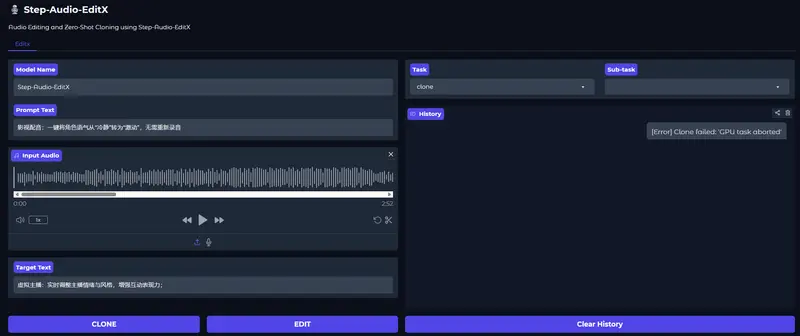
阶跃星辰(Step AI)正式发布 Step-Audio-EditX —— 一款革命性的基于大语言模型(LLM)的音频编辑系统,首次实现对语音情感、说话风格与副语言特征的高精度、迭代式、零样本控制,并支持多语言语音克隆。它标志着音频生成从“一次性合成”迈向“可编辑、可演化”的新阶段。
- 项目主页:https://stepaudiollm.github.io/step-audio-editx
- GitHub:https://github.com/stepfun-ai/Step-Audio-EditX
- 模型:https://huggingface.co/stepfun-ai/Step-Audio-EditX
- Demo:https://huggingface.co/spaces/stepfun-ai/Step-Audio-EditX
核心能力:让语音像文本一样可编辑
Step-Audio-EditX 不是另一个 TTS 模型,而是一个音频编辑器——你只需用文本指令,就能像修改 Word 文档一样修改语音:
| 编辑类型 | 支持指令示例 | 效果 |
|---|---|---|
| 情感编辑 | [Angry]、[Sad]、[Excited] | 将平静的语音转为愤怒、悲伤或兴奋,强度可迭代增强 |
| 说话风格 | [Whisper]、[Exaggerated]、[Child]、[Older] | 让语音变轻柔、夸张、童声或苍老,自然不突兀 |
| 副语言特征 | [Laughter]、[Sigh]、[Uhm]、[Surprise-ah] | 在语音中精准插入叹息、笑声、停顿、惊讶语气等人类化细节 |
| 零样本语音克隆 | “[Sichuanese] 我今天好开心” + 参考音频 | 仅需1秒参考语音,即可克隆普通话、英语、四川话、粤语等方言音色 |
💡 无需训练:所有编辑均在零样本(Zero-Shot)下完成,无需为目标音色或风格单独微调。
技术突破:大边距训练 + LLM 音频编码
Step-Audio-EditX 的核心创新在于其去耦合、数据驱动的训练范式:
| 组件 | 说明 |
|---|---|
| 双码本音频编码器 | 将语音转化为两个离散标记序列,分别编码内容与风格/情感特征 |
| 音频 LLM | 基于文本 LLM 初始化,训练于海量合成音频对,理解“如何改” |
| 流匹配解码器 | 将编辑后的标记序列还原为高质量语音波形 |
训练方法:大边距合成数据
- 不依赖人工标注或辅助模块,而是自动生成“强对比”音频对:
例:同一句话,生成“平静版”与“愤怒版”,确保差异显著(大边距); - 用评分模型筛选“最具表现力”的样本用于训练,让模型学会聚焦关键变化。

强化学习优化
- 结合人类偏好与 LLM 评分,使用 PPO 算法微调,提升复杂编辑的自然度与一致性。
性能表现:超越传统 TTS 系统
| 能力 | 表现 |
|---|---|
| 情感/风格编辑准确率 | 单次迭代提升显著,多次迭代后接近人类意图匹配 |
| 副语言控制精度 | 可在语音中精准插入笑声、叹息、犹豫词等,自然度远超传统方法 |
| 跨系统泛化能力 | 在 ElevenLabs、Doubao、MiniMax 等闭源 TTS 系统上测试,显著提升其编辑能力 |
| 方言克隆 | 四川话、粤语克隆质量媲美专业模型,仅需添加 [Sichuanese] / [Cantonese] 标签 |
✅ 在保持语音自然度的同时,编辑强度可调、可叠加、可迭代,真正实现“越改越好”。
应用场景
- 影视配音:一键将角色语气从“冷静”转为“激动”,无需重新录音;
- 虚拟主播:实时调整主播情绪与风格,增强互动表现力;
- 无障碍语音:为老年人生成“缓慢清晰”语音,为儿童生成“活泼童声”;
- AI 内容创作:为播客、有声书注入情感起伏与真实呼吸感;
- 语音助手:让 AI 语音更“像人”,减少机械感。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...