字节跳动近日推出了UNO,这是一个强大的通用框架,能够从单一主体到多主体进行定制化演进。UNO不仅展示了出色的泛化能力,还能将多样化的任务统一在一个模型之下,为图像生成领域带来了新的突破。
- 项目主页:https://bytedance.github.io/UNO
- GitHub:https://github.com/bytedance/UNO
- 模型:https://huggingface.co/bytedance-research/UNO
- Demo:https://huggingface.co/spaces/bytedance-research/UNO-FLUX
- ComfyUI插件:https://github.com/jax-explorer/ComfyUI-UNO (需要27G显存才可以运行)
UNO的核心优势
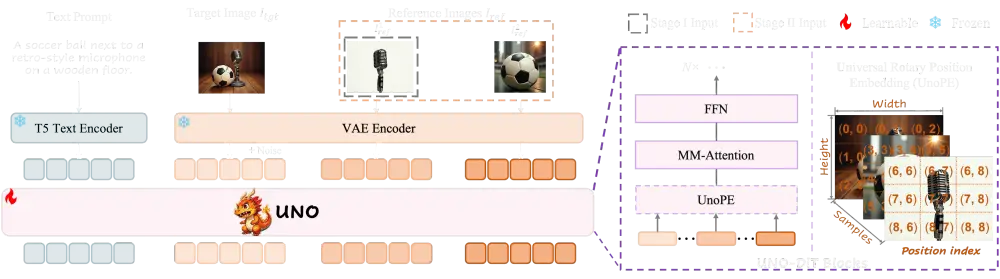
UNO的核心优势在于其强大的泛化能力和多主体生成能力。尽管基于主体的生成在图像生成领域有着广泛的应用,但目前仍面临数据可扩展性和主体扩展性的挑战。UNO通过一个高度一致的数据合成管道和逐步训练框架,成功解决了这些问题。它利用扩散变换器的内在上下文生成能力,生成高一致性的多主体配对数据,并通过渐进式跨模态对齐和通用旋转位置嵌入(UnoPE)进一步提升性能。

主要功能
- 高一致性多主体图像生成:UNO能够生成与文本描述和参考图像高度一致的多主体图像,支持多种图像格式(如ISO和PKG),并提供虚拟游戏手柄和物理控制器的支持。
- 模型数据协同进化:通过合成数据生成框架,从单主体到多主体逐步生成高质量的训练数据,并通过迭代训练将文本到图像(T2I)模型逐步转化为多图像条件的主体到图像(S2I)模型。
- 通用旋转位置嵌入(UnoPE):通过调整位置索引,减少参考图像的空间结构对生成图像的影响,提高主体相似性,同时保持良好的文本可控性。
工作原理
UNO的工作原理基于两项关键改进:渐进式跨模态对齐和通用旋转位置嵌入(UnoPE)。
- 数据合成:
- 构建一个包含多种类别和场景的分类树,利用大型语言模型(LLM)生成多样化的主体实例和场景描述。
- 使用预训练的T2I模型(如FLUX.1)生成主体一致的图像对,并通过DINOv2和VLM进行质量过滤。
- 逐步训练:
- 单主体训练:使用单主体图像对训练T2I模型,使其具备主体到图像(S2I)的能力。
- 多主体训练:进一步使用多主体图像对训练模型,增强其在复杂场景下的表现。
- 通用旋转位置嵌入(UnoPE):
- 通过调整位置索引,减少参考图像的空间结构对生成图像的影响,使模型更专注于文本特征,提高主体相似性。
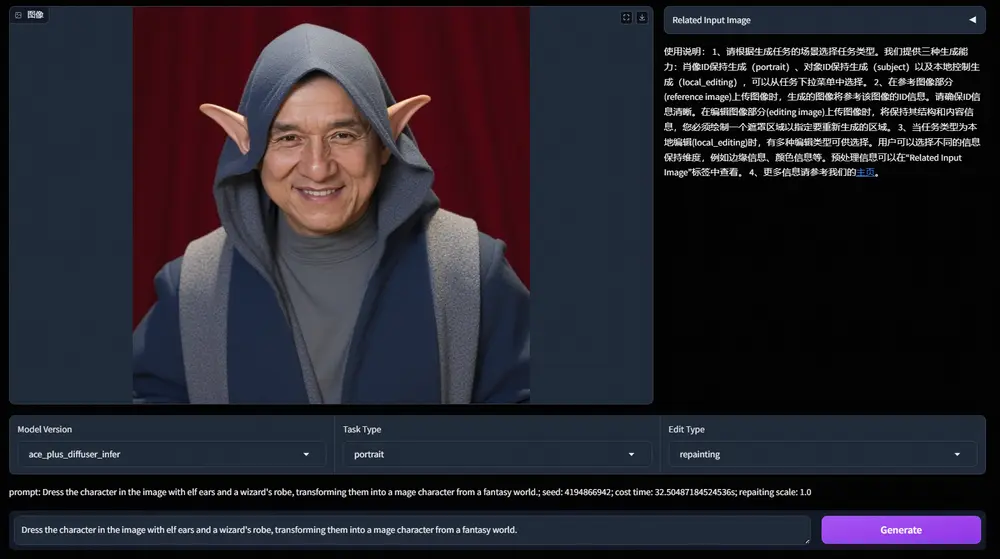
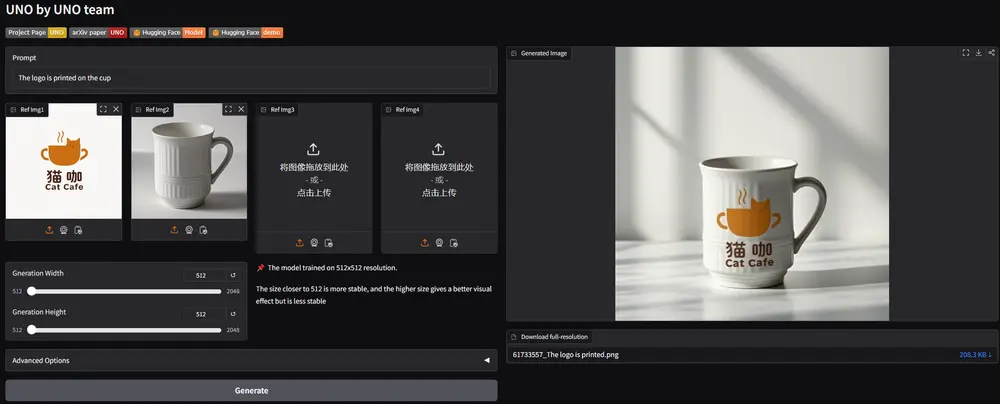
应用场景
UNO的应用场景非常广泛,以下是一些具体例子:
- 虚拟试穿:用户可以上传自己的照片,通过UNO模型生成试穿不同服装的效果图,无需实际试穿。
- 身份保留:在生成图像时保留特定主体的身份特征,例如生成带有特定人物形象的虚拟场景。
- 风格化生成:根据用户提供的文本描述,生成具有特定风格(如吉卜力风格、漫画风格)的图像。
- 产品设计:生成带有特定品牌标志或文字的产品设计图,如带有品牌标志的T恤或杯子。
- 故事生成:根据文本描述生成一系列连贯的图像,用于故事板或动画制作。
- 多主体驱动生成:在同一场景中生成多个主体,例如生成包含多个角色的复杂场景图。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











