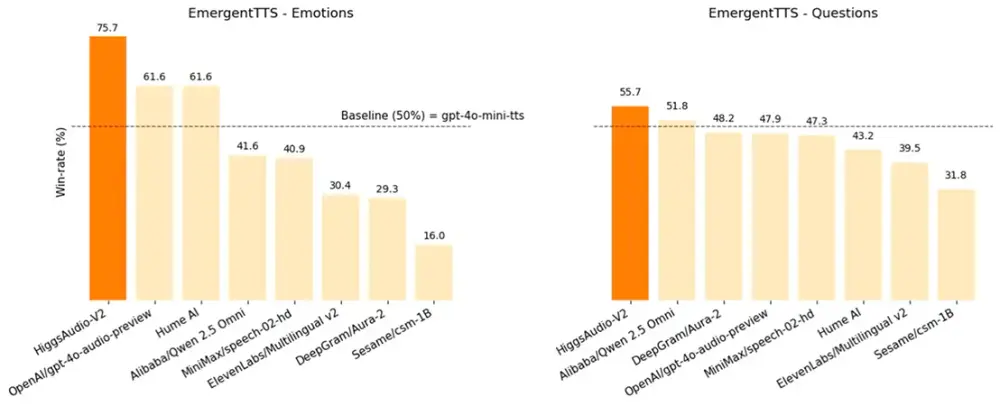
Kyutai 近日发布了一款名为 Unmute 的全新语音 AI 系统。与以往语音模型不同,Unmute 并不试图替代现有的语言模型,而是作为一个高度模块化的“插件”,可以无缝接入任意文本大语言模型,赋予其完整的语音交互能力。
这意味着,无论你正在使用哪种文本模型,只要接入 Unmute,它就能立刻“开口说话”。
核心功能一览
1. 智能判断语义完成
Unmute 能够判断你是否已经说完一句话,而不是简单地通过静音检测来决定是否打断。这种基于语义的语音活动检测(VAD),让它在对话中更自然、更贴近真人交流。
2. 支持随时打断
就像面对面交谈一样,你可以在它说话时随时插话,而系统会立即停止当前回应并转向你的新输入,实现真正的全双工语音交互体验。
3. 10秒语音样本即可定制声音
只需提供一段 10 秒钟的语音样本,Unmute 就能克隆出对应的声音特征,生成个性化的语音输出。这为个性化语音助手、角色配音等场景提供了极大便利。
4. 流式文本合成,降低响应延迟
Unmute 支持在文本尚未完全生成时就开始发声。也就是说,当语言模型还在逐步输出回答时,语音系统就可以提前开始朗读,从而显著缩短整体响应时间。
技术架构:模块化设计是关键
Unmute 的核心优势在于它的模块化结构:
- 语音转文本(STT)模块:支持流式输入,具备高精度语义 VAD,可识别说话人是否处于停顿或结束状态。
- 文本转语音(TTS)模块:基于 10 秒语音样本训练,支持个性化语音生成,并同样支持流式输出。
- 即插即用接口:无论是本地部署还是云端服务,Unmute 都可以通过标准接口快速集成到各类语言模型中。
这意味着开发者可以根据需要选择只使用语音识别部分、语音合成部分,或是两者结合使用,灵活性极高。
Moshi 与 Unmute 的区别
此前 Kyutai 曾推出过另一款语音模型 Moshi,它是首个专为实时音频交互设计的 AI 模型,在自然度和延迟控制方面表现出色。但 Moshi 是一个封闭的端到端系统,不具备扩展性。(相关:Kyutai发布首个开源实时语音模型MoshiVis,开启视觉与语音交互新时代)
相比之下,Unmute 更像是一个“桥梁”,它并不取代现有的语言模型,而是将其能力延伸至语音领域,使得像函数调用、上下文学习、复杂推理等功能也能在语音交互中得到体现。
开源计划
Kyutai 表示,Unmute 的所有技术将在未来几周内全部开源,包括 STT 和 TTS 模块。同时,他们也将以可控方式开放语音克隆模型的访问权限。
团队相信,未来的交互方式将越来越依赖于自然、双向的语音沟通。Unmute 的目标不仅是让机器“能说话”,更是让它们“会说话”——在合适的时间倾听,在合适的时机回应。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











