智谱AI推出的GLM-TTS是一款基于大语言模型的文本到语音合成系统,创新性采用LLM+Flow模型的两阶段架构,不仅实现了零样本语音克隆、流式推理等实用功能,还通过多奖励强化学习框架,大幅提升了语音的情感表现力与自然度。该系统支持中英混合文本合成,兼顾发音精准性与韵律流畅性,音质媲美商业级TTS产品。
- 项目主页:https://audio.z.ai
- GitHub:https://github.com/zai-org/GLM-TTS
- HuggingFace :https://huggingface.co/zai-org/GLM-TTS
- 魔塔:https://modelscope.cn/models/ZhipuAI/GLM-TTS
核心特性:四大亮点直击传统TTS痛点
GLM-TTS的优势集中体现在四个核心维度,覆盖从功能实用性到体验细腻度的全场景需求:
- 零样本语音克隆:仅需3-10秒的提示音频,即可快速克隆任意说话人的声音特征,无需针对特定说话人进行微调,大幅降低个性化语音生成的门槛;
- RL增强情感控制:引入多奖励强化学习框架,解决传统TTS情感表达平淡的问题,实现更自然的语气起伏、情感色彩与韵律控制;
- 流式推理实时生成:支持交互式应用场景下的实时音频输出,满足语音助手、直播字幕配音等低延迟需求;
- 音素级精准发音控制:针对多音字、生僻字等发音歧义问题,提供混合音素-文本输入机制,精准适配教育评测、有声读物等对发音准确性要求严苛的场景。
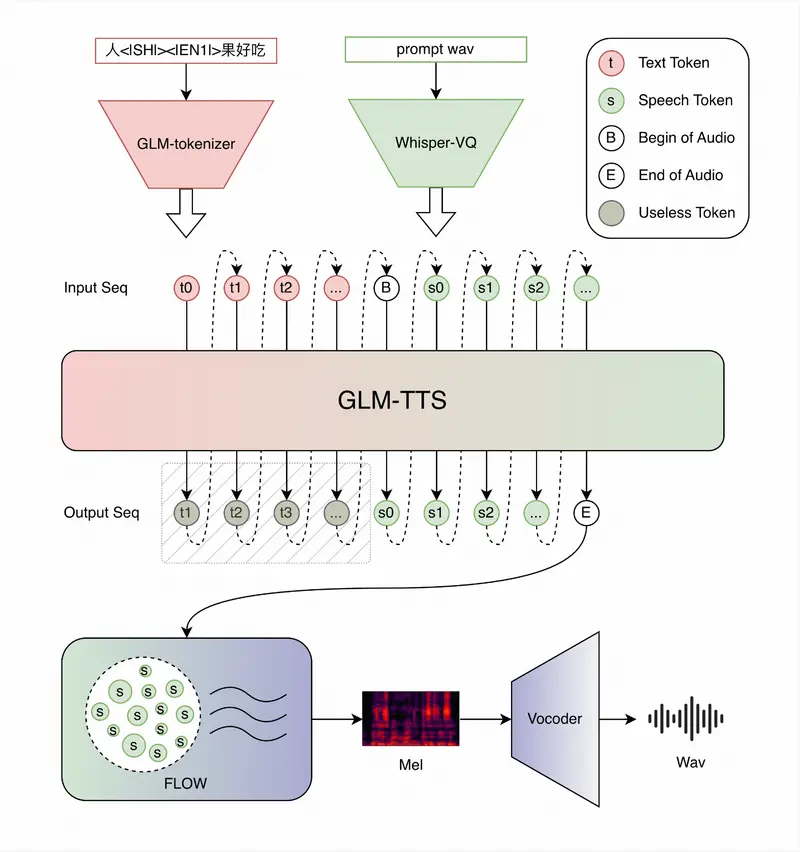
系统架构:两阶段设计,兼顾语义理解与音质还原
GLM-TTS的整体架构分为文本到语音token生成和token到音频波形合成两个阶段,分工明确且高效协同:
- 第一阶段:LLM生成语音token序列
基于Llama架构的大语言模型作为核心后端,负责将输入文本(支持纯文本或混合音素文本)转换为包含韵律、情感、发音信息的语音token序列。模型支持预训练、微调、LoRA三种部署模式,兼顾通用场景与个性化定制需求。 - 第二阶段:Flow Matching模型合成音频
Flow模型(核心为Diffusion Transformer架构)接收LLM生成的token序列,先将其转换为高质量梅尔频谱,再通过声码器生成最终的音频波形。该阶段内置流式推理模块,可实现实时音频输出,适配交互式应用场景。
关键技术:发音控制与混合模态训练
针对中文发音的复杂性,GLM-TTS专门设计了Phoneme-in精细化发音控制机制,核心流程分为训练与推理两步:
- 混合模态训练:训练时随机对文本中的部分字词进行G2P( grapheme-to-phoneme,字符到音素)转换,让模型同时适应纯文本和音素混合输入,既保留对普通文本的理解能力,又强化音素输入的泛化性;
- 定向推理流程:推理时先获取文本的完整音素序列,再通过“动态可控词典”自动识别多音字、生僻字,将其替换为指定目标音素,最后将混合音素与原文输入模型,实现精准发音控制的同时保持韵律自然。
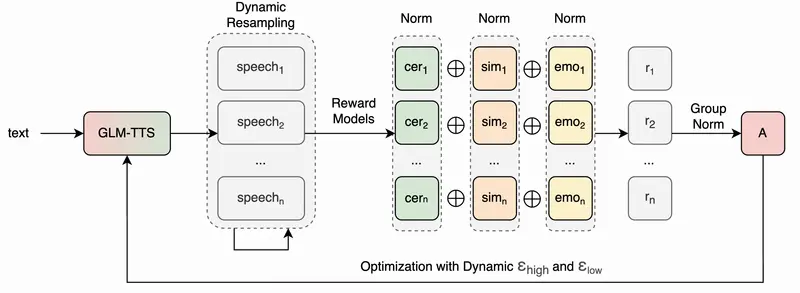
强化学习优化:多奖励机制提升情感表现力
为解决传统TTS语音“无感情、朗读感强”的问题,GLM-TTS引入多奖励强化学习框架,基于GRPO(Group Relative Policy Optimization)算法优化LLM的生成策略:
- 多维度奖励函数设计:从音质、相似度、情感表达、笑声等多个维度构建奖励函数,综合评价生成语音的质量,例如用CER(字符错误率)衡量发音准确性,用SIM指标衡量克隆语音与原声音的相似度;
- 分布式奖励服务器:通过分布式架构并行计算多个奖励函数,提升评价效率,同时支持token级别的细粒度奖励分配,让优化信号更精准;
- 策略迭代优化:基于奖励信号不断调整LLM的token生成策略,强化语音的情感色彩与韵律起伏。
实验数据显示,经过RL优化的GLM-TTS_RL版本,相比基础模型在CER指标上从1.03降至0.89,同时保持76.4的高相似度,实现了音质与表现力的双重提升。
实验结果:开源模型中性能领先,媲美商业系统
在seed-tts-eval中文测试集上的评估结果显示,GLM-TTS在开源TTS模型中表现亮眼,核心指标对标部分闭源商业系统:
| 模型 | CER(越低越好) | SIM(越高越好) | 开源状态 |
|---|---|---|---|
| MegaTTS3 | 1.52 | 79.0 | 闭源 |
| DiTAR | 1.02 | 75.3 | 闭源 |
| Seed-TTS | 1.12 | 79.6 | 闭源 |
| VoxCPM | 0.93 | 77.2 | 开源 |
| GLM-TTS(基础版) | 1.03 | 76.1 | 开源 |
| GLM-TTS_RL(优化版) | 0.89 | 76.4 | 开源 |
从数据可见,优化后的GLM-TTS_RL版本CER指标优于多数开源模型,接近闭源的MiniMax模型,同时保持了较高的语音相似度,在开源生态中具备显著竞争力。
核心组件与部署
GLM-TTS的代码架构清晰,核心组件分工明确,便于开发者二次开发与部署:
- LLM后端:
llm/glmtts.py,实现文本到语音token的生成,支持三种训练模式; - Flow模型:
flow/目录,包含Diffusion Transformer与流式推理模块,负责梅尔频谱生成; - 前端处理:
cosyvoice/cli/frontend.py,完成文本归一化、音素转换、说话人嵌入提取等预处理工作; - 强化学习模块:
grpo/目录,实现GRPO算法、多奖励函数与分布式奖励服务器。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











