腾讯混元项目组正式开源 HunyuanImage 3.0-Instruct —— 一款专注于图像编辑的原生多模态大模型。该模型不仅能理解输入图像的语义内容,还能基于复杂指令进行推理,并生成高保真、高一致性的编辑结果。
- GitHub:https://github.com/Tencent-Hunyuan/HunyuanImage-3.0
- Hugging Face:https://huggingface.co/tencent/HunyuanImage-3.0-Instruct
- Hugging Face (Distil):https://huggingface.co/tencent/HunyuanImage-3.0-Instruct-Distil
- Demo:https://hunyuan.tencent.com/chat/HunyuanDefault?from=modelSquare&modelId=Hunyuan-Image-3.0-Instruct
其核心突破在于原生统一了视觉理解与图像生成能力,无需依赖外部模块或级联流程,实现端到端的智能编辑。

模型架构:800 亿参数 MoE,130 亿激活
HunyuanImage 3.0-Instruct 基于 800 亿总参数的混合专家(MoE)架构,每次推理仅激活约 130 亿参数,在保持高性能的同时控制计算开销。这一设计使其既能处理细粒度视觉任务,又具备大规模语言-视觉对齐能力。
核心创新:原生思维链 + MixGRPO 算法
与传统“指令-执行”式模型不同,HunyuanImage 3.0-Instruct 内置 原生思维链(Chain-of-Thought, CoT)机制:
- 面对复杂编辑指令(如“将左侧人物换成穿红色风衣的女性,背景改为雨天东京街头”),模型会先进行多步推理,分解任务目标;
- 结合腾讯自研的 MixGRPO 强化学习算法,优化生成结果与人类偏好的一致性;
- 最终输出不仅满足指令要求,还保持非编辑区域的像素级一致性,避免无关内容被意外修改。
这一机制使模型真正具备“思考”能力,而非简单模式匹配。
关键能力
1. 精准局部编辑
- 支持添加、移除、替换图像中的特定元素;
- 严格保护非目标区域,确保背景、光照、透视等上下文不变;
- 适用于人像换装、物体移除、场景替换等精细操作。
2. 多图像无缝融合
- 可同时解析多张参考图,提取关键元素(如人物、物品、风格);
- 将其融合为单一、连贯的新场景,保持光照、比例与风格统一;
- 例如:从图 A 提取人物,图 B 提取建筑,图 C 提取天气效果,合成一张完整街景。
3. 智能提示词增强
- Instruct 版本支持对用户输入的自然语言提示进行自动优化;
- 即使提示简略(如“加个帽子”),也能推断合理细节(帽子类型、颜色、光影匹配)。
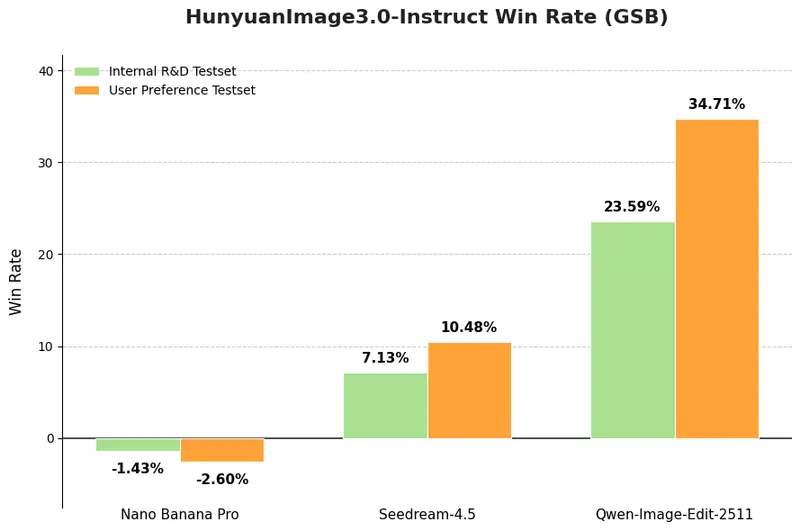
性能表现:人工评估 SOTA
在 GSB(Good/Same/Bad)人工评估中,模型表现达到当前领先水平:
- 评估规模:1000+ 单图与多图编辑案例
- 评估方式:每条提示仅生成一次,无结果筛选;100+ 专业评估员盲测
- 对比基准:与主流开源及闭源模型在默认设置下公平比较
结果显示,HunyuanImage 3.0-Instruct 在整体图像感知质量与指令对齐度上显著优于多数基线模型,性能可与顶尖专有系统媲美。
版本与部署
- HunyuanImage-3.0-Instruct:完整版,支持复杂推理与高保真生成
- HunyuanImage-3.0-Instruct-Distil:蒸馏版本,推荐用于高效部署,8 步采样即可获得高质量结果
两个版本均已在 Hugging Face 开源,支持本地运行,无需 API 调用。
开源愿景
腾讯混元希望通过开放 HunyuanImage 3.0-Instruct,为社区提供一个强大、可靠、可扩展的图像编辑基础模型,推动创意工具、内容生成、AIGC 应用等领域的创新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











