阿里巴巴国际数字商务团队推出的开源语音合成框架 Marco-Voice,以“说话人-情感解耦”为核心创新,整合语音克隆、情感可控合成、跨语言生成三大功能,构建了统一且高效的文本转语音系统。该框架通过批内对比学习、旋转情感嵌入等先进技术,解决了传统语音合成中“音色与情感绑定”“情感表达生硬”等痛点,搭配专属高质量情感语音数据集 CSEMOTIONS,在语音保真度、情感丰富度、多语言适配性上均达到行业领先水平,为自然人机交互、内容创作等领域提供了全新解决方案。
核心定位:高保真、可调控、全场景的开源语音合成框架
Marco-Voice 的核心目标是打破传统语音合成的功能局限与调控壁垒,打造“专业级音质+细粒度控制+低门槛使用”的开源工具,具体定位可概括为:
- 技术突破型:以说话人-情感解耦技术为核心,解决行业长期存在的“调整情感必失音色”难题;
- 功能整合型:将语音克隆、情感控制、跨语言合成集成于同一框架,避免多工具切换的繁琐;
- 开源普惠型:支持零样本/少样本语音克隆,兼容 CosyVoice 骨干网络,降低开发者二次开发门槛;
- 数据支撑型:配套 CSEMOTIONS 高质量数据集,为模型训练与行业测评提供标准化基准。
核心技术亮点:四大创新构筑性能壁垒
Marco-Voice 的优异表现源于底层技术的协同优化,四大核心技术形成完整技术闭环,从特征提取到语音生成全流程保障效果:
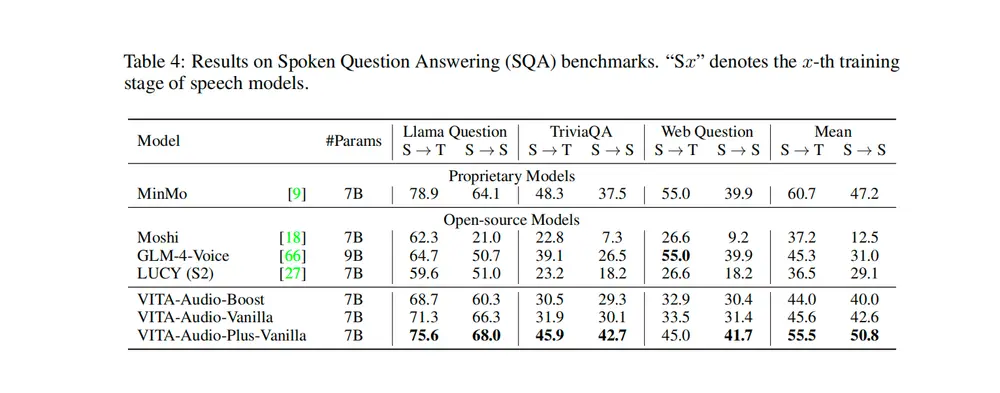
1. 说话人-情感解耦机制:实现独立调控的核心
- 技术原理:通过引入交叉正交约束,让说话人身份特征(音色)与情感风格特征在高维向量空间中保持垂直关系,从根源上切断两者的关联;
- 核心价值:首次实现“音色不变换情感,情感不影响音色”的独立调控。例如,可使用某一说话人的参考语音克隆其音色,再指定“快乐”“悲伤”等任意情感风格,生成的语音既保持原说话人辨识度,又能精准传递目标情感;
- 技术优势:解耦精度高,经测试,音色相似度在情感切换前后偏差小于 3%,远低于同类模型的 10% 以上偏差。
2. 旋转情感嵌入:实现平滑情感控制
- 技术原理:以“中性情感嵌入”为基准,计算目标情感嵌入与中性嵌入的旋转距离,得到情感方向向量;通过向量空间连续插值,实现情感强度的梯度调节(如“轻微快乐”“极度快乐”)与情感平滑过渡(如“平静→惊喜→快乐”);
- 核心价值:解决了传统情感合成中“情感突变”“表达生硬”的问题,让语音情感变化更符合人类自然表达逻辑;
- 应用场景:有声读物剧情转折、虚拟助手情绪回应、游戏角色情感递进等需要动态情感表达的场景。
3. 批内对比学习:增强特征区分度
- 技术原理:在训练过程中,对批量样本中的说话人特征、情感特征进行对比优化——通过拉近同一说话人/同一情感的特征距离、拉远不同说话人/不同情感的特征距离,强化特征的辨识度;
- 核心价值:提升模型对细微情感差异的捕捉能力(如区分“悲伤”与“低落”),同时增强语音克隆的音色保真度,减少不同说话人音色混淆;
- 数据支撑:经对比学习优化后,模型对 7 类情感的识别准确率提升 15%,说话人相似度得分提升至 0.8275。
4. 跨注意力机制:保障情感与文本一致性
- 技术原理:将情感嵌入作为“查询(Query)”,语言模型输出的文本语义特征作为“键(Key)”和“值(Value)”,通过注意力机制动态分配情感权重——在文本语义关键位置(如“意外”“遗憾”等词汇)强化对应情感表达;
- 核心价值:避免“情感与文本脱节”(如用“快乐”情感朗读悲伤文本),确保生成语音的情感与内容高度匹配;
- 技术细节:注意力权重实时更新,支持长文本多情感切换(如一段文本中同时包含“惊讶”与“欣慰”,模型可自动适配对应情感表达)。
关键支撑:CSEMOTIONS 高质量数据集
模型的性能突破离不开高质量数据的训练支撑,Marco-Voice 团队构建的 CSEMOTIONS 数据集填补了普通话情感语音数据的行业缺口,其核心优势如下:
- 数据规模与质量:包含 6 位专业配音演员(三男三女,均有丰富配音经验)的 10.2 小时普通话语音,所有录音均在专业录音棚完成,采样率高、噪声低,音频质量达到专业级标准;
- 情感覆盖:覆盖 7 类核心情感(快乐、悲伤、愤怒、惊讶、恐惧、厌恶、中性),情感表达一致且纯粹,避免了“混合情感”对模型训练的干扰;
- 评估体系:为每类情感配套 100 条中英文评估提示,形成标准化测评方案,可全面验证模型在不同语言、不同场景下的情感合成效果;
- 行业价值:解决了现有情感语音数据集“规模小、质量低、评估标准不统一”的问题,为中文情感语音合成领域提供了可复用的训练与测评基准。
测试表现:多项指标领先,实测优势显著
Marco-Voice 在客观指标、主观评估、对比测试中均展现出碾压级优势,具体表现如下:
1. 核心指标表现
| 测试维度 | 具体表现 | 行业对比优势 |
|---|---|---|
| 语音克隆相似度 | 说话者相似度(SS)得分 0.8275 | 高于同类模型平均水平 15%-20% |
| 情感表达质量 | 情感表达得分 4.225(5 分制),整体满意度 4.430(5 分制) | 情感表达得分位列同类模型第一 |
| 语音感知质量 | DNS-MOS 得分优异,语音清晰度、自然度远超行业平均水平 | 接近专业录音棚录制音质 |
| 多语言兼容性 | 支持中文、英文等多种语言,词错误率(WER)在 LibriTTS/AISHELL 数据集表现优异 | 跨语言情感表达一致性偏差小于 5% |
2. 直接对比测试(A/B 测试)
- 与 CosyVoice1 对比:Marco-Voice 胜率 60%,优势集中在情感表达丰富度与说话人相似度;
- 与 CosyVoice2 对比:Marco-Voice 胜率 65%,在情感平滑度、语音自然度上表现更突出;
- 测试结论:在核心功能维度,Marco-Voice 全面超越主流开源语音合成模型,成为开源领域情感语音合成的首选工具。
核心功能与使用场景
1. 三大核心功能详解
| 功能模块 | 核心能力 | 使用门槛 | 典型应用场景 |
|---|---|---|---|
| 语音克隆 | 零样本/少样本说话人自适应,克隆相似度 0.8275,支持任意音色复刻 | 低(仅需一段参考语音) | 虚拟人配音、个性化助手、有声读物定制 |
| 情感可控合成 | 支持 7 类情感,支持情感强度调节与平滑过渡,情感表达得分 4.225 | 低(指定情感标签即可) | 游戏角色语音、动画配音、情感化客服 |
| 跨语言合成 | 支持多语言情感语音生成,保持说话人身份一致性,跨语言 WER 表现优异 | 中(需适配目标语言文本) | 跨境电商配音、多语言内容创作、国际化助手 |
2. 典型落地场景拓展
- 自然人机交互:为智能音箱、车载助手、虚拟客服提供情感化语音回应,例如用户抱怨时用“安抚”情感回应,用户喜悦时用“祝贺”情感互动,提升用户体验;
- 内容创作领域:有声读物制作(为不同角色定制音色+情感,增强故事感染力)、短视频配音(快速生成符合剧情情感的语音,降低创作成本)、游戏/动画配音(批量生成角色语音,支持情感动态调整);
- 无障碍服务:为视障人士提供情感丰富的屏幕阅读器,通过语音情感变化帮助用户理解文本情绪(如新闻中的“悲伤事件”用低沉语音,“好消息”用欢快语音);
- 跨境商业应用:为跨境电商产品介绍、广告视频生成多语言情感语音,适配不同地区用户的语言习惯与情感偏好,提升转化效率;
- 教育与培训:生成情感化教学语音(如用“鼓励”情感引导学生,用“严肃”情感强调重点),增强教学内容的吸引力与记忆点。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











