阶跃星辰开源的 Step-Audio-R1 打破了传统音频模型的性能瓶颈,成为首个支持“测试时计算扩展”的音频大语言模型。它通过创新的模态落地推理蒸馏技术,让模型直接基于声学特征进行链式思考,而非依赖文本转译,实现了“边听边想、想得越久答得越准”的核心优势,在综合音频基准测试中超越 Gemini 2.5 Pro,性能比肩 Gemini 3,为语音客服、多轮语音助手等场景提供了更可靠的技术方案。
- 项目主页:https://stepaudiollm.github.io/step-audio-r1
- GitHub:https://github.com/stepfun-ai/Step-Audio-R1
- 模型:https://huggingface.co/stepfun-ai/Step-Audio-R1
- Demo:https://huggingface.co/spaces/stepfun-ai/Step-Audio-R1
核心突破:解决音频模型的“反向扩展”痛点
传统音频模型的工作流程存在天然缺陷:先将声音转译为文本,再让文本模型进行推理。这种“音频-文本-推理”的链式架构不仅容易在转译环节丢失信息,还会出现“推理越长、性能越差”的反向扩展问题——思维链延伸会导致误差累积,最终影响答案准确性。

Step-Audio-R1 针对性解决了这一核心痛点:
- 摒弃文本替代推理:不再依赖音频转文本的中间环节,而是通过模态落地推理蒸馏技术,让模型直接锚定音高轮廓、节奏、音色、背景噪声等声学特征进行推理,文字仅作为最终输出形式。
- 思维链越长越准:由于推理过程直接基于原始声学信息,而非转译后的文本,随着思维链的延伸(测试时分配更多计算资源),模型能挖掘更多音频细节,准确性持续提升,彻底将“思维链负担”转化为“性能增益资产”。
- 多轮对话不丢上下文:基于声学特征的链式推理让上下文关联更紧密,在多轮语音交互中能精准保留对话逻辑,无需担心中间环节的信息损耗。
技术架构:声学特征与推理能力深度融合
Step-Audio-R1 延续了前代 Step Audio 系统的核心架构框架,同时针对模态落地推理进行了优化设计,确保声学特征与推理过程的深度绑定:
- 音频编码层:基于 Qwen2 的音频编码器,以 25 Hz 频率处理原始音频波形,精准捕捉音高、音色、节奏等核心声学细节;
- 适配层:将编码器输出下采样 2 倍至 12.5 Hz,实现音频帧与语言 token 流的精准对齐,避免推理过程中出现模态错位;
- 解码推理层:采用 Qwen2.5 32B 解码器,专门处理音频特征并生成结果。解码器会在特定标签内生成显式推理块,再输出最终答案,这种分离设计既能塑造推理的结构和内容,又能保证任务准确性。
该模型以 330 亿参数的音频-文本到文本模型形式,在 Hugging Face 上基于 Apache 2.0 协议开源,开发者可直接获取并部署。
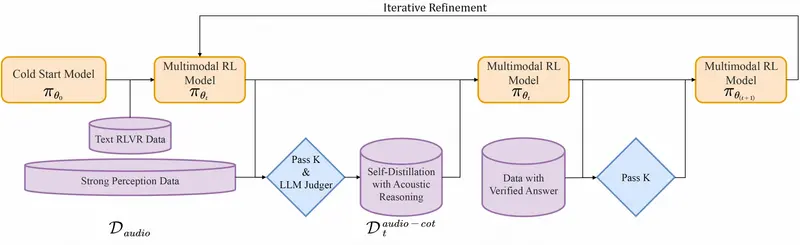
训练流程:从冷启动到音频落地的强化学习
Step-Audio-R1 的训练分为两大阶段,核心围绕“让模型推理锚定声学特征”展开:
1. 监督式冷启动
- 数据集:包含约 500 万个样本,涵盖 10 亿 token 纯文本数据和 40 亿 token 音频配对数据;
- 训练任务:音频侧包含自动语音识别、副语言理解、音频问答对话等,文本侧涵盖多轮对话、知识问答、数学与代码推理;
- 格式统一:所有样本的推理过程均包裹在特定标签内,即使初始阶段推理块为空,也为后续思维链训练奠定格式基础;
- 目标:让模型掌握基础的思维链行为,但此时模型仍偏向基于文本的推理。
2. 模态落地推理蒸馏 + 强化学习
这是让模型“脱离文本依赖”的关键阶段,分为多轮迭代:
- 筛选音频推理轨迹:采样答案依赖声学特性的问题(如说话者情感判断、背景事件识别、音乐结构分析),模型生成多个推理和答案候选,仅保留满足三个条件的思维链:参考声学线索、逻辑连贯、答案正确;
- 蒸馏微调:将筛选后的高质量音频思维链数据集,与原始文本推理数据结合,对模型进行微调;
- 带验证奖励的强化学习:采用 PPO 算法,每个提示采样 16 个响应,支持最长 10240 个 token 的长序列思考;奖励机制为:文本问题仅看答案正确性,音频问题 80% 权重给准确性、20% 权重给推理格式,确保模型重视声学推理过程。
此外,团队还设计了“自我认知校正流程”:通过直接偏好优化筛选偏好对,减少模型出现“无法听到音频”这类错误认知的频率,让模型明确自身具备音频处理能力。
基准测试:性能比肩 Gemini 3,实时交互延迟低
在综合音频基准测试中,Step-Audio-R1 表现亮眼,全面验证了其技术优势:
1. 语音到文本推理
- 测试套件:涵盖 Big Bench Audio、Spoken MQA、MMSU、MMAU、Wild Speech 等主流基准;
- 成绩:平均得分 83.6%,超越 Gemini 2.5 Pro(81.5%),与 Gemini 3 Pro(85.1%)差距仅 1.5 个百分点;
- 单项亮点:在 Big Bench Audio 上得分 98.7%,高于两个 Gemini 版本。
2. 语音到语音实时推理
- 技术特点:采用“边听边想、边思考边说话”的流式处理;
- 成绩:Big Bench Audio 语音到语音任务准确率 96.1%,首包延迟仅 0.92 秒;
- 优势:超越基于 GPT 的实时基线模型和 Gemini 2.5 Flash 风格原生音频对话,同时保持亚秒级交互延迟,适配实时场景需求。

消融实验:音频推理的关键设计要点
团队通过消融实验,为后续音频模型开发提供了明确的设计参考:
- 推理格式奖励不可少:缺少该奖励时,强化学习会倾向于缩短或移除思维链,导致音频基准测试分数下降;
- 强化学习数据需选中等难度:选择通过率处于中间区间的问题,能提供更稳定的奖励,帮助模型维持长推理能力;
- 数据质量优于数量:不加选择地扩展强化学习音频数据无意义,提示和标签的质量直接影响模型性能。
核心价值与应用场景
1. 技术价值
- 首次证明音频领域也能实现“测试时计算扩展”,打破“思维链越长性能越差”的反向扩展魔咒;
- 提出的模态落地推理蒸馏技术,为解决“文本替代推理”问题提供了可复现的方案;
- 开源的 330 亿参数模型,为开发者提供了高性能、可定制的音频推理基础工具。
2. 应用场景
- 多轮语音助手:基于声学特征的链式推理能精准保留上下文,适合智能音箱、车载语音等多轮交互场景;
- 语音客服:可精准识别用户语音中的情绪、意图,结合长推理能力解决复杂咨询,提升服务效率;
- 实时音频分析:亚秒级延迟支持实时语音翻译、会议纪要生成、环境声音识别等场景;
- 音频内容理解:适用于音乐结构分析、有声书内容提炼、语音情感分析等专业场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...