
ElevenLabs 正式发布 Scribe v2——一款专为大规模音视频内容处理设计的新一代语音转文字模型。与主打低延迟的 Scribe v2 Realtime 不同,Scribe v2 面向批量转录、字幕生成与说明文字制作场景,在准确性、鲁棒性与多语言支持上实现显著提升。
根据官方披露的行业基准测试,Scribe v2 在词错误率(WER)上达到当前最低水平,尤其擅长处理真实场景中的复杂语音特征。
为什么 Scribe v2 更可靠?
- 抗干扰能力强:能稳定处理长时间停顿、语气变化、语速波动甚至数秒静默;
- 90+ 语言支持:覆盖主流及部分小语种,满足全球化内容团队需求;
- 上下文感知转录:不仅识别语音,还能理解语义边界,减少断句错误。
该模型已集成至 ElevenLabs Studio,适用于媒体、营销、教育培训、合规审计等需要管理大量音视频资产的团队。
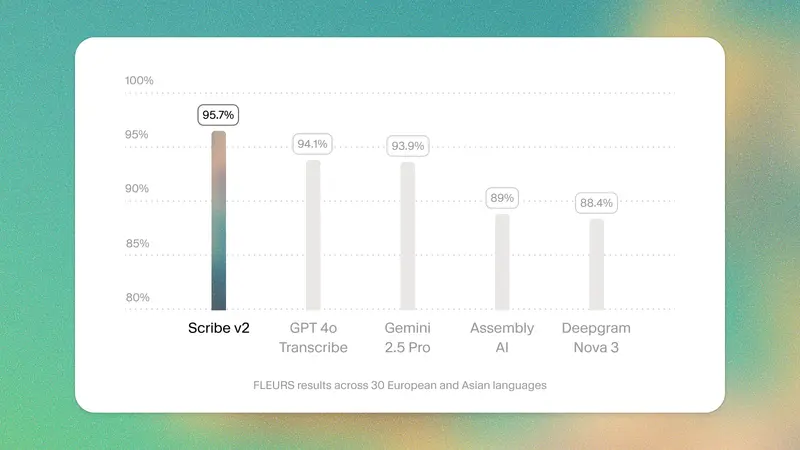
核心功能详解
关键术语提示(Context-Aware Custom Vocabulary)
不同于传统自定义词表,Scribe v2 允许用户提交最多 100 个关键词或短语(如品牌名、专业术语、人名),并基于上下文智能判断是否应转录为该形式。
例如:输入 “AI” 时,若上下文涉及技术讨论,则保留为 “AI”;若为口语 “哎”,则不强制替换。
实体检测(Entity Detection)
支持 56 类敏感信息识别,包括:
- 个人身份信息(PII):姓名、电话、地址
- 健康数据(PHI):病历号、诊断结果
- 支付信息:银行卡号、交易金额
系统将自动标记这些实体,并提供精确到毫秒的时间戳,便于后续脱敏或合规审查。
智能多语言混合转录
上传包含多种语言的音频(如中英混杂访谈),Scribe v2 可自动检测语言切换点,并以对应语言分别转录,无需预先分段。
智能说话人分离
自动区分不同说话者,并分配直观标签(如“Speaker 1”、“Interviewee”),输出结构清晰的对话式转录文本。
词级时间戳
每个单词均附带精确说出时间,支持:
- 字幕精准同步
- 视频剪辑快速定位
- 交互式语音回放(点击文字跳转音频)
动态音频事件标记
除语音外,Scribe v2 还能识别并标注非语音声音事件,如:
- 笑声、咳嗽、掌声
- 键盘敲击、脚步声、门开关
- 音乐片段、电话铃声
这些标记以结构化方式嵌入转录结果,丰富音频上下文信息。
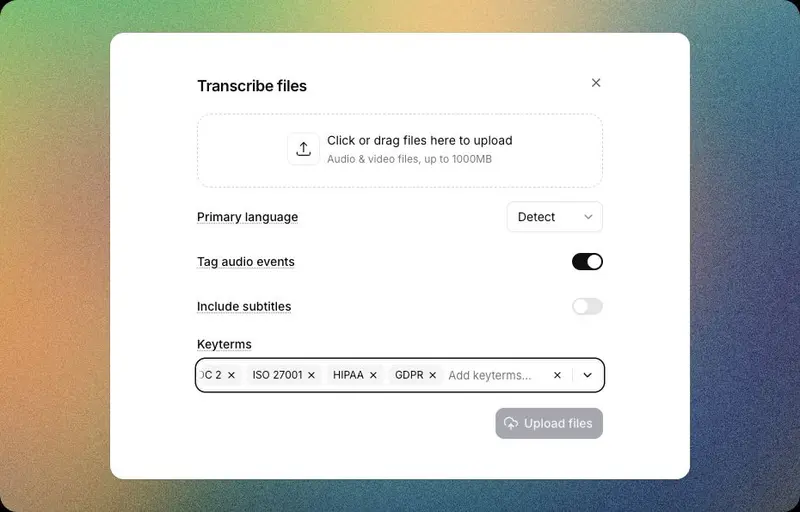
企业级合规与部署
Scribe v2 已通过多项国际认证:
- SOC 2 Type II
- ISO/IEC 27001
- PCI DSS Level 1
- HIPAA(医疗健康数据)
- GDPR(欧盟数据保护)
同时支持:
- 数据驻留:可选择将数据存储于欧盟或印度区域
- 零保留模式:处理完成后不保存原始音频或转录结果
- API 优先架构:便于集成到现有内容管理系统、工作流引擎或 AI 代理平台
适用场景
| 场景 | 应用方式 |
|---|---|
| 媒体与影视 | 自动生成多语言字幕、节目脚本整理 |
| 企业培训 | 将内部会议/课程转为可搜索文本库 |
| 市场研究 | 分析用户访谈录音,提取关键词与情绪信号 |
| 合规审计 | 检测客服通话中的敏感信息,确保法规遵从 |
| 开发者集成 | 通过 API 构建自动化转录流水线 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











