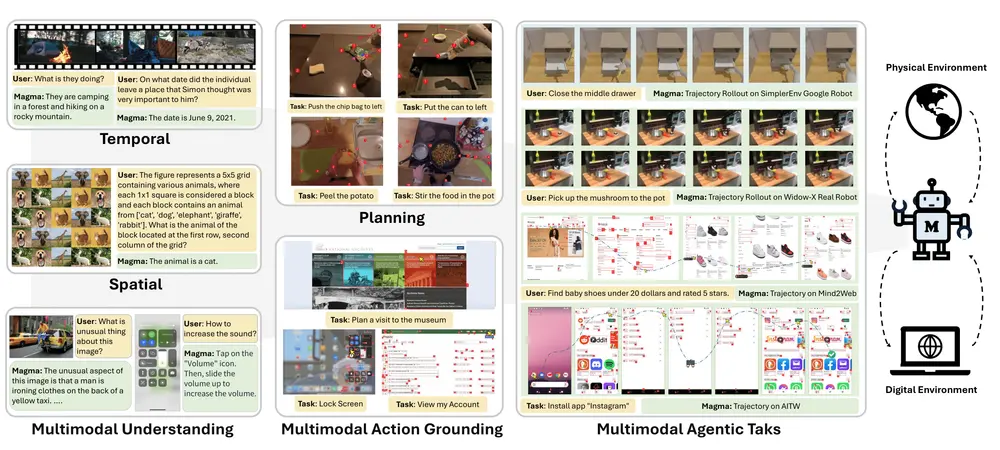
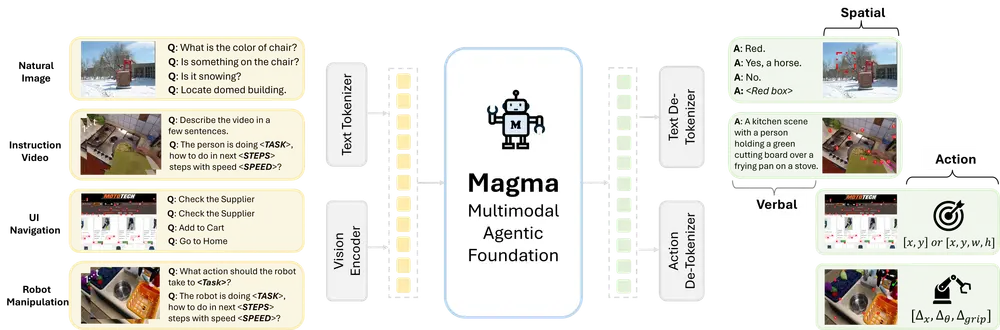
Magma 是由微软研究院推出的一款面向多模态AI代理的基础模型,为一系列智能任务提供强大的支持。它不仅具备视觉-语言(VL)模型的理解能力(即语言智能),还拥有在视觉空间世界中规划和执行动作的能力(即空间-时间智能)。这种结合使得Magma能够完成从用户界面导航到机器人操控等一系列复杂的智能任务。
- 项目主页:https://microsoft.github.io/Magma
- GitHub:https://github.com/microsoft/Magma
- 模型:https://huggingface.co/microsoft/Magma-8B
与传统 Agent 相比,Magma 具备跨数字、物理世界的多模态能力,能自动处理图像、视频、文本等不同类型数据,此外,Magma 还能内置了心理预测功能,增强了对未来视频帧中时空动态的理解能力,能够准确推测视频中人物或物体的意图和未来行为。
核心目标与特性
1. 语言和时空智能
Magma 模型同时具备强大的语言智能和时空智能,能够理解图像和视频内容,并基于观察结果执行动作。它还能将外部目标转化为具体的行动计划并加以执行。
2. 数字与物理世界的跨域能力
Magma 不局限于数字世界(如网页导航)或物理世界(如机器人操作),而是能够像人类一样跨越这两个领域工作。无论是虚拟环境中的任务规划,还是现实世界中的机器人操作,Magma 都能胜任。
研究团队如何预训练 Magma?
为了实现上述目标,研究团队采用了以下两种关键策略:
1. 大规模异构训练数据
研究团队整理了大量异构数据,包括:
- 多模态理解数据:用于训练模型理解文本、图像和视频。
- UI 导航数据:帮助模型学习如何在数字环境中进行交互。
- 机器人操作数据:提升模型在物理世界中的动作规划和执行能力。
- 野外未标记的视频:通过一种新的数据收集流程,研究团队以可扩展且成本效益高的方式获取了这些数据。
为了从原始视频和机器人轨迹中提取有用的动作监督,研究团队移除了视频中的相机运动,并将剩余的运动转化为模型训练所需的“动作”监督信号。这些数据为模型学习跨模态连接以及长时程动作预测和规划提供了独特的信号。
2. 通用预训练目标
由于文本和动作本质上存在巨大差异,而视觉标记是连续的,研究团队提出了一种统一所有三种模态(文本、图像和动作)训练的通用预训练框架。具体而言:
- 研究团队提出了“标记集合”(Set-of-Mark)和“标记轨迹”(Trace-of-Mark)作为辅助任务,用作不同输出模态之间的桥梁。
- 这种方法在文本和动作模态之间,以及图像和动作模态之间建立了良好的对齐,从而增强了模型的跨模态理解能力。
用户指南:直接使用
Magma 模型适用于英语的广泛研究用途,主要功能包括:
1. 图像/视频条件文本生成
Magma 可以根据输入的文本和图像生成描述性文本或答案。例如:
- 输入一张博物馆展览的照片,模型可以生成对该展览的详细描述。
- 提供一段视频和相关问题,模型可以回答关于视频内容的问题。
2. 视觉规划能力
Magma 能够生成完成特定任务的未来规划,例如:
- 将物体从一个地方移动到另一个地方的具体步骤。
- 在复杂环境中规划机器人路径。
3. 代理能力
Magma 可以生成用户界面接地(如点击按钮)和机器人操作(如控制机械臂的7个自由度)。例如:
- 在数字环境中,指导用户完成特定的操作。
- 在物理环境中,控制机器人完成复杂的任务。
下游任务微调
Magma 模型可以通过进一步微调应用于多种下游任务,包括但不限于以下场景:
1. 图像字幕和问答
通过多模态LLM流程微调,Magma 可以在图像字幕和问答任务上实现有竞争力的性能,同时具备更好的空间理解和推理能力。
2. 视频字幕和问答
同样,Magma 可以通过微调应用于视频字幕和问答任务,表现出更强的时间理解和推理能力。
3. UI 导航
针对特定的UI导航任务(如网页导航或移动应用导航),Magma 可以经过微调后实现卓越的性能。
4. 机器人操作
凭借其作为视觉-语言-动作模型的通用代理能力,Magma 可以进一步微调用于机器人任务。实验表明,经过微调后,Magma 在机器人操作任务上的表现显著优于现有最先进的模型(如OpenVLA)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











