阿里通义实验室近日正式推出 Qwen3-ASR-Flash,一款基于 Qwen3 大模型基座 构建的高性能语音识别(ASR)服务。该服务融合千万小时级语音数据与海量多模态训练样本,致力于在准确率、鲁棒性与定制能力上实现突破。
- 魔塔Demo:https://modelscope.cn/studios/Qwen/Qwen3-ASR-Demo
- Demo:https://huggingface.co/spaces/Qwen/Qwen3-ASR-Demo
不同于传统 ASR 系统,Qwen3-ASR-Flash 在语言理解、复杂场景适应和用户个性化需求支持方面展现出显著优势,现已支持 11 种语言 及多种方言与口音,适用于会议记录、内容创作、跨语种交流等多种场景。
核心能力一览
高精度识别,在多语种 benchmark 中表现领先
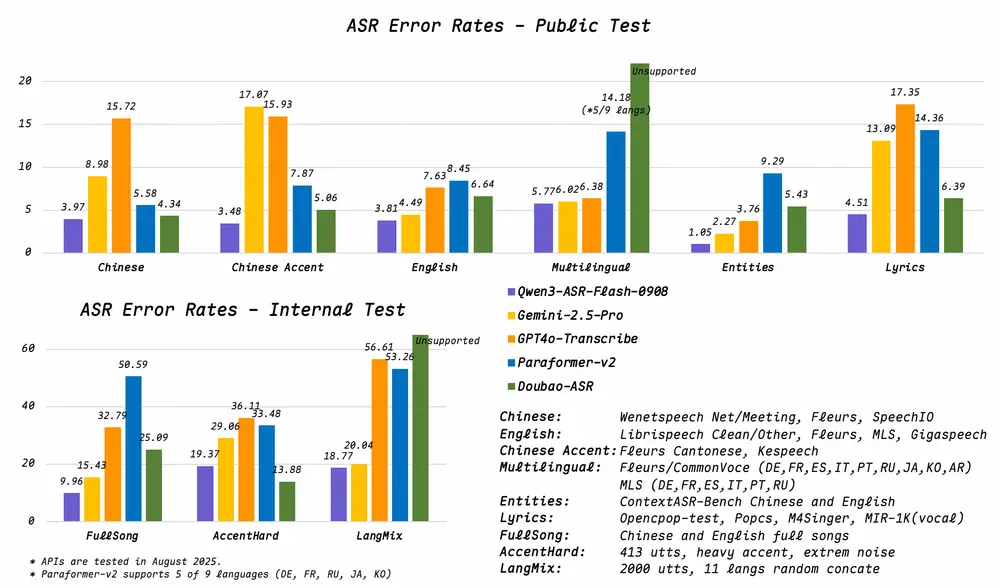
Qwen3-ASR-Flash 在多个中英文及多语种测试集上达到当前最优(SOTA)水平。无论是标准对话、专业术语密集场景,还是口语化表达,均能实现高保真转录。
支持歌声识别,清唱与带背景音乐均可识别
实测数据显示,该模型在清唱、伴奏歌曲等场景下的识别错误率低于 8%,可准确捕捉歌词内容,适用于音乐内容处理、K歌场景、影视对白提取等需求。
支持任意格式上下文提示,实现定制化识别
用户可提供任意形式的背景文本,系统将智能提取关键信息,提升命名实体、专业术语、人名地名等词汇的识别准确率。
支持输入格式包括:
- 简单关键词或热词列表
- 完整段落或技术文档
- 混合格式文本(如关键词+段落)
- 甚至无关或无意义文本(模型具备强鲁棒性,不会因此产生显著偏差)
无需预处理、无需结构化标注,真正实现“即输即用”的上下文增强体验。
多语言与方言支持,覆盖主流语种
单模型统一支持以下语言及变体:
- 中文:普通话、四川话、吴语、闽南语、粤语
- 英语:美式、英式及其他常见地区口音
- 其他语言:法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语、阿拉伯语
语种自动识别,无需手动切换,提升跨语言交互效率。
语种识别与非人声拒识
模型可自动判断音频片段是否为人声,有效过滤静音、环境噪声、音乐片段等非目标内容,减少无效输出,提升后处理效率。
强鲁棒性,应对复杂语音挑战
面对长句、重复表达、语码转换(如中英夹杂)、背景嘈杂等现实难题,模型仍能保持稳定输出,适用于真实场景下的高噪声环境。
技术背后:大模型驱动的 ASR 范式升级
Qwen3-ASR-Flash 并非传统端到端语音模型的简单迭代,而是依托 Qwen3 基座模型 的强大语言理解能力,将语音信号与上下文语义深度融合。通过千万小时语音数据与海量文本对齐训练,模型不仅“听见”声音,更能“理解”语境。
这种架构使得:
- 上下文利用更自然,无需额外 fine-tuning
- 多语言共享表征,降低模型复杂度
- 对低资源口音和边缘场景具备更强泛化能力
应用场景示例
| 场景 | 应用方式 |
|---|---|
| 学术讲座转录 | 提供讲义或参考文献作为上下文,准确识别专业术语 |
| 跨国会议记录 | 自动识别发言语种,无缝处理中英混讲内容 |
| 音乐内容分析 | 输入歌词文本辅助识别,提升带 BGM 歌曲识别准确率 |
| 医疗/法律会诊 | 上传术语表,确保关键名词不被误转 |
| 方言访谈整理 | 支持粤语、川话等方言输入,降低转写门槛 |
如何使用?
开发者与企业用户可通过阿里云 API 接口接入 Qwen3-ASR-Flash,支持实时流式识别与离线批量处理。无需上传上下文数据至训练集,所有提示信息仅在推理时临时使用,保障数据隐私。
更多技术细节与接入方式,请参考官方文档或通义实验室 GitHub 页面。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











