
通义实验室近日推出 Qwen3-TTS-Flash,一款面向多场景应用的高性能文本转语音(TTS)模型。该模型现已通过 Qwen API 开放访问,支持自然、流畅且富有表现力的语音生成。
- API:https://help.aliyun.com/zh/model-studio/qwen-tts
- Demo:https://modelscope.cn/studios/Qwen/Qwen3-TTS-Demo
Qwen3-TTS-Flash 专注于解决跨语言、跨方言和复杂文本下的语音合成挑战,在稳定性、音色一致性与响应速度方面达到当前开源及公开服务中的领先水平。
核心能力概览
✅ 多音色 & 多语言统一模型
- 提供 17 种预设音色(涵盖男女声、年龄、语调差异);
- 每种音色均支持 10 种语言,包括:
- 中文(普通话及多种方言)
- 英语(美式、英式、区域口音)
- 法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语
所有语言与音色由单一模型统一生成,无需切换模型或加载额外组件,降低部署复杂度。
✅ 方言支持全面覆盖
针对中文使用者,模型原生支持以下方言语音输出:
- 普通话
- 粤语、闽南语、吴语
- 四川话、北京话、南京话、天津话、陕西话
适用于地方媒体、教育、客服机器人等需要地域化表达的场景。
✅ 高语音稳定性与音色相似度
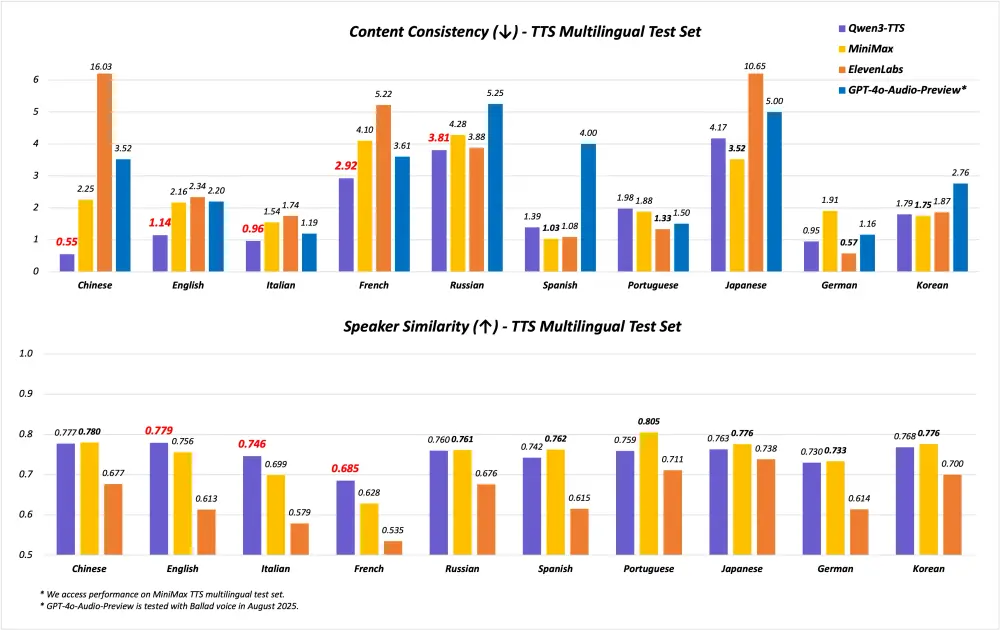
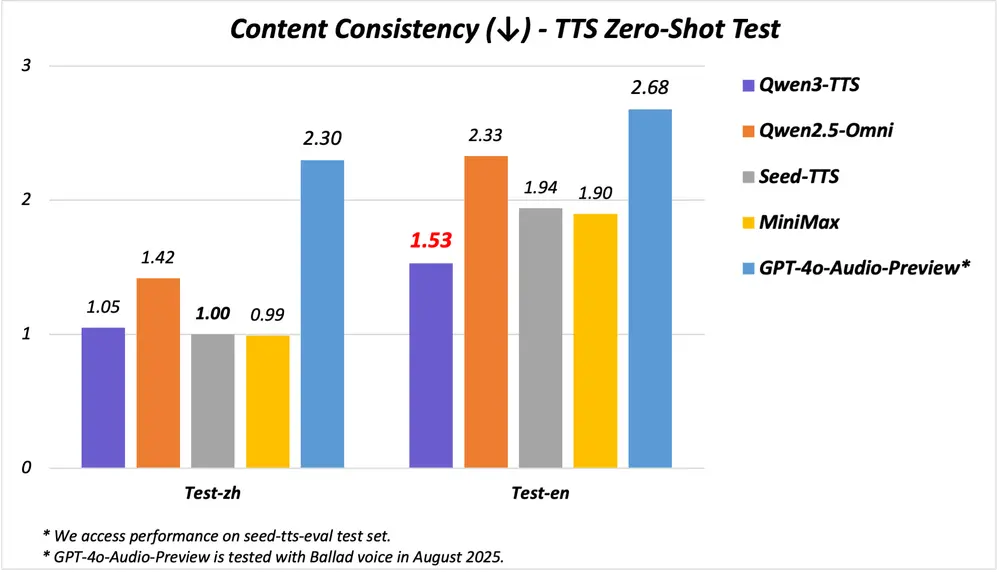
在多个权威测试集上,Qwen3-TTS-Flash 表现优于主流商业模型:
| 测试项目 | 对比结果 |
|---|---|
| 中英文稳定性 (seed-tts-eval test set) | 超越 SeedTTS、MiniMax、GPT-4o-Audio-Preview,达到 SOTA |
| 多语言 WER(词错误率) (MiniMax multilingual test set) | 中文、英文、意大利语、法语均达 SOTA,显著低于竞品 |
| 说话人相似度 (英文/意/法语) | 显著高于 MiniMax、ElevenLabs 和 GPT-4o-Audio-Preview |
这意味着语音更少出现卡顿、重复、断句错误,同时保留原始音色特征。
✅ 自动语气适配与鲁棒性处理
- 语气调节:基于上下文自动调整语调、节奏与情感倾向(如陈述、疑问、强调),无需手动标注;
- 复杂文本鲁棒性强:能正确解析包含数字、缩写、混合中英文、标点异常等多样化输入,提取关键信息并合理朗读。
例如:
“iPhone 16 Pro Max将于9月20日在天猫JD首发,限时折扣¥8,999起。”
模型可准确处理品牌名、价格符号、平台缩写,并保持语义连贯。
✅ 快速响应,低延迟输出
- 单并发下首包延迟低至 97ms;
- 支持流式输出,适合实时交互场景(如语音助手、直播字幕配音);
这一性能使其能够满足高并发、低等待的应用需求。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











