
特拉维夫大学和英伟达的研究人员介绍了一种名为 IP-Composer 的新型训练自由(training-free)方法,用于从多个视觉概念中合成图像。该方法通过自然语言描述从输入图像中提取特定概念,并将这些概念组合成新的图像。IP-Composer 基于 IP-Adapter 架构,通过构建复合嵌入向量(composite embeddings)来实现多图像参考的合成,从而在不依赖训练数据的情况下生成高质量的图像。
- 项目主页:https://ip-composer.github.io/IP-Composer
- GitHub:https://github.com/saradorfman1/IP_Composer
- Demo:https://huggingface.co/spaces/IP-composer/ip-composer
例如,你想要生成一张包含特定背景和特定主体的图像。例如,你有一张城市夜景的图片(背景)和一张狗的图片(主体)。通过 IP-Composer,你可以指定从背景图片中提取“夜景”概念,从狗的图片中提取“狗”概念,然后生成一张狗在城市夜景中的新图像。
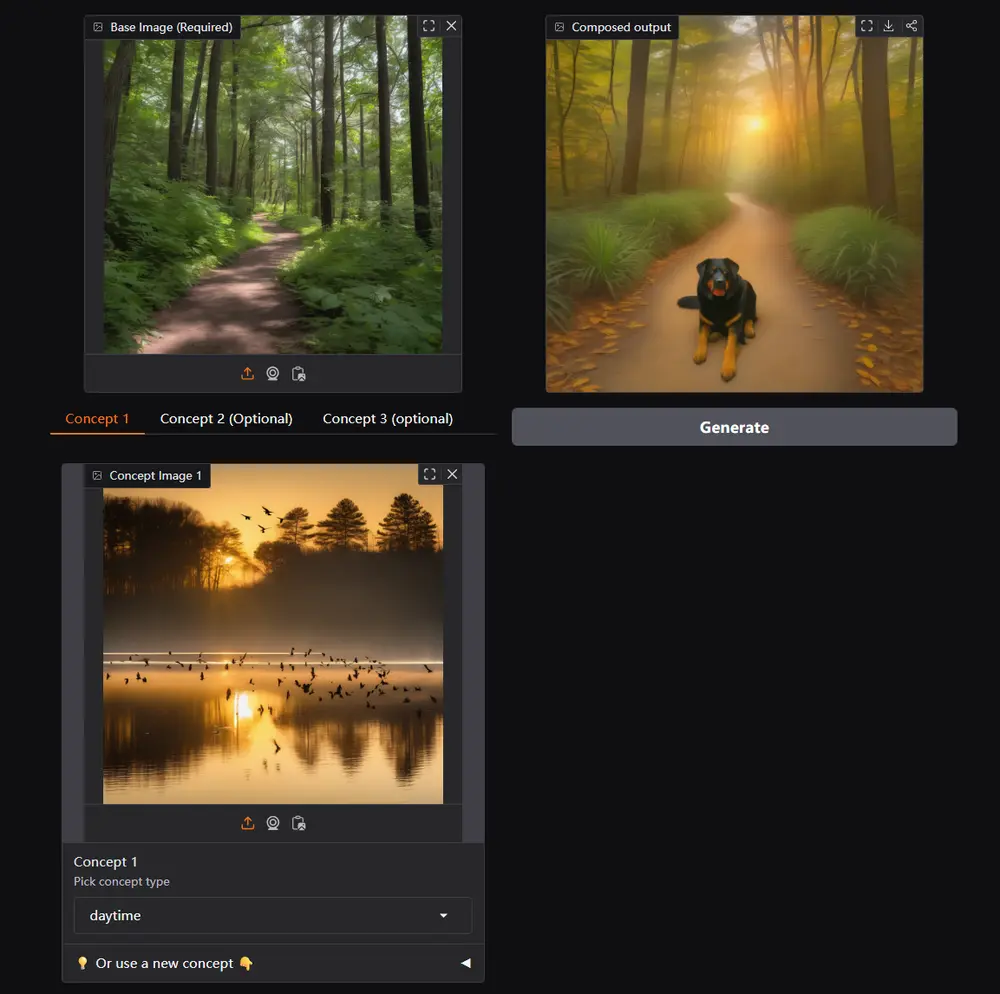
主要功能
- 多图像参考合成:IP-Composer 能够同时处理多个输入图像,从每张图像中提取特定的概念,并将这些概念组合成新的图像。
- 自然语言描述:用户可以通过自然语言描述来指定从每张输入图像中提取的概念,例如“提取这张图片中的花朵”或“提取这张图片中的灯光效果”。
- 训练自由:该方法不需要针对特定任务的训练数据或模型微调,可以直接应用于各种概念组合。
- 高精度控制:通过精确的语义子空间投影,IP-Composer 能够更精确地控制视觉概念的组合,减少不相关属性的泄漏。

主要特点
- 基于 CLIP 的语义子空间:IP-Composer 利用 CLIP 模型的语义子空间结构,通过文本描述来识别和提取特定概念。
- 复合嵌入向量:通过将多个输入图像的嵌入向量投影到特定的语义子空间,并重新组合这些投影,生成新的复合嵌入向量。
- 灵活性和通用性:该方法能够处理各种视觉概念,包括布局、纹理、对象插入等,而无需针对每个任务进行专门的训练。
- 减少属性泄漏:通过精确的子空间投影,IP-Composer 能够减少不相关属性的泄漏,提高合成图像的质量。
工作原理
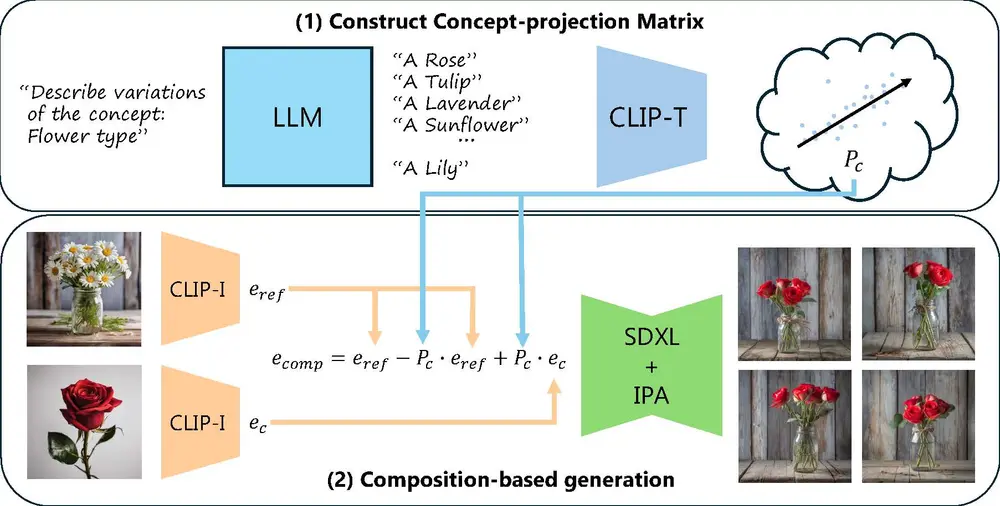
- 构建投影矩阵:
- 使用大型语言模型(LLM)生成描述特定概念的文本列表。
- 将这些文本通过 CLIP 文本编码器编码为嵌入向量。
- 对这些嵌入向量进行奇异值分解(SVD),提取最显著的语义方向,构建投影矩阵。
- 图像合成:
- 对于每张输入图像,计算其 CLIP 嵌入向量。
- 将输入图像的嵌入向量投影到特定的语义子空间,提取出特定概念的嵌入向量。
- 将这些提取的概念嵌入向量重新组合,形成复合嵌入向量。
- 使用 IP-Adapter 将复合嵌入向量输入到扩散模型中,生成最终的合成图像。
测试结果
- 定性结果:
- IP-Composer 能够处理多种视觉概念,包括背景替换、纹理转移、对象插入等。
- 该方法不仅能够处理成对的输入图像,还可以扩展到多个输入图像的组合。
- 与现有的训练方法相比,IP-Composer 在生成图像的质量和概念控制上表现出色。
- 定量比较:
- 通过计算生成图像与目标概念的 CLIP 空间距离,IP-Composer 在相似性上优于或等于现有的训练方法。
- 在用户研究中,IP-Composer 被用户更频繁地选择为更好的合成结果,表明其在视觉效果上的优势。
- 消融研究:
- 与简单的嵌入向量插值或拼接方法相比,IP-Composer 在概念控制和减少属性泄漏方面表现更好。
- 通过调整子空间的维度(即奇异值的数量),可以进一步优化合成结果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











