
阿里 DiffSynth-Studio 项目组 推出 Z-Image-i2L(Image to LoRA)模型——一种“以图生 LoRA”的创新方案。只需输入一张或多张风格统一的图像,模型即可自动生成一个可用于 Stable Diffusion 的 LoRA 微调模型,快速复现目标视觉风格。
该模型基于早期 Qwen-Image-i2L 架构,现已全面迁移至 Z-Image 基座,显著增强风格保持能力与细节还原精度,特别适合角色设计、插画风格迁移、产品视觉一致性等场景。

核心特点
- 端到端生成:输入图像 → 输出可直接加载的
.safetensorsLoRA 文件 - 风格聚焦:专为捕捉色彩、笔触、构图等视觉特征而优化
- 轻量高效:生成的 LoRA 模型体积小,推理开销低
- 兼容性强:适用于任何基于 Z-Image 架构的文生图流程
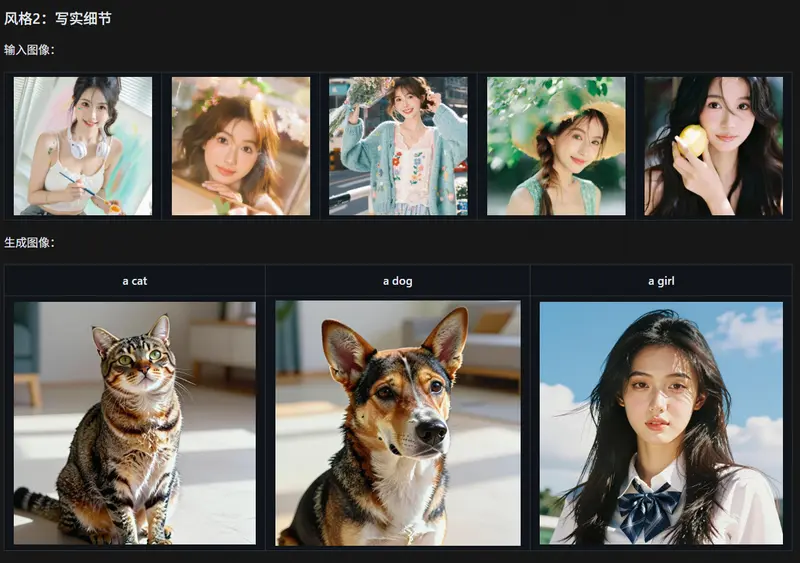
💡 提示:为获得最佳效果,建议使用 3–5 张风格一致的图像(如同一角色的不同角度、同一画师的多幅作品)。
推荐使用参数
为确保生成图像质量,请严格遵循以下配置:
正向提示词(Prompt):启用 LoRA
负向提示词(Negative Prompt):关闭 LoRA(仅使用通用负面词)
CFG Scale:4
Sigma Shift:8
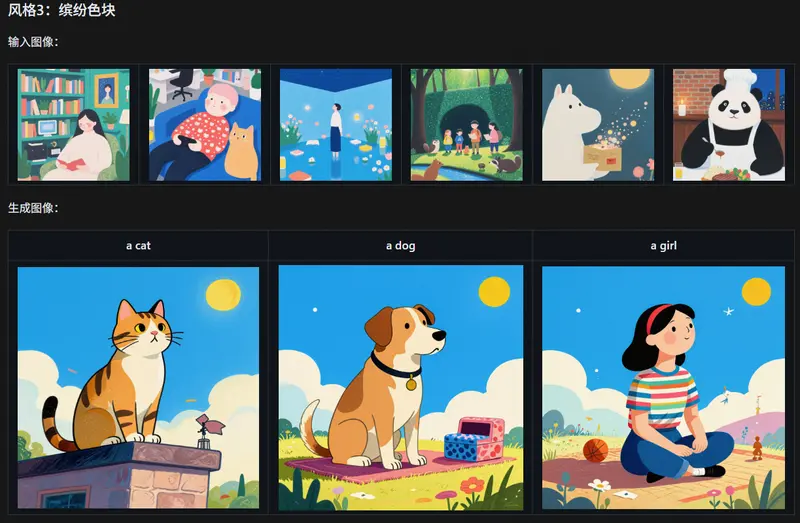
负面提示词(中英文任选)
中文:
泛黄,发绿,模糊,低分辨率,低质量图像,扭曲的肢体,诡异的外观,丑陋,AI感,噪点,网格感,JPEG压缩条纹,异常的肢体,水印,乱码,意义不明的字符
English:
Yellowed, green-tinted, blurry, low-resolution, low-quality image, distorted limbs, eerie appearance, ugly, AI-looking, noise, grid-like artifacts, JPEG compression artifacts, abnormal limbs, watermark, garbled text, meaningless characters
⚠️ 关键技巧:仅在正向提示中加载 LoRA,负向提示中禁用,可显著减少伪影并提升风格纯净度。
在线体验与部署
- 在线试用:ModelScope Studio - Z-Image-i2L
- 输出格式:标准
.safetensors,可直接用于ComfyUI平台
适用场景
- 角色一致性生成:为原创角色快速创建专属 LoRA
- 画师风格复现:输入某位艺术家的作品,生成其风格的生成模型
- 品牌视觉统一:确保产品图、宣传图保持一致美学
- 社区创作加速:省去数小时 LoRA 训练时间,实现“所见即所得”
注意事项
- 单张图像可能泛化不足,建议多图输入以提升鲁棒性
- 不适用于写实摄影(因 LoRA 更擅长风格化特征)
- 生成的 LoRA 为风格导向,非身份绑定(如需人脸 ID 保持,需结合 IP-Adapter 等方案)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











