香港科技大学的研究人员推出新型多模态音频生成框架“AudioX”,通过统一的模型架构实现从各种输入模态(如文本、视频、图像、音频等)生成高质量的音频和音乐。该框架通过创新的多模态掩码训练策略,强制模型从部分隐藏的输入中学习,从而生成鲁棒且统一的跨模态表示。例如,给定一段描述音乐风格的文本或一个视频场景,AudioX能够生成与之匹配的音频或音乐。
- 项目主页:https://zeyuet.github.io/AudioX
- GitHub:https://github.com/ZeyueT/AudioX
- 模型:https://huggingface.co/HKUSTAudio/AudioX
- Demo:https://huggingface.co/spaces/Zeyue7/AudioX
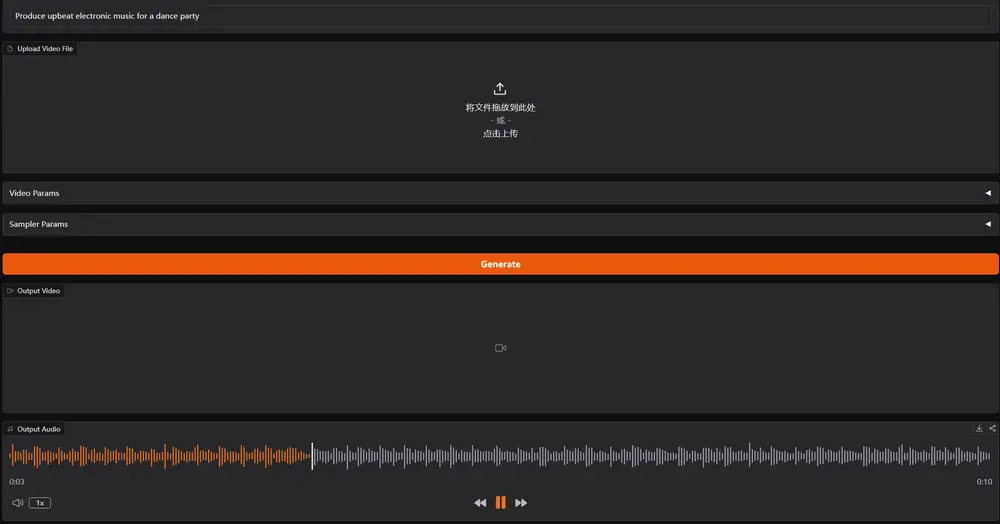
主要功能
- 多模态输入支持:AudioX能够处理文本、视频、图像、音频等多种输入模态,生成对应的音频或音乐。
- 高质量音频生成:通过结合扩散模型(Diffusion Models)和Transformer架构,AudioX能够生成高质量的音频,适用于多种音频生成任务。
- 灵活的任务适应性:支持多种音频生成任务,包括文本到音频(Text-to-Audio)、视频到音频(Video-to-Audio)、音频修复(Audio Inpainting)和音乐完成(Music Completion)等。
主要特点
- 多模态掩码训练策略:通过随机掩码输入模态的部分内容,迫使模型学习从不完整的输入中生成音频,增强了模型的跨模态学习能力和鲁棒性。
- 大规模多模态数据集:为了克服高质量多模态数据稀缺的问题,作者构建了两个大规模的多模态数据集,为模型训练提供了丰富的基础。
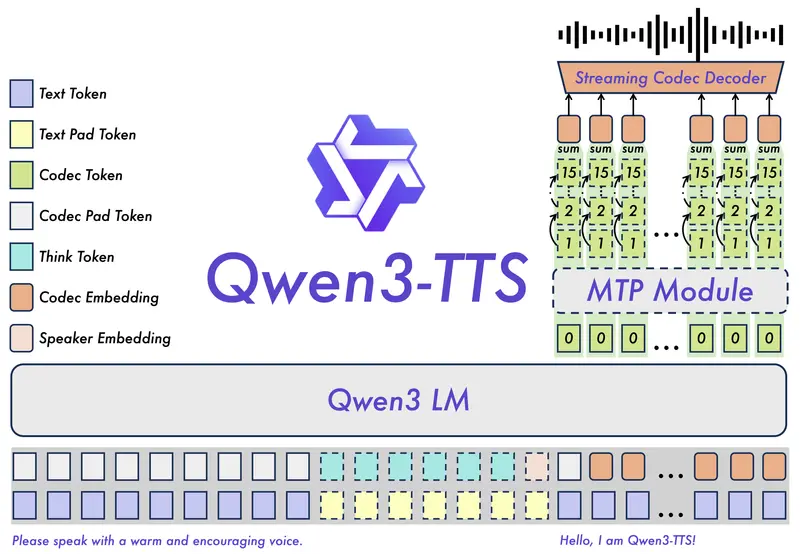
- 统一的模型架构:AudioX采用了一个统一的Diffusion Transformer(DiT)框架,能够处理多种输入模态,并生成高质量的音频输出。
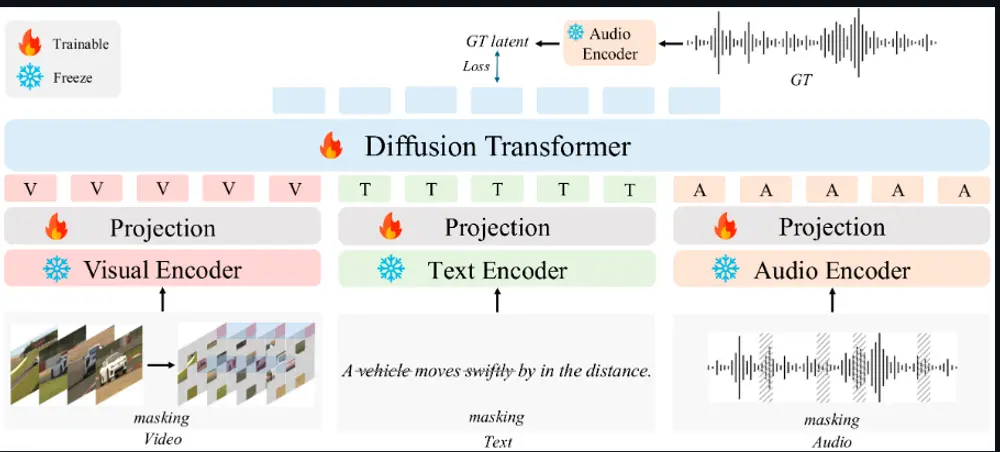
工作原理
- 输入处理:对于输入的文本、视频和音频,AudioX使用专门的编码器提取特征,并通过投影模块将特征映射到一个统一的特征空间。
- 掩码策略:在训练过程中,模型随机掩码输入模态的部分内容,如视频帧、文本片段或音频片段,迫使模型学习从不完整的输入中生成音频。
- 扩散过程:使用扩散模型的正向和反向过程,将噪声逐渐添加到音频数据中,然后训练模型逐步去除噪声,最终生成清晰的音频。
- 条件嵌入:将处理后的多模态特征与扩散时间步一起输入到DiT模型中,生成与输入条件一致的音频或音乐。
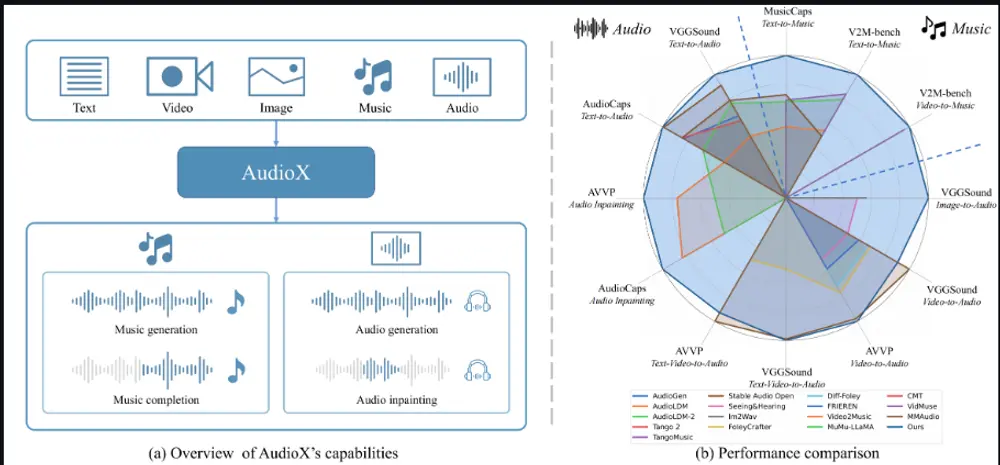
测试结果
- 性能提升:在多个音频生成任务上,AudioX的性能超过了现有的专门模型。例如,在文本到音频任务中,AudioX在AudioCaps数据集上取得了最佳性能。
- 多模态融合能力:AudioX能够有效地融合多种模态的输入信息,生成更高质量的音频。例如,在视频到音频任务中,AudioX能够根据视频内容生成与之匹配的环境音效。
- 泛化能力:AudioX在分布外的测试数据集上也展现出了良好的泛化能力,例如在AVVP数据集上的视频到音频任务中,AudioX能够生成与视频内容匹配的音频。
应用场景
- 多媒体内容创作:在视频制作、游戏开发和社交媒体中,AudioX可以自动生成与视觉内容匹配的音效和音乐,提升用户体验。
- 音频修复和编辑:AudioX可以用于音频修复任务,如填补音频中的缺失部分或修复损坏的音频片段。
- 音乐创作:AudioX可以根据文本描述或视频内容生成音乐,为音乐创作提供新的灵感和工具。
- 辅助技术:为视障人士提供音频描述,帮助他们更好地理解视觉内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











